 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLithoGRPO: Fast Inverse Lithography via GRPO Reinforced Flow Matching
May 29, 2026In semiconductor manufacturing, lithography projects circuit layouts onto silicon wafers through an optical mask. As circuit features shrink below the wavelength of light, optical diffraction causes the printed patterns to deviate from their intended layouts. Inverse Lithography Technology (ILT) addresses this challenge by generating optimized masks that enhance the fidelity of pattern transfer onto wafers. While ILT resembles an image synthesis task, its reliance on explicit physical metrics for mask evaluation limits the applicability of existing generative models. We introduce LithoGRPO, an ILT framework that integrates the flow-matching paradigm with GRPO-based reinforcement learning (RL) fine-tuning, enabling efficient exploration of diverse masks for a given target layout. Unlike purely generative or optimization-based approaches, RL in LithoGRPO exploits the explicitly defined, physics-based reward function of ILT, enabling optimization under complex, process-aware constraints. To the best of our knowledge, this is the first framework that unifies flow matching and RL for mask optimization. To improve RL sampling efficiency, we propose a fast shot-counting algorithm for manufacturability evaluation, achieving over 130x speedup while preserving the mask ranking of the traditional shot-count metric. Extensive experiments demonstrate that LithoGRPO achieves state-of-the-art performance over both optimization-based and learning-based methods, while maintaining efficient mask generation.
Verilog-Evolve: Feedback-Driven and Skill-Evolving Verilog Generation
May 26, 2026Large language models (LLMs) have improved Verilog generation from natural-language specifications, but most pipelines still treat generation as isolated sampling followed by functional checking. This is insufficient for practical RTL design, where useful Verilog must be correct, synthesizable, timing-conscious, and friendly to downstream hardware objectives. We present Verilog-Evolve, a feedback-driven framework for versioned Verilog refinement and cross-session skill evolution. For each task, Verilog-Evolve generates diverse minor candidates, evaluates them with executable feedback from functional simulation, Yosys synthesis, ABC timing proxy, and optional GEMM metrics, then promotes the best candidate into a major version under configurable scoring. To improve across tasks, the system maintains modular skill guidance, retrieves skills according to task and feedback context, and evolves candidate skills from logged histories through create/improve/skip decisions and verifier reports. Experiments on VerilogEval and mixed-precision GEMM tasks show that Verilog-Evolve improves final functional success and promotion stability while producing more downstream-friendly RTL under open-source synthesis, timing-proxy, and netlist-level GEMM objectives. Validation-gated skill evolution further improves GEMM downstream quality and achieves the best downstream score and GEMM held-out pass rate among the evaluated skill modes.
FocuSFT: Bilevel Optimization for Dilution-Aware Long-Context Fine-Tuning
May 11, 2026Large language models can now process increasingly long inputs, yet their ability to effectively use information spread across long contexts remains limited. We trace this gap to how attention budget is spent during supervised fine-tuning (SFT) on long sequences: positional biases and attention sinks cause the model to allocate most of its attention to positionally privileged tokens rather than semantically relevant content. This training-time attention dilution (the starvation of content tokens in the attention distribution) weakens the gradient signal, limiting the model's ability to learn robust long-context capabilities. We introduce FocuSFT, a bilevel optimization framework that addresses this problem at training time. An inner loop adapts lightweight fast-weight parameters on the training context to form a parametric memory that concentrates attention on relevant content, and the outer loop performs SFT conditioned on this sharpened representation. Both loops apply bidirectional attention over context tokens while preserving causal masking for responses, reducing the causal asymmetry that gives rise to attention sinks and aligning inner-outer behavior. On BABILong, FocuSFT improves accuracy by up to +14pp across 4K--32K context lengths; on RULER, it raises CWE aggregation from 72.9\% to 81.1\% at 16K; and on GPQA with agentic tool use, it yields a 24\% relative gain in pass@1. Attention analysis shows that FocuSFT reduces attention sink mass by 529$\times$ and triples context engagement during training. Code: https://github.com/JarvisPei/FocuSFT
KCLNet: Electrically Equivalence-Oriented Graph Representation Learning for Analog Circuits
Mar 25, 2026Digital circuits representation learning has made remarkable progress in the electronic design automation domain, effectively supporting critical tasks such as testability analysis and logic reasoning. However, representation learning for analog circuits remains challenging due to their continuous electrical characteristics compared to the discrete states of digital circuits. This paper presents a direct current (DC) electrically equivalent-oriented analog representation learning framework, named \textbf{KCLNet}. It comprises an asynchronous graph neural network structure with electrically-simulated message passing and a representation learning method inspired by Kirchhoff's Current Law (KCL). This method maintains the orderliness of the circuit embedding space by enforcing the equality of the sum of outgoing and incoming current embeddings at each depth, which significantly enhances the generalization ability of circuit embeddings. KCLNet offers a novel and effective solution for analog circuit representation learning with electrical constraints preserved. Experimental results demonstrate that our method achieves significant performance in a variety of downstream tasks, e.g., analog circuit classification, subcircuit detection, and circuit edit distance prediction.
MemDLM: Memory-Enhanced DLM Training
Mar 23, 2026Diffusion Language Models (DLMs) offer attractive advantages over Auto-Regressive (AR) models, such as full-attention parallel decoding and flexible generation. However, they suffer from a notable train-inference mismatch: DLMs are trained with a static, single-step masked prediction objective, but deployed through a multi-step progressive denoising trajectory. We propose MemDLM (Memory-Enhanced DLM), which narrows this gap by embedding a simulated denoising process into training via Bi-level Optimization. An inner loop updates a set of fast weights, forming a Parametric Memory that captures the local trajectory experience of each sample, while an outer loop updates the base model conditioned on this memory. By offloading memorization pressure from token representations to parameters, MemDLM yields faster convergence and lower training loss. Moreover, the inner loop can be re-enabled at inference time as an adaptation step, yielding additional gains on long-context understanding. We find that, when activated at inference time, this Parametric Memory acts as an emergent in-weight retrieval mechanism, helping MemDLM further reduce token-level attention bottlenecks on challenging Needle-in-a-Haystack retrieval tasks. Code: https://github.com/JarvisPei/MemDLM.
Low-Light Video Enhancement with An Effective Spatial-Temporal Decomposition Paradigm
Feb 09, 2026Low-Light Video Enhancement (LLVE) seeks to restore dynamic or static scenes plagued by severe invisibility and noise. In this paper, we present an innovative video decomposition strategy that incorporates view-independent and view-dependent components to enhance the performance of LLVE. The framework is called View-aware Low-light Video Enhancement (VLLVE). We leverage dynamic cross-frame correspondences for the view-independent term (which primarily captures intrinsic appearance) and impose a scene-level continuity constraint on the view-dependent term (which mainly describes the shading condition) to achieve consistent and satisfactory decomposition results. To further ensure consistent decomposition, we introduce a dual-structure enhancement network featuring a cross-frame interaction mechanism. By supervising different frames simultaneously, this network encourages them to exhibit matching decomposition features. This mechanism can seamlessly integrate with encoder-decoder single-frame networks, incurring minimal additional parameter costs. Building upon VLLVE, we propose a more comprehensive decomposition strategy by introducing an additive residual term, resulting in VLLVE++. This residual term can simulate scene-adaptive degradations, which are difficult to model using a decomposition formulation for common scenes, thereby further enhancing the ability to capture the overall content of videos. In addition, VLLVE++ enables bidirectional learning for both enhancement and degradation-aware correspondence refinement (end-to-end manner), effectively increasing reliable correspondences while filtering out incorrect ones. Notably, VLLVE++ demonstrates strong capability in handling challenging cases, such as real-world scenes and videos with high dynamics. Extensive experiments are conducted on widely recognized LLVE benchmarks.
Diversity or Precision? A Deep Dive into Next Token Prediction
Dec 28, 2025Recent advancements have shown that reinforcement learning (RL) can substantially improve the reasoning abilities of large language models (LLMs). The effectiveness of such RL training, however, depends critically on the exploration space defined by the pre-trained model's token-output distribution. In this paper, we revisit the standard cross-entropy loss, interpreting it as a specific instance of policy gradient optimization applied within a single-step episode. To systematically study how the pre-trained distribution shapes the exploration potential for subsequent RL, we propose a generalized pre-training objective that adapts on-policy RL principles to supervised learning. By framing next-token prediction as a stochastic decision process, we introduce a reward-shaping strategy that explicitly balances diversity and precision. Our method employs a positive reward scaling factor to control probability concentration on ground-truth tokens and a rank-aware mechanism that treats high-ranking and low-ranking negative tokens asymmetrically. This allows us to reshape the pre-trained token-output distribution and investigate how to provide a more favorable exploration space for RL, ultimately enhancing end-to-end reasoning performance. Contrary to the intuition that higher distribution entropy facilitates effective exploration, we find that imposing a precision-oriented prior yields a superior exploration space for RL.
DreamOmni3: Scribble-based Editing and Generation
Dec 27, 2025Recently unified generation and editing models have achieved remarkable success with their impressive performance. These models rely mainly on text prompts for instruction-based editing and generation, but language often fails to capture users intended edit locations and fine-grained visual details. To this end, we propose two tasks: scribble-based editing and generation, that enables more flexible creation on graphical user interface (GUI) combining user textual, images, and freehand sketches. We introduce DreamOmni3, tackling two challenges: data creation and framework design. Our data synthesis pipeline includes two parts: scribble-based editing and generation. For scribble-based editing, we define four tasks: scribble and instruction-based editing, scribble and multimodal instruction-based editing, image fusion, and doodle editing. Based on DreamOmni2 dataset, we extract editable regions and overlay hand-drawn boxes, circles, doodles or cropped image to construct training data. For scribble-based generation, we define three tasks: scribble and instruction-based generation, scribble and multimodal instruction-based generation, and doodle generation, following similar data creation pipelines. For the framework, instead of using binary masks, which struggle with complex edits involving multiple scribbles, images, and instructions, we propose a joint input scheme that feeds both the original and scribbled source images into the model, using different colors to distinguish regions and simplify processing. By applying the same index and position encodings to both images, the model can precisely localize scribbled regions while maintaining accurate editing. Finally, we establish comprehensive benchmarks for these tasks to promote further research. Experimental results demonstrate that DreamOmni3 achieves outstanding performance, and models and code will be publicly released.
RePlan: Reasoning-guided Region Planning for Complex Instruction-based Image Editing
Dec 18, 2025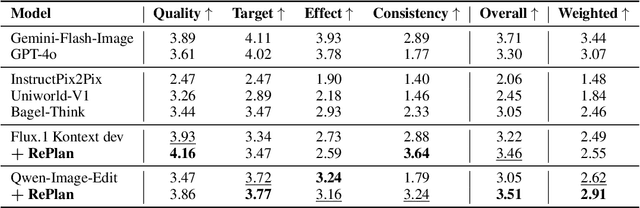
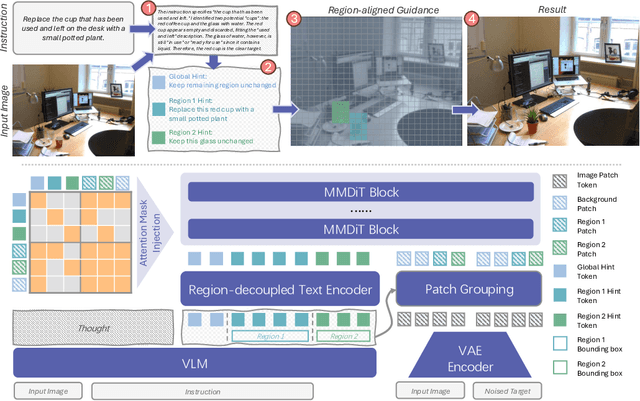

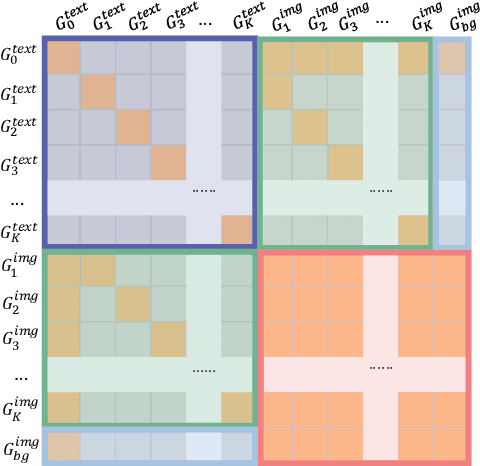
Instruction-based image editing enables natural-language control over visual modifications, yet existing models falter under Instruction-Visual Complexity (IV-Complexity), where intricate instructions meet cluttered or ambiguous scenes. We introduce RePlan (Region-aligned Planning), a plan-then-execute framework that couples a vision-language planner with a diffusion editor. The planner decomposes instructions via step-by-step reasoning and explicitly grounds them to target regions; the editor then applies changes using a training-free attention-region injection mechanism, enabling precise, parallel multi-region edits without iterative inpainting. To strengthen planning, we apply GRPO-based reinforcement learning using 1K instruction-only examples, yielding substantial gains in reasoning fidelity and format reliability. We further present IV-Edit, a benchmark focused on fine-grained grounding and knowledge-intensive edits. Across IV-Complex settings, RePlan consistently outperforms strong baselines trained on far larger datasets, improving regional precision and overall fidelity. Our project page: https://replan-iv-edit.github.io
SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Dec 17, 2025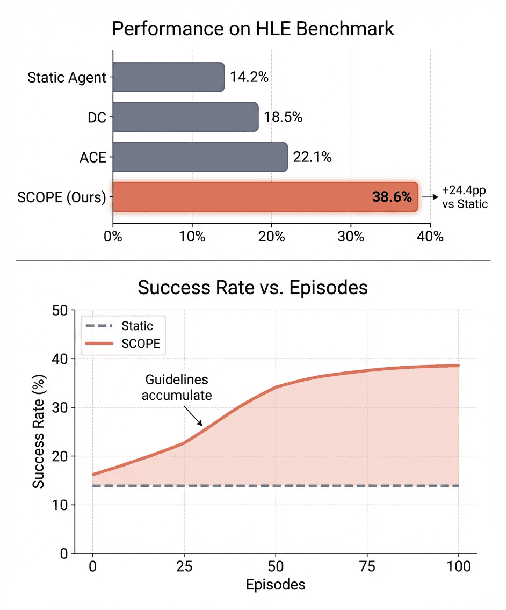
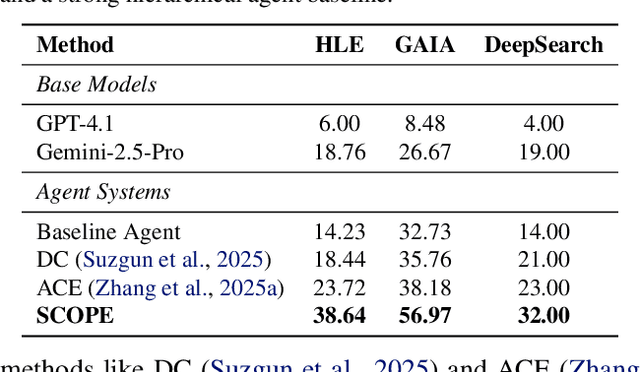
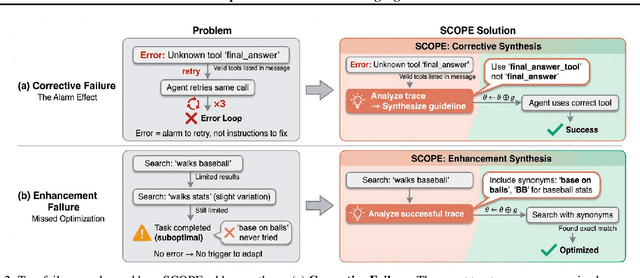
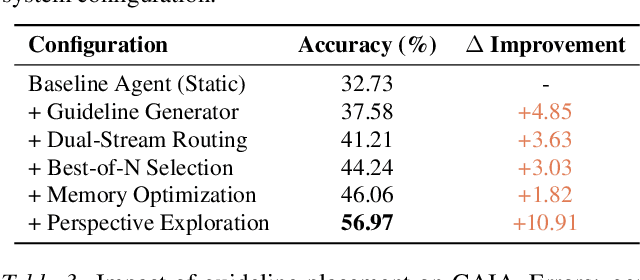
Large Language Model (LLM) agents are increasingly deployed in environments that generate massive, dynamic contexts. However, a critical bottleneck remains: while agents have access to this context, their static prompts lack the mechanisms to manage it effectively, leading to recurring Corrective and Enhancement failures. To address this capability gap, we introduce \textbf{SCOPE} (Self-evolving Context Optimization via Prompt Evolution). SCOPE frames context management as an \textit{online optimization} problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt. We propose a Dual-Stream mechanism that balances tactical specificity (resolving immediate errors) with strategic generality (evolving long-term principles). Furthermore, we introduce Perspective-Driven Exploration to maximize strategy coverage, increasing the likelihood that the agent has the correct strategy for any given task. Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention. We make our code publicly available at https://github.com/JarvisPei/SCOPE.