 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMFormalizer: Multimodal Autoformalization in the Wild
Jan 06, 2026Autoformalization, which translates natural language mathematics into formal statements to enable machine reasoning, faces fundamental challenges in the wild due to the multimodal nature of the physical world, where physics requires inferring hidden constraints (e.g., mass or energy) from visual elements. To address this, we propose MMFormalizer, which extends autoformalization beyond text by integrating adaptive grounding with entities from real-world mathematical and physical domains. MMFormalizer recursively constructs formal propositions from perceptually grounded primitives through recursive grounding and axiom composition, with adaptive recursive termination ensuring that every abstraction is supported by visual evidence and anchored in dimensional or axiomatic grounding. We evaluate MMFormalizer on a new benchmark, PhyX-AF, comprising 115 curated samples from MathVerse, PhyX, Synthetic Geometry, and Analytic Geometry, covering diverse multimodal autoformalization tasks. Results show that frontier models such as GPT-5 and Gemini-3-Pro achieve the highest compile and semantic accuracy, with GPT-5 excelling in physical reasoning, while geometry remains the most challenging domain. Overall, MMFormalizer provides a scalable framework for unified multimodal autoformalization, bridging perception and formal reasoning. To the best of our knowledge, this is the first multimodal autoformalization method capable of handling classical mechanics (derived from the Hamiltonian), as well as relativity, quantum mechanics, and thermodynamics. More details are available on our project page: MMFormalizer.github.io
ScienceDB AI: An LLM-Driven Agentic Recommender System for Large-Scale Scientific Data Sharing Services
Jan 03, 2026The rapid growth of AI for Science (AI4S) has underscored the significance of scientific datasets, leading to the establishment of numerous national scientific data centers and sharing platforms. Despite this progress, efficiently promoting dataset sharing and utilization for scientific research remains challenging. Scientific datasets contain intricate domain-specific knowledge and contexts, rendering traditional collaborative filtering-based recommenders inadequate. Recent advances in Large Language Models (LLMs) offer unprecedented opportunities to build conversational agents capable of deep semantic understanding and personalized recommendations. In response, we present ScienceDB AI, a novel LLM-driven agentic recommender system developed on Science Data Bank (ScienceDB), one of the largest global scientific data-sharing platforms. ScienceDB AI leverages natural language conversations and deep reasoning to accurately recommend datasets aligned with researchers' scientific intents and evolving requirements. The system introduces several innovations: a Scientific Intention Perceptor to extract structured experimental elements from complicated queries, a Structured Memory Compressor to manage multi-turn dialogues effectively, and a Trustworthy Retrieval-Augmented Generation (Trustworthy RAG) framework. The Trustworthy RAG employs a two-stage retrieval mechanism and provides citable dataset references via Citable Scientific Task Record (CSTR) identifiers, enhancing recommendation trustworthiness and reproducibility. Through extensive offline and online experiments using over 10 million real-world datasets, ScienceDB AI has demonstrated significant effectiveness. To our knowledge, ScienceDB AI is the first LLM-driven conversational recommender tailored explicitly for large-scale scientific dataset sharing services. The platform is publicly accessible at: https://ai.scidb.cn/en.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025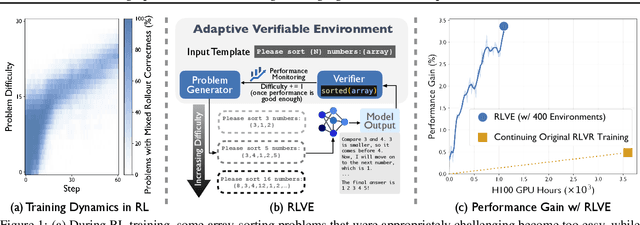

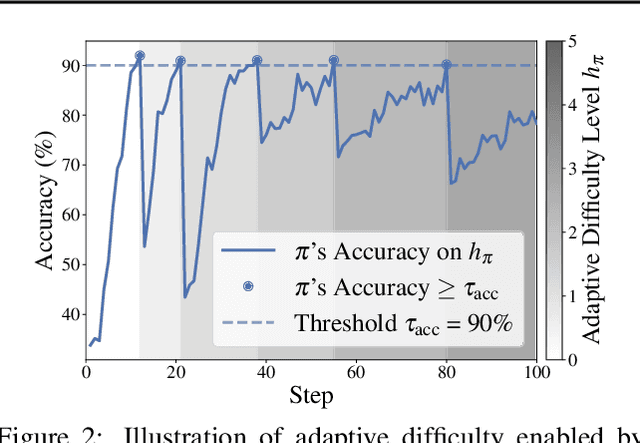
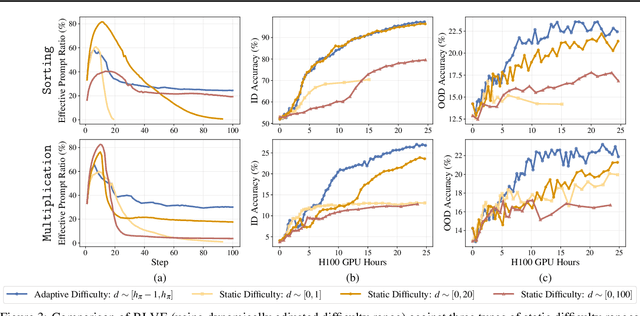
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Object-IR: Leveraging Object Consistency and Mesh Deformation for Self-Supervised Image Retargeting
Oct 31, 2025Eliminating geometric distortion in semantically important regions remains an intractable challenge in image retargeting. This paper presents Object-IR, a self-supervised architecture that reformulates image retargeting as a learning-based mesh warping optimization problem, where the mesh deformation is guided by object appearance consistency and geometric-preserving constraints. Given an input image and a target aspect ratio, we initialize a uniform rigid mesh at the output resolution and use a convolutional neural network to predict the motion of each mesh grid and obtain the deformed mesh. The retargeted result is generated by warping the input image according to the rigid mesh in the input image and the deformed mesh in the output resolution. To mitigate geometric distortion, we design a comprehensive objective function incorporating a) object-consistent loss to ensure that the important semantic objects retain their appearance, b) geometric-preserving loss to constrain simple scale transform of the important meshes, and c) boundary loss to enforce a clean rectangular output. Notably, our self-supervised paradigm eliminates the need for manually annotated retargeting datasets by deriving supervision directly from the input's geometric and semantic properties. Extensive evaluations on the RetargetMe benchmark demonstrate that our Object-IR achieves state-of-the-art performance, outperforming existing methods in quantitative metrics and subjective visual quality assessments. The framework efficiently processes arbitrary input resolutions (average inference time: 0.009s for 1024x683 resolution) while maintaining real-time performance on consumer-grade GPUs. The source code will soon be available at https://github.com/tlliao/Object-IR.
A1: Asynchronous Test-Time Scaling via Conformal Prediction
Sep 18, 2025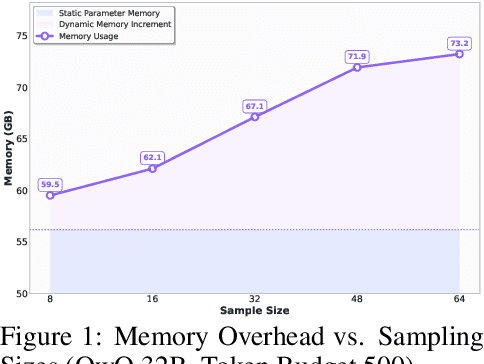
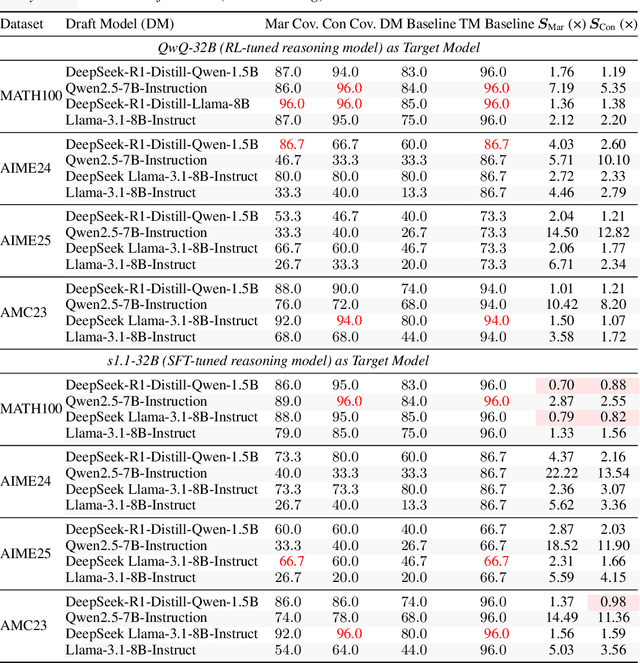
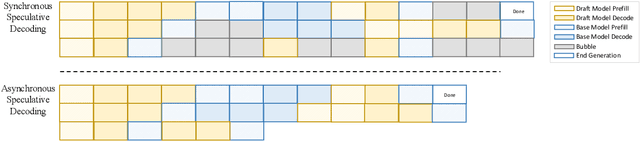
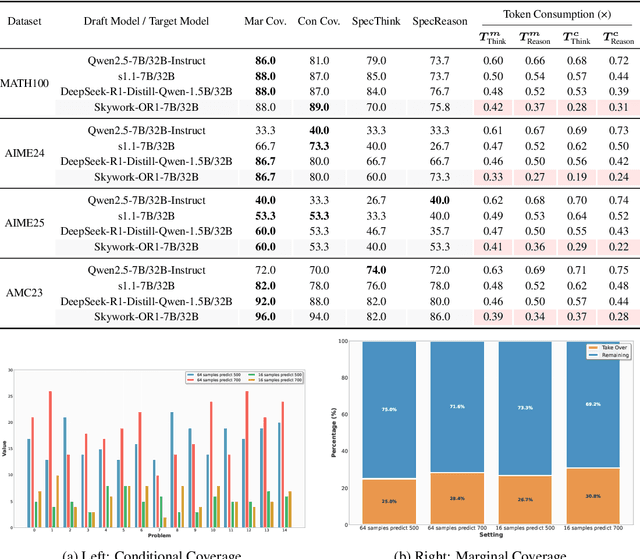
Large language models (LLMs) benefit from test-time scaling, but existing methods face significant challenges, including severe synchronization overhead, memory bottlenecks, and latency, especially during speculative decoding with long reasoning chains. We introduce A1 (Asynchronous Test-Time Scaling), a statistically guaranteed adaptive inference framework that addresses these challenges. A1 refines arithmetic intensity to identify synchronization as the dominant bottleneck, proposes an online calibration strategy to enable asynchronous inference, and designs a three-stage rejection sampling pipeline that supports both sequential and parallel scaling. Through experiments on the MATH, AMC23, AIME24, and AIME25 datasets, across various draft-target model families, we demonstrate that A1 achieves a remarkable 56.7x speedup in test-time scaling and a 4.14x improvement in throughput, all while maintaining accurate rejection-rate control, reducing latency and memory overhead, and no accuracy loss compared to using target model scaling alone. These results position A1 as an efficient and principled solution for scalable LLM inference. We have released the code at https://github.com/menik1126/asynchronous-test-time-scaling.
LongEmotion: Measuring Emotional Intelligence of Large Language Models in Long-Context Interaction
Sep 09, 2025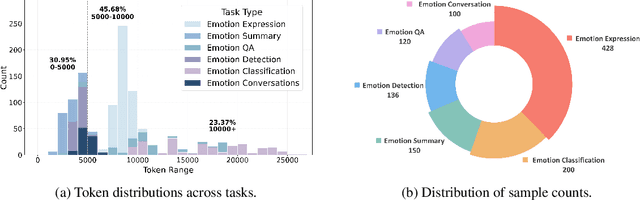

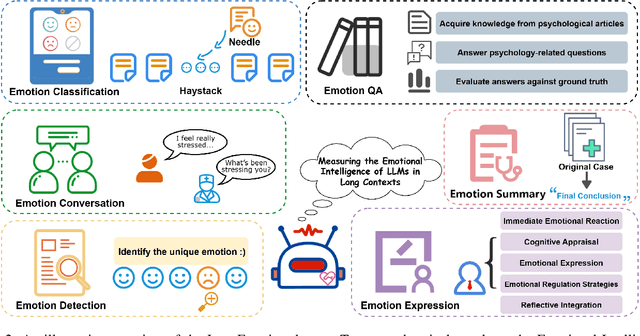
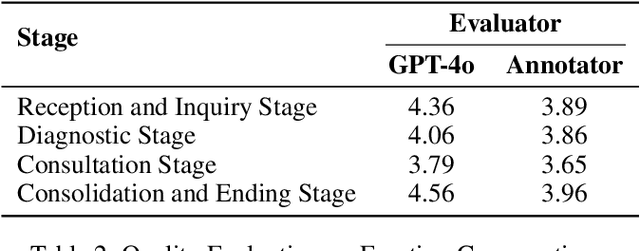
Large language models (LLMs) make significant progress in Emotional Intelligence (EI) and long-context understanding. However, existing benchmarks tend to overlook certain aspects of EI in long-context scenarios, especially under realistic, practical settings where interactions are lengthy, diverse, and often noisy. To move towards such realistic settings, we present LongEmotion, a benchmark specifically designed for long-context EI tasks. It covers a diverse set of tasks, including Emotion Classification, Emotion Detection, Emotion QA, Emotion Conversation, Emotion Summary, and Emotion Expression. On average, the input length for these tasks reaches 8,777 tokens, with long-form generation required for Emotion Expression. To enhance performance under realistic constraints, we incorporate Retrieval-Augmented Generation (RAG) and Collaborative Emotional Modeling (CoEM), and compare them with standard prompt-based methods. Unlike conventional approaches, our RAG method leverages both the conversation context and the large language model itself as retrieval sources, avoiding reliance on external knowledge bases. The CoEM method further improves performance by decomposing the task into five stages, integrating both retrieval augmentation and limited knowledge injection. Experimental results show that both RAG and CoEM consistently enhance EI-related performance across most long-context tasks, advancing LLMs toward more practical and real-world EI applications. Furthermore, we conducted a comparative case study experiment on the GPT series to demonstrate the differences among various models in terms of EI. Code is available on GitHub at https://github.com/LongEmotion/LongEmotion, and the project page can be found at https://longemotion.github.io/.
SwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
May 29, 2025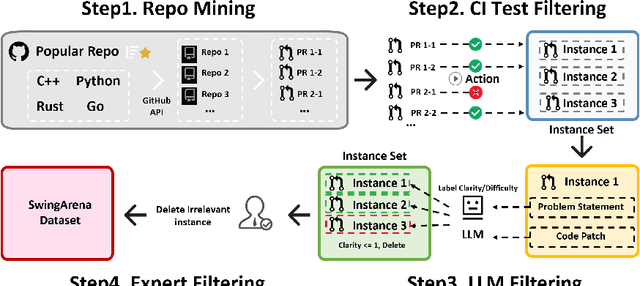
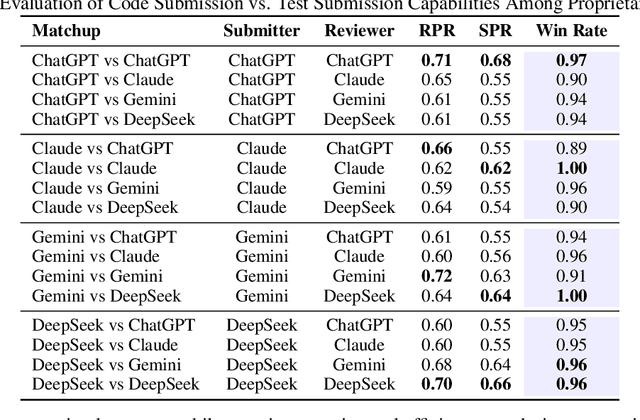
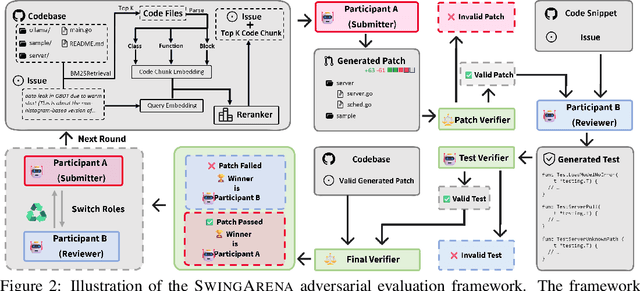
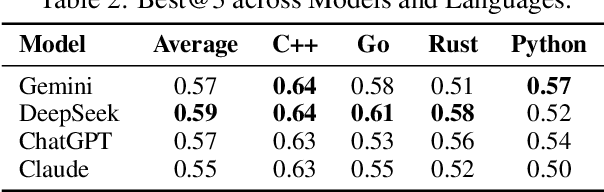
We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io
Point-to-Region Loss for Semi-Supervised Point-Based Crowd Counting
May 28, 2025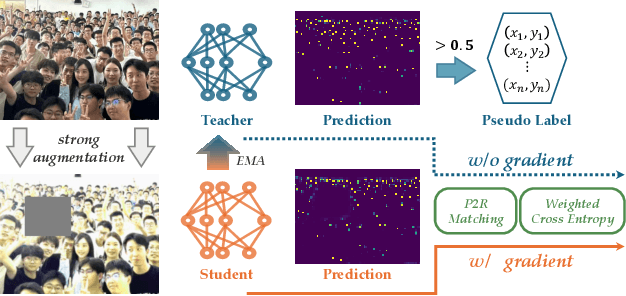
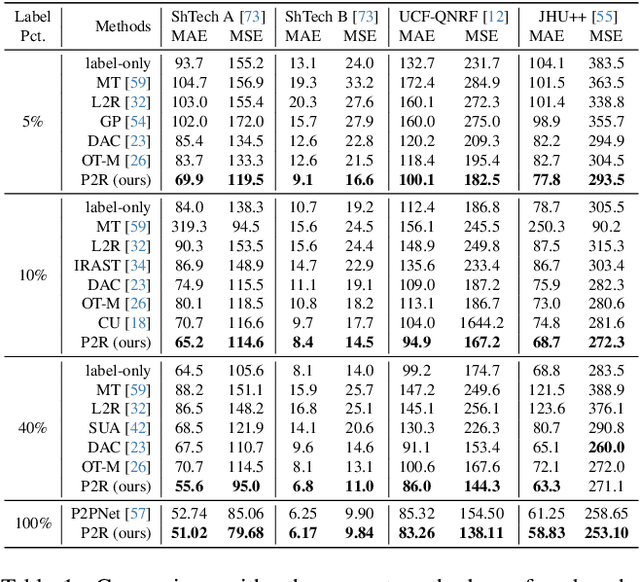
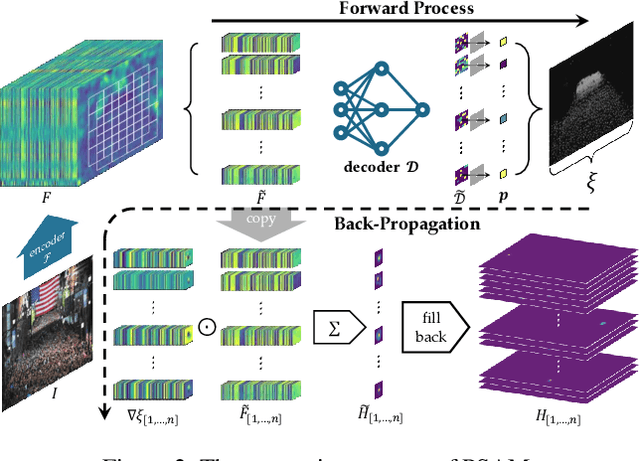
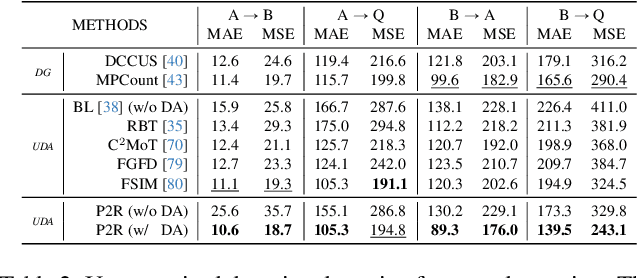
Point detection has been developed to locate pedestrians in crowded scenes by training a counter through a point-to-point (P2P) supervision scheme. Despite its excellent localization and counting performance, training a point-based counter still faces challenges concerning annotation labor: hundreds to thousands of points are required to annotate a single sample capturing a dense crowd. In this paper, we integrate point-based methods into a semi-supervised counting framework based on pseudo-labeling, enabling the training of a counter with only a few annotated samples supplemented by a large volume of pseudo-labeled data. However, during implementation, the training encounters issues as the confidence for pseudo-labels fails to be propagated to background pixels via the P2P. To tackle this challenge, we devise a point-specific activation map (PSAM) to visually interpret the phenomena occurring during the ill-posed training. Observations from the PSAM suggest that the feature map is excessively activated by the loss for unlabeled data, causing the decoder to misinterpret these over-activations as pedestrians. To mitigate this issue, we propose a point-to-region (P2R) scheme to substitute P2P, which segments out local regions rather than detects a point corresponding to a pedestrian for supervision. Consequently, pixels in the local region can share the same confidence with the corresponding pseudo points. Experimental results in both semi-supervised counting and unsupervised domain adaptation highlight the advantages of our method, illustrating P2R can resolve issues identified in PSAM. The code is available at https://github.com/Elin24/P2RLoss.
Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
May 21, 2025Human cognition typically involves thinking through abstract, fluid concepts rather than strictly using discrete linguistic tokens. Current reasoning models, however, are constrained to reasoning within the boundaries of human language, processing discrete token embeddings that represent fixed points in the semantic space. This discrete constraint restricts the expressive power and upper potential of such reasoning models, often causing incomplete exploration of reasoning paths, as standard Chain-of-Thought (CoT) methods rely on sampling one token per step. In this work, we introduce Soft Thinking, a training-free method that emulates human-like "soft" reasoning by generating soft, abstract concept tokens in a continuous concept space. These concept tokens are created by the probability-weighted mixture of token embeddings, which form the continuous concept space, enabling smooth transitions and richer representations that transcend traditional discrete boundaries. In essence, each generated concept token encapsulates multiple meanings from related discrete tokens, implicitly exploring various reasoning paths to converge effectively toward the correct answer. Empirical evaluations on diverse mathematical and coding benchmarks consistently demonstrate the effectiveness and efficiency of Soft Thinking, improving pass@1 accuracy by up to 2.48 points while simultaneously reducing token usage by up to 22.4% compared to standard CoT. Qualitative analysis further reveals that Soft Thinking outputs remain highly interpretable and readable, highlighting the potential of Soft Thinking to break the inherent bottleneck of discrete language-based reasoning. Code is available at https://github.com/eric-ai-lab/Soft-Thinking.
Density-based Object Detection in Crowded Scenes
Apr 14, 2025Compared with the generic scenes, crowded scenes contain highly-overlapped instances, which result in: 1) more ambiguous anchors during training of object detectors, and 2) more predictions are likely to be mistakenly suppressed in post-processing during inference. To address these problems, we propose two new strategies, density-guided anchors (DGA) and density-guided NMS (DG-NMS), which uses object density maps to jointly compute optimal anchor assignments and reweighing, as well as an adaptive NMS. Concretely, based on an unbalanced optimal transport (UOT) problem, the density owned by each ground-truth object is transported to each anchor position at a minimal transport cost. And density on anchors comprises an instance-specific density distribution, from which DGA decodes the optimal anchor assignment and re-weighting strategy. Meanwhile, DG-NMS utilizes the predicted density map to adaptively adjust the NMS threshold to reduce mistaken suppressions. In the UOT, a novel overlap-aware transport cost is specifically designed for ambiguous anchors caused by overlapped neighboring objects. Extensive experiments on the challenging CrowdHuman dataset with Citypersons dataset demonstrate that our proposed density-guided detector is effective and robust to crowdedness. The code and pre-trained models will be made available later.