 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenProber: Jailbreaking Text-to-image Models via Fine-grained Word Impact Analysis
May 11, 2025Text-to-image (T2I) models have significantly advanced in producing high-quality images. However, such models have the ability to generate images containing not-safe-for-work (NSFW) content, such as pornography, violence, political content, and discrimination. To mitigate the risk of generating NSFW content, refusal mechanisms, i.e., safety checkers, have been developed to check potential NSFW content. Adversarial prompting techniques have been developed to evaluate the robustness of the refusal mechanisms. The key challenge remains to subtly modify the prompt in a way that preserves its sensitive nature while bypassing the refusal mechanisms. In this paper, we introduce TokenProber, a method designed for sensitivity-aware differential testing, aimed at evaluating the robustness of the refusal mechanisms in T2I models by generating adversarial prompts. Our approach is based on the key observation that adversarial prompts often succeed by exploiting discrepancies in how T2I models and safety checkers interpret sensitive content. Thus, we conduct a fine-grained analysis of the impact of specific words within prompts, distinguishing between dirty words that are essential for NSFW content generation and discrepant words that highlight the different sensitivity assessments between T2I models and safety checkers. Through the sensitivity-aware mutation, TokenProber generates adversarial prompts, striking a balance between maintaining NSFW content generation and evading detection. Our evaluation of TokenProber against 5 safety checkers on 3 popular T2I models, using 324 NSFW prompts, demonstrates its superior effectiveness in bypassing safety filters compared to existing methods (e.g., 54%+ increase on average), highlighting TokenProber's ability to uncover robustness issues in the existing refusal mechanisms.
Revisiting Training-Inference Trigger Intensity in Backdoor Attacks
Mar 15, 2025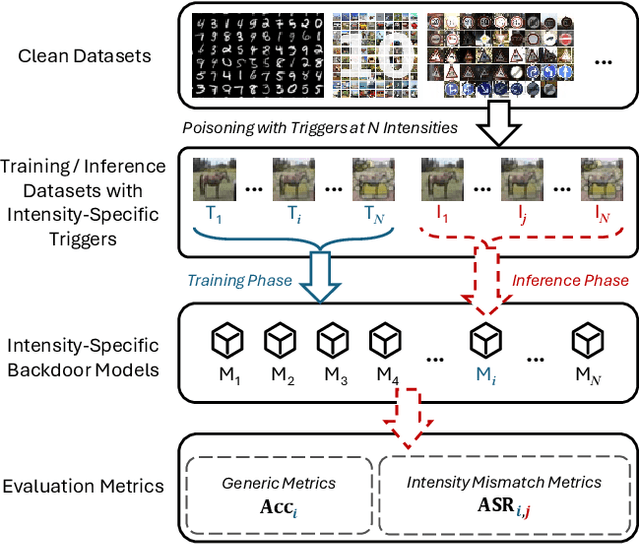
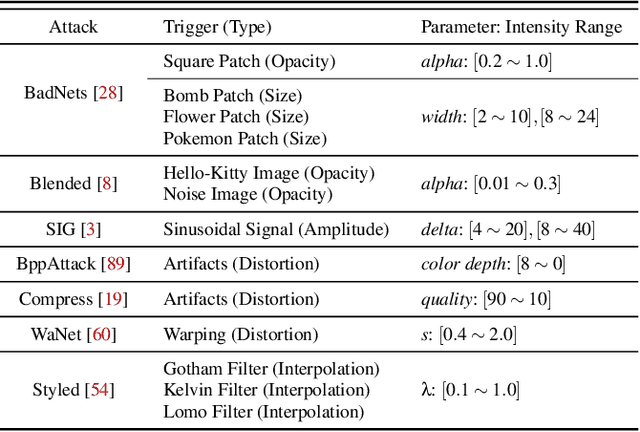
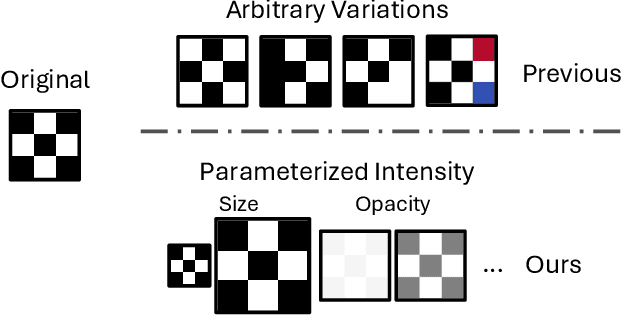
Backdoor attacks typically place a specific trigger on certain training data, such that the model makes prediction errors on inputs with that trigger during inference. Despite the core role of the trigger, existing studies have commonly believed a perfect match between training-inference triggers is optimal. In this paper, for the first time, we systematically explore the training-inference trigger relation, particularly focusing on their mismatch, based on a Training-Inference Trigger Intensity Manipulation (TITIM) workflow. TITIM specifically investigates the training-inference trigger intensity, such as the size or the opacity of a trigger, and reveals new insights into trigger generalization and overfitting. These new insights challenge the above common belief by demonstrating that the training-inference trigger mismatch can facilitate attacks in two practical scenarios, posing more significant security threats than previously thought. First, when the inference trigger is fixed, using training triggers with mixed intensities leads to stronger attacks than using any single intensity. For example, on CIFAR-10 with ResNet-18, mixing training triggers with 1.0 and 0.1 opacities improves the worst-case attack success rate (ASR) (over different testing opacities) of the best single-opacity attack from 10.61\% to 92.77\%. Second, intentionally using certain mismatched training-inference triggers can improve the attack stealthiness, i.e., better bypassing defenses. For example, compared to the training/inference intensity of 1.0/1.0, using 1.0/0.7 decreases the area under the curve (AUC) of the Scale-Up defense from 0.96 to 0.62, while maintaining a high attack ASR (99.65\% vs. 91.62\%). The above new insights are validated to be generalizable across different backdoor attacks, models, datasets, tasks, and (digital/physical) domains.
Exposing Product Bias in LLM Investment Recommendation
Mar 11, 2025Large language models (LLMs), as a new generation of recommendation engines, possess powerful summarization and data analysis capabilities, surpassing traditional recommendation systems in both scope and performance. One promising application is investment recommendation. In this paper, we reveal a novel product bias in LLM investment recommendation, where LLMs exhibit systematic preferences for specific products. Such preferences can subtly influence user investment decisions, potentially leading to inflated valuations of products and financial bubbles, posing risks to both individual investors and market stability. To comprehensively study the product bias, we develop an automated pipeline to create a dataset of 567,000 samples across five asset classes (stocks, mutual funds, cryptocurrencies, savings, and portfolios). With this dataset, we present the bf first study on product bias in LLM investment recommendations. Our findings reveal that LLMs exhibit clear product preferences, such as certain stocks (e.g., `AAPL' from Apple and `MSFT' from Microsoft). Notably, this bias persists even after applying debiasing techniques. We urge AI researchers to take heed of the product bias in LLM investment recommendations and its implications, ensuring fairness and security in the digital space and market.
StablePT: Towards Stable Prompting for Few-shot Learning via Input Separation
Apr 30, 2024Large language models have shown their ability to become effective few-shot learners with prompting, revoluting the paradigm of learning with data scarcity. However, this approach largely depends on the quality of prompt initialization, and always exhibits large variability among different runs. Such property makes prompt tuning highly unreliable and vulnerable to poorly constructed prompts, which limits its extension to more real-world applications. To tackle this issue, we propose to treat the hard prompt and soft prompt as separate inputs to mitigate noise brought by the prompt initialization. Furthermore, we optimize soft prompts with contrastive learning for utilizing class-aware information in the training process to maintain model performance. Experimental results demonstrate that \sysname outperforms state-of-the-art methods by 7.20% in accuracy and reduces the standard deviation by 2.02 on average. Furthermore, extensive experiments underscore its robustness and stability across 7 datasets covering various tasks.