 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTRA-QA: A Benchmark for Abstract Question Answering over Documents
May 11, 2026Document-based question answering (QA) increasingly includes abstract questions that require synthesizing scattered information from long documents or across multiple documents into coherent answers. However, this setting is still poorly supported by existing benchmarks and evaluation methods, which often lack stable abstract references or rely on coarse similarity metrics and unstable head-to-head comparisons. To alleviate this issue, we introduce ASTRA-QA, a benchmark for AbSTRAct Question Answering over documents. ASTRA-QA contains 869 QA instances over academic papers and news documents, covering five abstract question types and three controlled retrieval scopes. Each instance is equipped with explicit evaluation annotations, including answer topic sets, curated unsupported topics, and aligned evidence. Building on these annotations, ASTRA-QA assesses whether answers cover required key points and avoid unsupported content by directly scoring topic coverage and curated unsupported content, enabling scalable evaluation without exhaustive head-to-head comparisons. Experiments with representative Retrieval-Augmented Generation (RAG) methods spanning vanilla, graph-based, and hierarchical retrieval settings show that ASTRA-QA provides reference-grounded diagnostics for coverage, hallucination, and retrieval-scope robustness. Our dataset and code are available at https://xinyangsally.github.io/astra-benchmark.
M2IR: Proactive All-in-One Image Restoration via Mamba-style Modulation and Mixture-of-Experts
Mar 16, 2026While Transformer-based architectures have dominated recent advances in all-in-one image restoration, they remain fundamentally reactive: propagating degradations rather than proactively suppressing them. In the absence of explicit suppression mechanisms, degraded signals interfere with feature learning, compelling the decoder to balance artifact removal and detail preservation, thereby increasing model complexity and limiting adaptability. To address these challenges, we propose M2IR, a novel restoration framework that proactively regulates degradation propagation during the encoding stage and efficiently eliminates residual degradations during decoding. Specifically, the Mamba-Style Transformer (MST) block performs pixel-wise selective state modulation to mitigate degradations while preserving structural integrity. In parallel, the Adaptive Degradation Expert Collaboration (ADEC) module utilizes degradation-specific experts guided by a DA-CLIP-driven router and complemented by a shared expert to eliminate residual degradations through targeted and cooperative restoration. By integrating the MST block and ADEC module, M2IR transitions from passive reaction to active degradation control, effectively harnessing learned representations to achieve superior generalization, enhanced adaptability, and refined recovery of fine-grained details across diverse all-in-one image restoration benchmarks. Our source codes are available at https://github.com/Im34v/M2IR.
Revisiting Training-Inference Trigger Intensity in Backdoor Attacks
Mar 15, 2025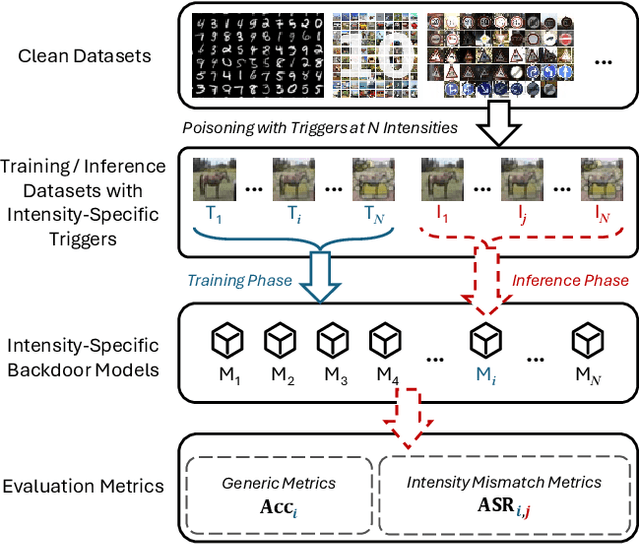
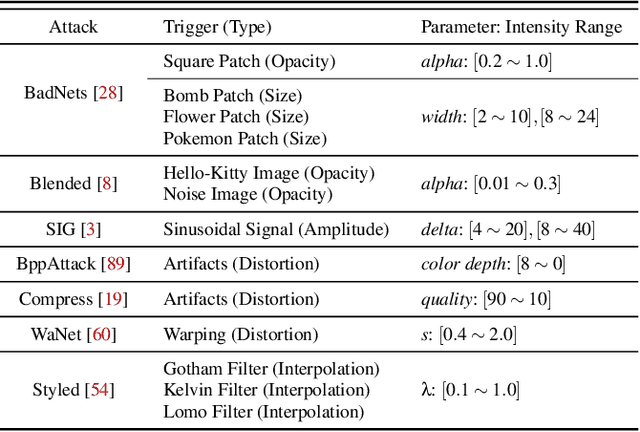
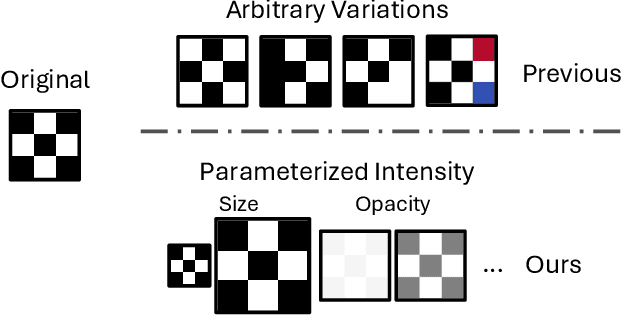
Backdoor attacks typically place a specific trigger on certain training data, such that the model makes prediction errors on inputs with that trigger during inference. Despite the core role of the trigger, existing studies have commonly believed a perfect match between training-inference triggers is optimal. In this paper, for the first time, we systematically explore the training-inference trigger relation, particularly focusing on their mismatch, based on a Training-Inference Trigger Intensity Manipulation (TITIM) workflow. TITIM specifically investigates the training-inference trigger intensity, such as the size or the opacity of a trigger, and reveals new insights into trigger generalization and overfitting. These new insights challenge the above common belief by demonstrating that the training-inference trigger mismatch can facilitate attacks in two practical scenarios, posing more significant security threats than previously thought. First, when the inference trigger is fixed, using training triggers with mixed intensities leads to stronger attacks than using any single intensity. For example, on CIFAR-10 with ResNet-18, mixing training triggers with 1.0 and 0.1 opacities improves the worst-case attack success rate (ASR) (over different testing opacities) of the best single-opacity attack from 10.61\% to 92.77\%. Second, intentionally using certain mismatched training-inference triggers can improve the attack stealthiness, i.e., better bypassing defenses. For example, compared to the training/inference intensity of 1.0/1.0, using 1.0/0.7 decreases the area under the curve (AUC) of the Scale-Up defense from 0.96 to 0.62, while maintaining a high attack ASR (99.65\% vs. 91.62\%). The above new insights are validated to be generalizable across different backdoor attacks, models, datasets, tasks, and (digital/physical) domains.
LalaEval: A Holistic Human Evaluation Framework for Domain-Specific Large Language Models
Aug 23, 2024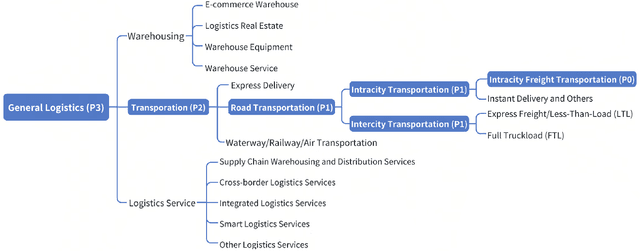


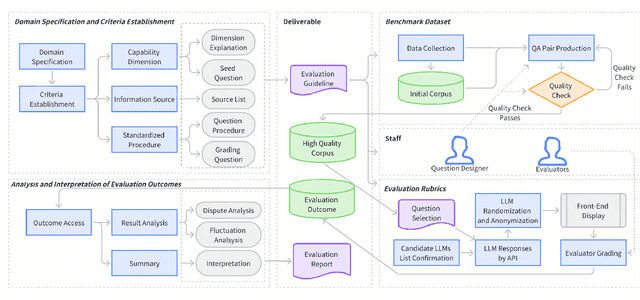
This paper introduces LalaEval, a holistic framework designed for the human evaluation of domain-specific large language models (LLMs). LalaEval proposes a comprehensive suite of end-to-end protocols that cover five main components including domain specification, criteria establishment, benchmark dataset creation, construction of evaluation rubrics, and thorough analysis and interpretation of evaluation outcomes. This initiative aims to fill a crucial research gap by providing a systematic methodology for conducting standardized human evaluations within specific domains, a practice that, despite its widespread application, lacks substantial coverage in the literature and human evaluation are often criticized to be less reliable due to subjective factors, so standardized procedures adapted to the nuanced requirements of specific domains or even individual organizations are in great need. Furthermore, the paper demonstrates the framework's application within the logistics industry, presenting domain-specific evaluation benchmarks, datasets, and a comparative analysis of LLMs for the logistics domain use, highlighting the framework's capacity to elucidate performance differences and guide model selection and development for domain-specific LLMs. Through real-world deployment, the paper underscores the framework's effectiveness in advancing the field of domain-specific LLM evaluation, thereby contributing significantly to the ongoing discussion on LLMs' practical utility and performance in domain-specific applications.
L-Sort: An Efficient Hardware for Real-time Multi-channel Spike Sorting with Localization
Jun 26, 2024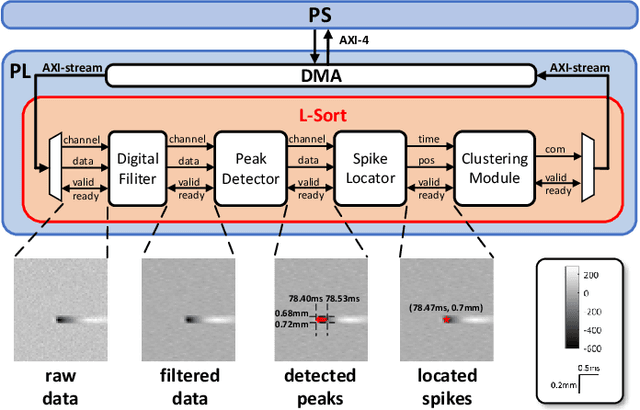
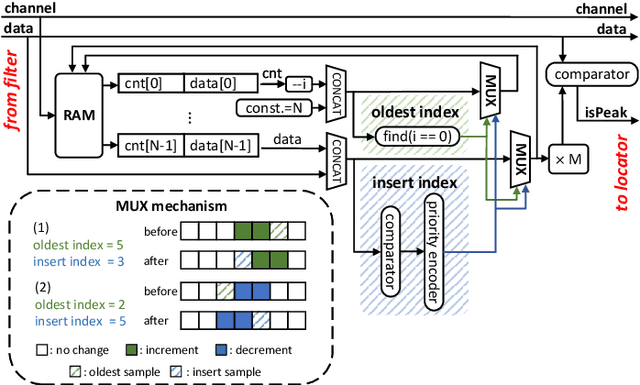
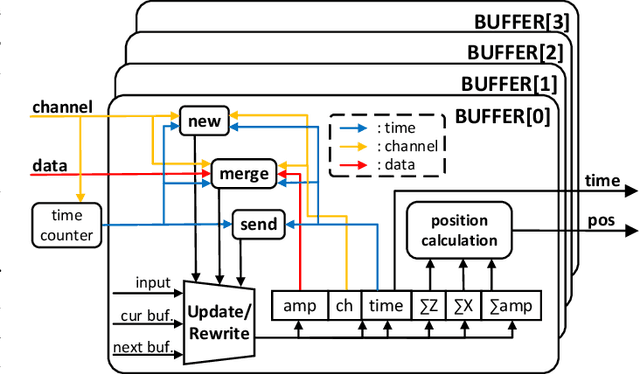
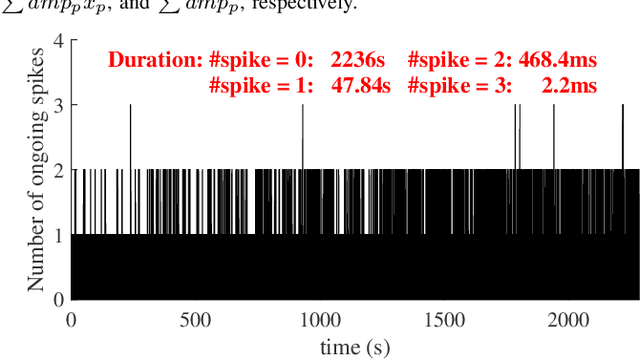
Spike sorting is essential for extracting neuronal information from neural signals and understanding brain function. With the advent of high-density microelectrode arrays (HDMEAs), the challenges and opportunities in multi-channel spike sorting have intensified. Real-time spike sorting is particularly crucial for closed-loop brain computer interface (BCI) applications, demanding efficient hardware implementations. This paper introduces L-Sort, an hardware design for real-time multi-channel spike sorting. Leveraging spike localization techniques, L-Sort achieves efficient spike detection and clustering without the need to store raw signals during detection. By incorporating median thresholding and geometric features, L-Sort demonstrates promising results in terms of accuracy and hardware efficiency. We assessed the detection and clustering accuracy of our design with publicly available datasets recorded using high-density neural probes (Neuropixel). We implemented our design on an FPGA and compared the results with state of the art. Results show that our designs consume less hardware resource comparing with other FPGA-based spike sorting hardware.
CILIATE: Towards Fairer Class-based Incremental Learning by Dataset and Training Refinement
Apr 09, 2023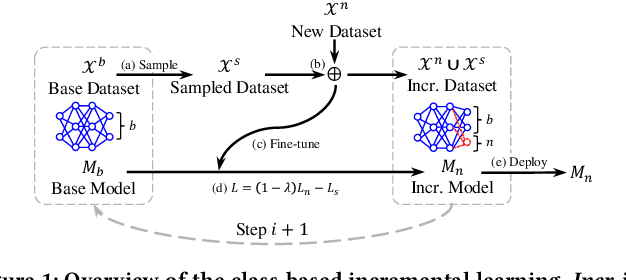
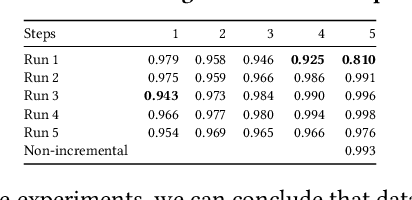
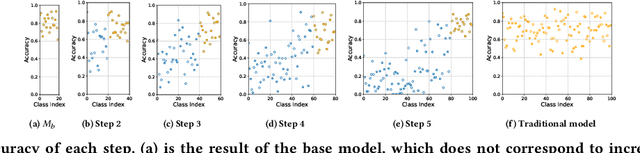
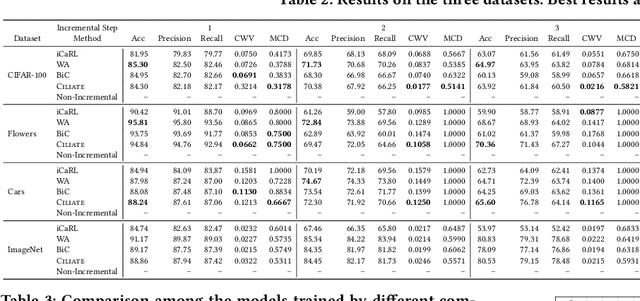
Due to the model aging problem, Deep Neural Networks (DNNs) need updates to adjust them to new data distributions. The common practice leverages incremental learning (IL), e.g., Class-based Incremental Learning (CIL) that updates output labels, to update the model with new data and a limited number of old data. This avoids heavyweight training (from scratch) using conventional methods and saves storage space by reducing the number of old data to store. But it also leads to poor performance in fairness. In this paper, we show that CIL suffers both dataset and algorithm bias problems, and existing solutions can only partially solve the problem. We propose a novel framework, CILIATE, that fixes both dataset and algorithm bias in CIL. It features a novel differential analysis guided dataset and training refinement process that identifies unique and important samples overlooked by existing CIL and enforces the model to learn from them. Through this process, CILIATE improves the fairness of CIL by 17.03%, 22.46%, and 31.79% compared to state-of-the-art methods, iCaRL, BiC, and WA, respectively, based on our evaluation on three popular datasets and widely used ResNet models.
Meta-Mining Discriminative Samples for Kinship Verification
Mar 28, 2021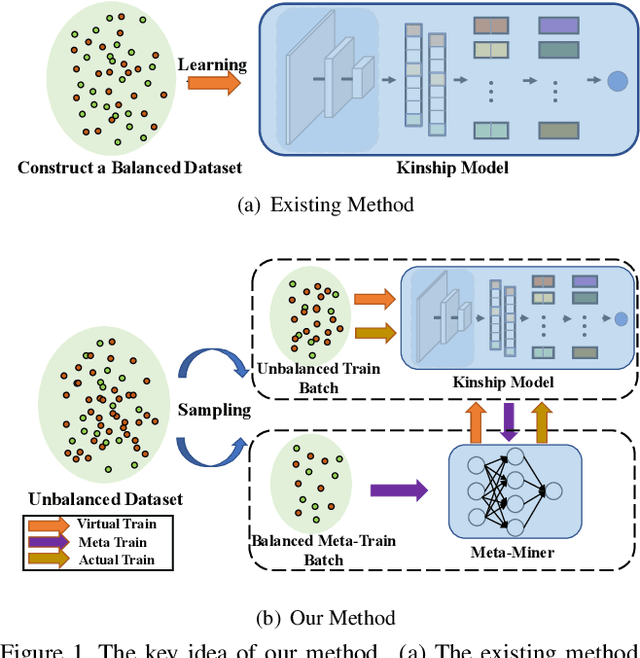
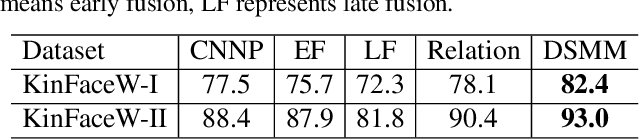

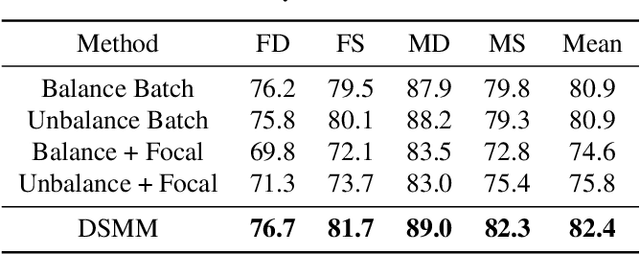
Kinship verification aims to find out whether there is a kin relation for a given pair of facial images. Kinship verification databases are born with unbalanced data. For a database with N positive kinship pairs, we naturally obtain N(N-1) negative pairs. How to fully utilize the limited positive pairs and mine discriminative information from sufficient negative samples for kinship verification remains an open issue. To address this problem, we propose a Discriminative Sample Meta-Mining (DSMM) approach in this paper. Unlike existing methods that usually construct a balanced dataset with fixed negative pairs, we propose to utilize all possible pairs and automatically learn discriminative information from data. Specifically, we sample an unbalanced train batch and a balanced meta-train batch for each iteration. Then we learn a meta-miner with the meta-gradient on the balanced meta-train batch. In the end, the samples in the unbalanced train batch are re-weighted by the learned meta-miner to optimize the kinship models. Experimental results on the widely used KinFaceW-I, KinFaceW-II, TSKinFace, and Cornell Kinship datasets demonstrate the effectiveness of the proposed approach.