 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround-truth effects in learning-based fiber orientation distribution estimation in neonatal brains
Sep 02, 2024



Diffusion Magnetic Resonance Imaging (dMRI) is a non-invasive method for depicting brain microstructure in vivo. Fiber orientation distributions (FODs) are mathematical representations extensively used to map white matter fiber configurations. Recently, FOD estimation with deep neural networks has seen growing success, in particular, those of neonates estimated with fewer diffusion measurements. These methods are mostly trained on target FODs reconstructed with multi-shell multi-tissue constrained spherical deconvolution (MSMT-CSD), which might not be the ideal ground truth for developing brains. Here, we investigate this hypothesis by training a state-of-the-art model based on the U-Net architecture on both MSMT-CSD and single-shell three-tissue constrained spherical deconvolution (SS3T-CSD). Our results suggest that SS3T-CSD might be more suited for neonatal brains, given that the ratio between single and multiple fiber-estimated voxels with SS3T-CSD is more realistic compared to MSMT-CSD. Additionally, increasing the number of input gradient directions significantly improves performance with SS3T-CSD over MSMT-CSD. Finally, in an age domain-shift setting, SS3T-CSD maintains robust performance across age groups, indicating its potential for more accurate neonatal brain imaging.
Memory AMP for Generalized MIMO: Coding Principle and Information-Theoretic Optimality
Nov 07, 2023
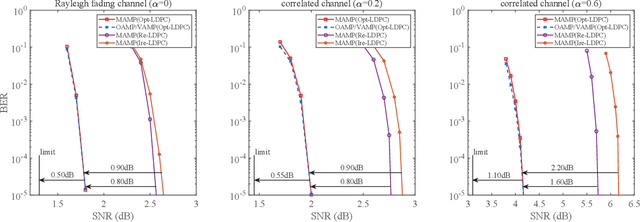
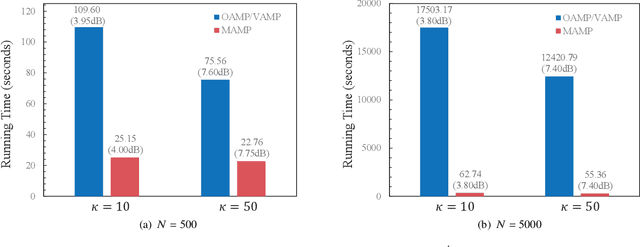
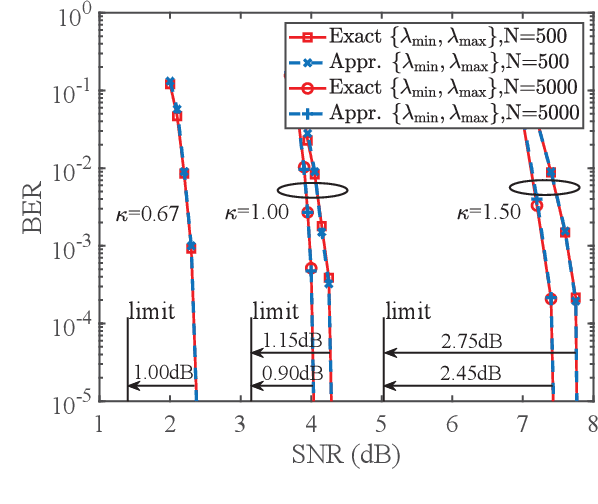
To support complex communication scenarios in next-generation wireless communications, this paper focuses on a generalized MIMO (GMIMO) with practical assumptions, such as massive antennas, practical channel coding, arbitrary input distributions, and general right-unitarily-invariant channel matrices (covering Rayleigh fading, certain ill-conditioned and correlated channel matrices). The orthogonal/vector approximate message passing (OAMP/VAMP) receiver has been proved to be information-theoretically optimal in GMIMO, but it is limited to high-complexity LMMSE. To solve this problem, a low-complexity memory approximate message passing (MAMP) receiver has recently been shown to be Bayes optimal but limited to uncoded systems. Therefore, how to design a low-complexity and information-theoretically optimal receiver for GMIMO is still an open issue. To address this issue, this paper proposes an information-theoretically optimal MAMP receiver and investigates its achievable rate analysis and optimal coding principle. Specifically, due to the long-memory linear detection, state evolution (SE) for MAMP is intricately multidimensional and cannot be used directly to analyze its achievable rate. To avoid this difficulty, a simplified single-input single-output variational SE (VSE) for MAMP is developed by leveraging the SE fixed-point consistent property of MAMP and OAMP/VAMP. The achievable rate of MAMP is calculated using the VSE, and the optimal coding principle is established to maximize the achievable rate. On this basis, the information-theoretic optimality of MAMP is proved rigorously. Numerical results show that the finite-length performances of MAMP with practical optimized LDPC codes are 0.5-2.7 dB away from the associated constrained capacities. It is worth noting that MAMP can achieve the same performances as OAMP/VAMP with 0.4% of the time consumption for large-scale systems.
Revisiting Cephalometric Landmark Detection from the view of Human Pose Estimation with Lightweight Super-Resolution Head
Sep 29, 2023



Accurate localization of cephalometric landmarks holds great importance in the fields of orthodontics and orthognathics due to its potential for automating key point labeling. In the context of landmark detection, particularly in cephalometrics, it has been observed that existing methods often lack standardized pipelines and well-designed bias reduction processes, which significantly impact their performance. In this paper, we revisit a related task, human pose estimation (HPE), which shares numerous similarities with cephalometric landmark detection (CLD), and emphasize the potential for transferring techniques from the former field to benefit the latter. Motivated by this insight, we have developed a robust and adaptable benchmark based on the well-established HPE codebase known as MMPose. This benchmark can serve as a dependable baseline for achieving exceptional CLD performance. Furthermore, we introduce an upscaling design within the framework to further enhance performance. This enhancement involves the incorporation of a lightweight and efficient super-resolution module, which generates heatmap predictions on high-resolution features and leads to further performance refinement, benefiting from its ability to reduce quantization bias. In the MICCAI CLDetection2023 challenge, our method achieves 1st place ranking on three metrics and 3rd place on the remaining one. The code for our method is available at https://github.com/5k5000/CLdetection2023.
Protecting the Intellectual Property of Diffusion Models by the Watermark Diffusion Process
Jun 06, 2023



Diffusion models have emerged as state-of-the-art deep generative architectures with the increasing demands for generation tasks. Training large diffusion models for good performance requires high resource costs, making them valuable intellectual properties to protect. While most of the existing ownership solutions, including watermarking, mainly focus on discriminative models. This paper proposes WDM, a novel watermarking method for diffusion models, including watermark embedding, extraction, and verification. WDM embeds the watermark data through training or fine-tuning the diffusion model to learn a Watermark Diffusion Process (WDP), different from the standard diffusion process for the task data. The embedded watermark can be extracted by sampling using the shared reverse noise from the learned WDP without degrading performance on the original task. We also provide theoretical foundations and analysis of the proposed method by connecting the WDP to the diffusion process with a modified Gaussian kernel. Extensive experiments are conducted to demonstrate its effectiveness and robustness against various attacks.
CILIATE: Towards Fairer Class-based Incremental Learning by Dataset and Training Refinement
Apr 09, 2023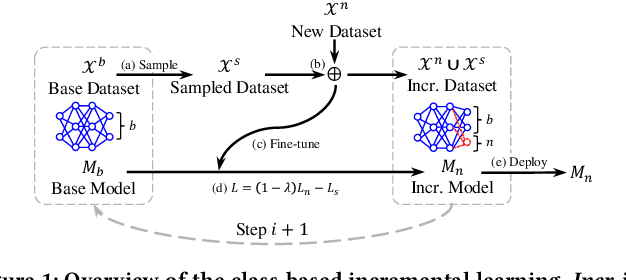
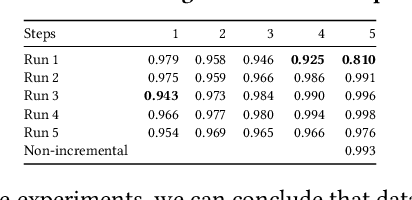
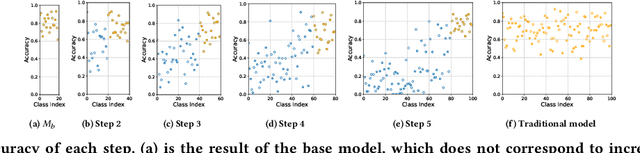
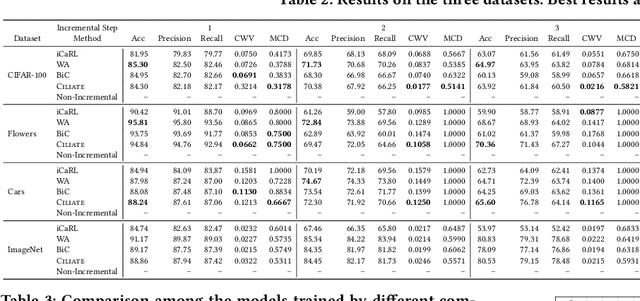
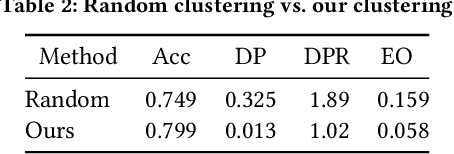
Due to the model aging problem, Deep Neural Networks (DNNs) need updates to adjust them to new data distributions. The common practice leverages incremental learning (IL), e.g., Class-based Incremental Learning (CIL) that updates output labels, to update the model with new data and a limited number of old data. This avoids heavyweight training (from scratch) using conventional methods and saves storage space by reducing the number of old data to store. But it also leads to poor performance in fairness. In this paper, we show that CIL suffers both dataset and algorithm bias problems, and existing solutions can only partially solve the problem. We propose a novel framework, CILIATE, that fixes both dataset and algorithm bias in CIL. It features a novel differential analysis guided dataset and training refinement process that identifies unique and important samples overlooked by existing CIL and enforces the model to learn from them. Through this process, CILIATE improves the fairness of CIL by 17.03%, 22.46%, and 31.79% compared to state-of-the-art methods, iCaRL, BiC, and WA, respectively, based on our evaluation on three popular datasets and widely used ResNet models.
Amplifying Membership Exposure via Data Poisoning
Nov 01, 2022



As in-the-wild data are increasingly involved in the training stage, machine learning applications become more susceptible to data poisoning attacks. Such attacks typically lead to test-time accuracy degradation or controlled misprediction. In this paper, we investigate the third type of exploitation of data poisoning - increasing the risks of privacy leakage of benign training samples. To this end, we demonstrate a set of data poisoning attacks to amplify the membership exposure of the targeted class. We first propose a generic dirty-label attack for supervised classification algorithms. We then propose an optimization-based clean-label attack in the transfer learning scenario, whereby the poisoning samples are correctly labeled and look "natural" to evade human moderation. We extensively evaluate our attacks on computer vision benchmarks. Our results show that the proposed attacks can substantially increase the membership inference precision with minimum overall test-time model performance degradation. To mitigate the potential negative impacts of our attacks, we also investigate feasible countermeasures.
Worst-Case Dynamic Power Distribution Network Noise Prediction Using Convolutional Neural Network
Apr 27, 2022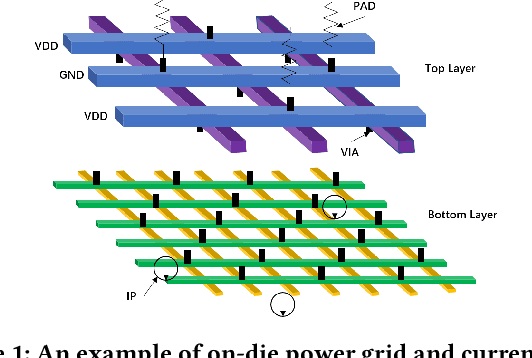
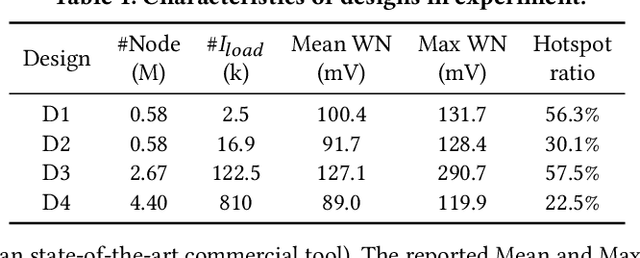
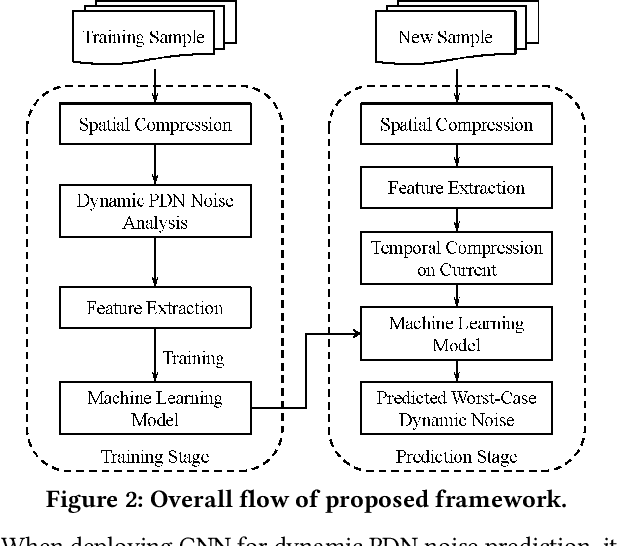

Worst-case dynamic PDN noise analysis is an essential step in PDN sign-off to ensure the performance and reliability of chips. However, with the growing PDN size and increasing scenarios to be validated, it becomes very time- and resource-consuming to conduct full-stack PDN simulation to check the worst-case noise for different test vectors. Recently, various works have proposed machine learning based methods for supply noise prediction, many of which still suffer from large training overhead, inefficiency, or non-scalability. Thus, this paper proposed an efficient and scalable framework for the worst-case dynamic PDN noise prediction. The framework first reduces the spatial and temporal redundancy in the PDN and input current vector, and then employs efficient feature extraction as well as a novel convolutional neural network architecture to predict the worst-case dynamic PDN noise. Experimental results show that the proposed framework consistently outperforms the commercial tool and the state-of-the-art machine learning method with only 0.63-1.02% mean relative error and 25-69$\times$ speedup.
FairNeuron: Improving Deep Neural Network Fairness with Adversary Games on Selective Neurons
Apr 06, 2022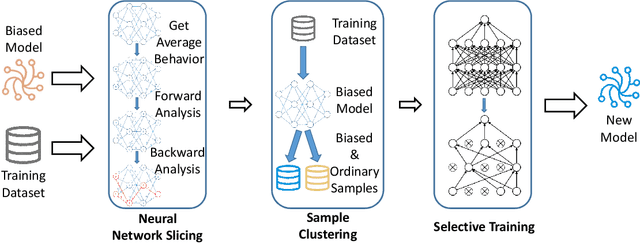

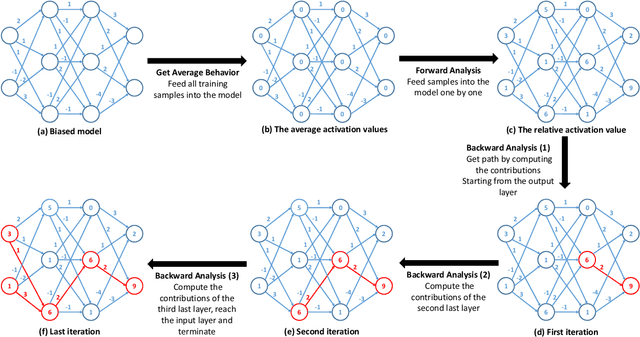
With Deep Neural Network (DNN) being integrated into a growing number of critical systems with far-reaching impacts on society, there are increasing concerns on their ethical performance, such as fairness. Unfortunately, model fairness and accuracy in many cases are contradictory goals to optimize. To solve this issue, there has been a number of work trying to improve model fairness by using an adversarial game in model level. This approach introduces an adversary that evaluates the fairness of a model besides its prediction accuracy on the main task, and performs joint-optimization to achieve a balanced result. In this paper, we noticed that when performing backward propagation based training, such contradictory phenomenon has shown on individual neuron level. Based on this observation, we propose FairNeuron, a DNN model automatic repairing tool, to mitigate fairness concerns and balance the accuracy-fairness trade-off without introducing another model. It works on detecting neurons with contradictory optimization directions from accuracy and fairness training goals, and achieving a trade-off by selective dropout. Comparing with state-of-the-art methods, our approach is lightweight, making it scalable and more efficient. Our evaluation on 3 datasets shows that FairNeuron can effectively improve all models' fairness while maintaining a stable utility.
Property Inference Attacks Against GANs
Nov 15, 2021



While machine learning (ML) has made tremendous progress during the past decade, recent research has shown that ML models are vulnerable to various security and privacy attacks. So far, most of the attacks in this field focus on discriminative models, represented by classifiers. Meanwhile, little attention has been paid to the security and privacy risks of generative models, such as generative adversarial networks (GANs). In this paper, we propose the first set of training dataset property inference attacks against GANs. Concretely, the adversary aims to infer the macro-level training dataset property, i.e., the proportion of samples used to train a target GAN with respect to a certain attribute. A successful property inference attack can allow the adversary to gain extra knowledge of the target GAN's training dataset, thereby directly violating the intellectual property of the target model owner. Also, it can be used as a fairness auditor to check whether the target GAN is trained with a biased dataset. Besides, property inference can serve as a building block for other advanced attacks, such as membership inference. We propose a general attack pipeline that can be tailored to two attack scenarios, including the full black-box setting and partial black-box setting. For the latter, we introduce a novel optimization framework to increase the attack efficacy. Extensive experiments over four representative GAN models on five property inference tasks show that our attacks achieve strong performance. In addition, we show that our attacks can be used to enhance the performance of membership inference against GANs.
Teacher Model Fingerprinting Attacks Against Transfer Learning
Jun 23, 2021

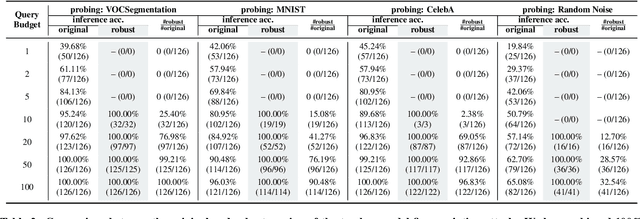
Transfer learning has become a common solution to address training data scarcity in practice. It trains a specified student model by reusing or fine-tuning early layers of a well-trained teacher model that is usually publicly available. However, besides utility improvement, the transferred public knowledge also brings potential threats to model confidentiality, and even further raises other security and privacy issues. In this paper, we present the first comprehensive investigation of the teacher model exposure threat in the transfer learning context, aiming to gain a deeper insight into the tension between public knowledge and model confidentiality. To this end, we propose a teacher model fingerprinting attack to infer the origin of a student model, i.e., the teacher model it transfers from. Specifically, we propose a novel optimization-based method to carefully generate queries to probe the student model to realize our attack. Unlike existing model reverse engineering approaches, our proposed fingerprinting method neither relies on fine-grained model outputs, e.g., posteriors, nor auxiliary information of the model architecture or training dataset. We systematically evaluate the effectiveness of our proposed attack. The empirical results demonstrate that our attack can accurately identify the model origin with few probing queries. Moreover, we show that the proposed attack can serve as a stepping stone to facilitating other attacks against machine learning models, such as model stealing.