 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Sink in Transformers: A Survey on Utilization, Interpretation, and Mitigation
Apr 11, 2026As the foundational architecture of modern machine learning, Transformers have driven remarkable progress across diverse AI domains. Despite their transformative impact, a persistent challenge across various Transformers is Attention Sink (AS), in which a disproportionate amount of attention is focused on a small subset of specific yet uninformative tokens. AS complicates interpretability, significantly affecting the training and inference dynamics, and exacerbates issues such as hallucinations. In recent years, substantial research has been dedicated to understanding and harnessing AS. However, a comprehensive survey that systematically consolidates AS-related research and offers guidance for future advancements remains lacking. To address this gap, we present the first survey on AS, structured around three key dimensions that define the current research landscape: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation. Our work provides a pivotal contribution by clarifying key concepts and guiding researchers through the evolution and trends of the field. We envision this survey as a definitive resource, empowering researchers and practitioners to effectively manage AS within the current Transformer paradigm, while simultaneously inspiring innovative advancements for the next generation of Transformers. The paper list of this work is available at https://github.com/ZunhaiSu/Awesome-Attention-Sink.
Beyond Outliers: A Data-Free Layer-wise Mixed-Precision Quantization Approach Driven by Numerical and Structural Dual-Sensitivity
Mar 18, 2026Layer-wise mixed-precision quantization (LMPQ) enables effective compression under extreme low-bit settings by allocating higher precision to sensitive layers. However, existing methods typically treat all intra-layer weight modules uniformly and rely on a single numerical property when estimating sensitivity, overlooking their distinct operational roles and structural characteristics. To address this, we propose NSDS, a novel calibration-free LMPQ framework driven by Numerical and Structural Dual-Sensitivity. Specifically, it first mechanistically decomposes each layer into distinct operational roles and quantifies their sensitivity from both numerical and structural perspectives. These dual-aspect scores are then aggregated into a unified layer-wise metric through a robust aggregation scheme based on MAD-Sigmoid and Soft-OR to guide bit allocation. Extensive experiments demonstrate that NSDS consistently achieves superior performance compared to various baselines across diverse models and downstream tasks, without relying on any calibration data.
BPDQ: Bit-Plane Decomposition Quantization on a Variable Grid for Large Language Models
Feb 04, 2026Large language model (LLM) inference is often bounded by memory footprint and memory bandwidth in resource-constrained deployments, making quantization a fundamental technique for efficient serving. While post-training quantization (PTQ) maintains high fidelity at 4-bit, it deteriorates at 2-3 bits. Fundamentally, existing methods enforce a shape-invariant quantization grid (e.g., the fixed uniform intervals of UINT2) for each group, severely restricting the feasible set for error minimization. To address this, we propose Bit-Plane Decomposition Quantization (BPDQ), which constructs a variable quantization grid via bit-planes and scalar coefficients, and iteratively refines them using approximate second-order information while progressively compensating quantization errors to minimize output discrepancy. In the 2-bit regime, BPDQ enables serving Qwen2.5-72B on a single RTX 3090 with 83.85% GSM8K accuracy (vs. 90.83% at 16-bit). Moreover, we provide theoretical analysis showing that the variable grid expands the feasible set, and that the quantization process consistently aligns with the optimization objective in Hessian-induced geometry. Code: github.com/KingdalfGoodman/BPDQ.
SwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
May 29, 2025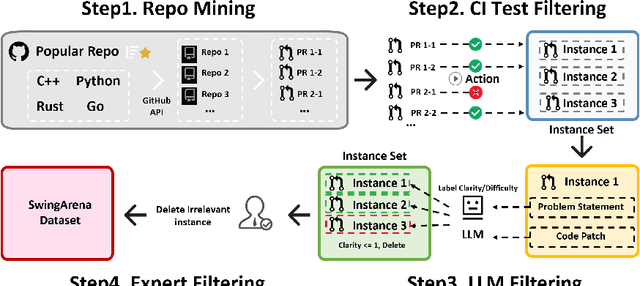
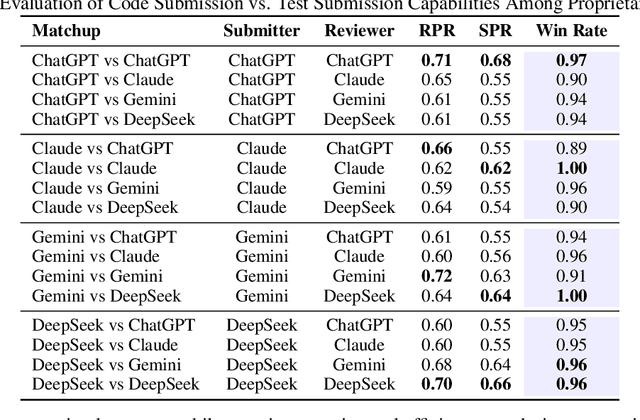
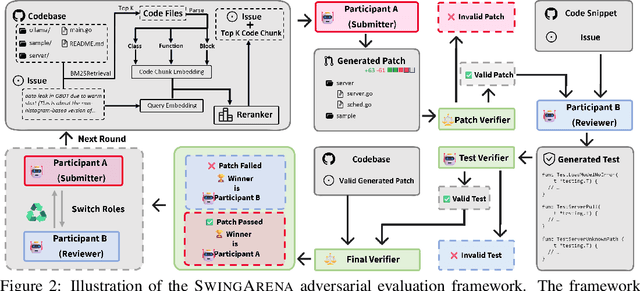
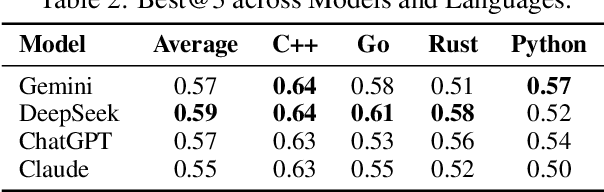
We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io
NVR: Vector Runahead on NPUs for Sparse Memory Access
Feb 19, 2025Deep Neural Networks are increasingly leveraging sparsity to reduce the scaling up of model parameter size. However, reducing wall-clock time through sparsity and pruning remains challenging due to irregular memory access patterns, leading to frequent cache misses. In this paper, we present NPU Vector Runahead (NVR), a prefetching mechanism tailored for NPUs to address cache miss problems in sparse DNN workloads. Rather than optimising memory patterns with high overhead and poor portability, NVR adapts runahead execution to the unique architecture of NPUs. NVR provides a general micro-architectural solution for sparse DNN workloads without requiring compiler or algorithmic support, operating as a decoupled, speculative, lightweight hardware sub-thread alongside the NPU, with minimal hardware overhead (under 5%). NVR achieves an average 90% reduction in cache misses compared to SOTA prefetching in general-purpose processors, delivering 4x average speedup on sparse workloads versus NPUs without prefetching. Moreover, we investigate the advantages of incorporating a small cache (16KB) into the NPU combined with NVR. Our evaluation shows that expanding this modest cache delivers 5x higher performance benefits than increasing the L2 cache size by the same amount.