 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiralDiff: Spiral Diffusion with LoRA for RGB-to-RAW Conversion Across Cameras
Mar 16, 2026RAW images preserve superior fidelity and rich scene information compared to RGB, making them essential for tasks in challenging imaging conditions. To alleviate the high cost of data collection, recent RGB-to-RAW conversion methods aim to synthesize RAW images from RGB. However, they overlook two key challenges: (i) the reconstruction difficulty varies with pixel intensity, and (ii) multi-camera conversion requires camera-specific adaptation. To address these issues, we propose SpiralDiff, a diffusion-based framework tailored for RGB-to-RAW conversion with a signal-dependent noise weighting strategy that adapts reconstruction fidelity across intensity levels. In addition, we introduce CamLoRA, a camera-aware lightweight adaptation module that enables a unified model to adapt to different camera-specific ISP characteristics. Extensive experiments on four benchmark datasets demonstrate the superiority of SpiralDiff in RGB-to-RAW conversion quality and its downstream benefits in RAW-based object detection. Our code and model are available at https://github.com/Chuancy-TJU/SpiralDiff.
When Visual Privacy Protection Meets Multimodal Large Language Models
Mar 14, 2026The emergence of Multimodal Large Language Models (MLLMs) and the widespread usage of MLLM cloud services such as GPT-4V raised great concerns about privacy leakage in visual data. As these models are typically deployed in cloud services, users are required to submit their images and videos, posing serious privacy risks. However, how to tackle such privacy concerns is an under-explored problem. Thus, in this paper, we aim to conduct a new investigation to protect visual privacy when enjoying the convenience brought by MLLM services. We address the practical case where the MLLM is a "black box", i.e., we only have access to its input and output without knowing its internal model information. To tackle such a challenging yet demanding problem, we propose a novel framework, in which we carefully design the learning objective with Pareto optimality to seek a better trade-off between visual privacy and MLLM's performance, and propose critical-history enhanced optimization to effectively optimize the framework with the black-box MLLM. Our experiments show that our method is effective on different benchmarks.
SELECT: Detecting Label Errors in Real-world Scene Text Data
Dec 16, 2025

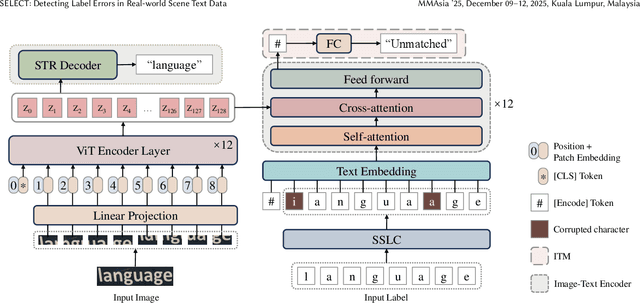

We introduce SELECT (Scene tExt Label Errors deteCTion), a novel approach that leverages multi-modal training to detect label errors in real-world scene text datasets. Utilizing an image-text encoder and a character-level tokenizer, SELECT addresses the issues of variable-length sequence labels, label sequence misalignment, and character-level errors, outperforming existing methods in accuracy and practical utility. In addition, we introduce Similarity-based Sequence Label Corruption (SSLC), a process that intentionally introduces errors into the training labels to mimic real-world error scenarios during training. SSLC not only can cause a change in the sequence length but also takes into account the visual similarity between characters during corruption. Our method is the first to detect label errors in real-world scene text datasets successfully accounting for variable-length labels. Experimental results demonstrate the effectiveness of SELECT in detecting label errors and improving STR accuracy on real-world text datasets, showcasing its practical utility.
EpiPlanAgent: Agentic Automated Epidemic Response Planning
Dec 12, 2025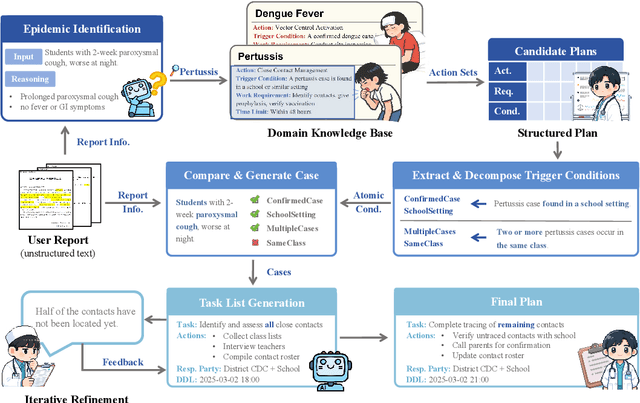

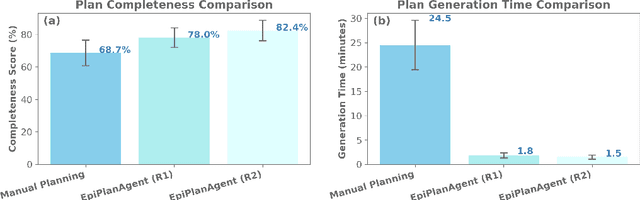

Epidemic response planning is essential yet traditionally reliant on labor-intensive manual methods. This study aimed to design and evaluate EpiPlanAgent, an agent-based system using large language models (LLMs) to automate the generation and validation of digital emergency response plans. The multi-agent framework integrated task decomposition, knowledge grounding, and simulation modules. Public health professionals tested the system using real-world outbreak scenarios in a controlled evaluation. Results demonstrated that EpiPlanAgent significantly improved the completeness and guideline alignment of plans while drastically reducing development time compared to manual workflows. Expert evaluation confirmed high consistency between AI-generated and human-authored content. User feedback indicated strong perceived utility. In conclusion, EpiPlanAgent provides an effective, scalable solution for intelligent epidemic response planning, demonstrating the potential of agentic AI to transform public health preparedness.
Deep Learning Techniques for Automatic Lateral X-ray Cephalometric Landmark Detection: Is the Problem Solved?
Sep 24, 2024Localization of the craniofacial landmarks from lateral cephalograms is a fundamental task in cephalometric analysis. The automation of the corresponding tasks has thus been the subject of intense research over the past decades. In this paper, we introduce the "Cephalometric Landmark Detection (CL-Detection)" dataset, which is the largest publicly available and comprehensive dataset for cephalometric landmark detection. This multi-center and multi-vendor dataset includes 600 lateral X-ray images with 38 landmarks acquired with different equipment from three medical centers. The overarching objective of this paper is to measure how far state-of-the-art deep learning methods can go for cephalometric landmark detection. Following the 2023 MICCAI CL-Detection Challenge, we report the results of the top ten research groups using deep learning methods. Results show that the best methods closely approximate the expert analysis, achieving a mean detection rate of 75.719% and a mean radial error of 1.518 mm. While there is room for improvement, these findings undeniably open the door to highly accurate and fully automatic location of craniofacial landmarks. We also identify scenarios for which deep learning methods are still failing. Both the dataset and detailed results are publicly available online, while the platform will remain open for the community to benchmark future algorithm developments at https://cl-detection2023.grand-challenge.org/.
In-Orbit Processing or Not? Sunlight-Aware Task Scheduling for Energy-Efficient Space Edge Computing Networks
Jul 10, 2024



With the rapid evolution of space-borne capabilities, space edge computing (SEC) is becoming a new computation paradigm for future integrated space and terrestrial networks. Satellite edges adopt advanced on-board hardware, which not only enables new opportunities to perform complex intelligent tasks in orbit, but also involves new challenges due to the additional energy consumption in power-constrained space environment. In this paper, we present PHOENIX, an energy-efficient task scheduling framework for emerging SEC networks. PHOENIX exploits a key insight that in the SEC network, there always exist a number of sunlit edges which are illuminated during the entire orbital period and have sufficient energy supplement from the sun. PHOENIX accomplishes energy-efficient in-orbit computing by judiciously offloading space tasks to "sunlight-sufficient" edges or to the ground. Specifically, PHOENIX first formulates the SEC battery energy optimizing (SBEO) problem which aims at minimizing the average battery energy consumption while satisfying various task completion constraints. Then PHOENIX incorporates a sunlight-aware scheduling mechanism to solve the SBEO problem and schedule SEC tasks efficiently. Finally, we implement a PHOENIX prototype and build an SEC testbed. Extensive data-driven evaluations demonstrate that as compared to other state-of-the-art solutions, PHOENIX can effectively reduce up to 54.8% SEC battery energy consumption and prolong battery lifetime to 2.9$\times$ while still completing tasks on time.
HaltingVT: Adaptive Token Halting Transformer for Efficient Video Recognition
Jan 10, 2024
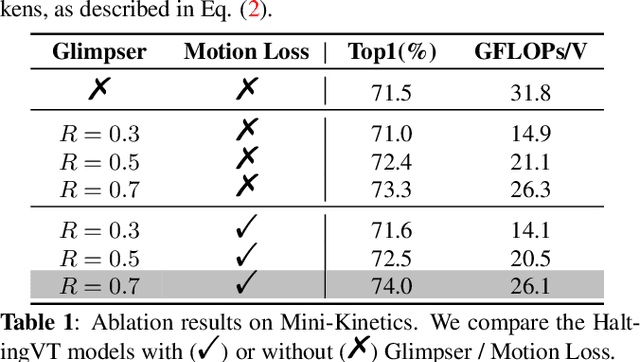
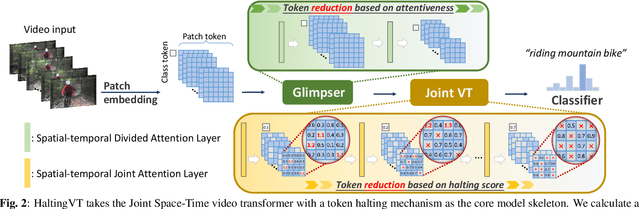
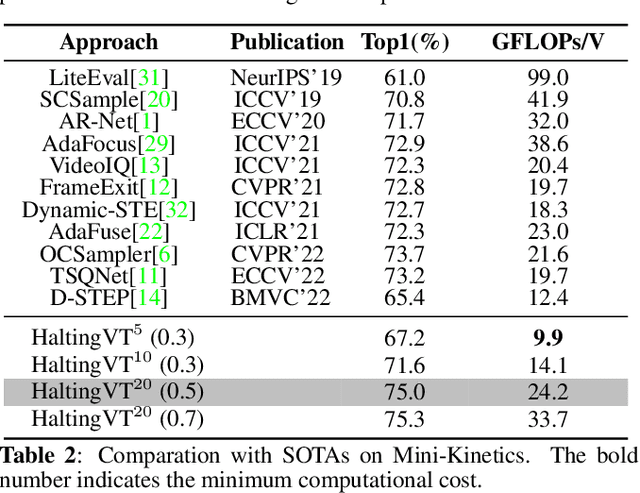
Action recognition in videos poses a challenge due to its high computational cost, especially for Joint Space-Time video transformers (Joint VT). Despite their effectiveness, the excessive number of tokens in such architectures significantly limits their efficiency. In this paper, we propose HaltingVT, an efficient video transformer adaptively removing redundant video patch tokens, which is primarily composed of a Joint VT and a Glimpser module. Specifically, HaltingVT applies data-adaptive token reduction at each layer, resulting in a significant reduction in the overall computational cost. Besides, the Glimpser module quickly removes redundant tokens in shallow transformer layers, which may even be misleading for video recognition tasks based on our observations. To further encourage HaltingVT to focus on the key motion-related information in videos, we design an effective Motion Loss during training. HaltingVT acquires video analysis capabilities and token halting compression strategies simultaneously in a unified training process, without requiring additional training procedures or sub-networks. On the Mini-Kinetics dataset, we achieved 75.0% top-1 ACC with 24.2 GFLOPs, as well as 67.2% top-1 ACC with an extremely low 9.9 GFLOPs. The code is available at https://github.com/dun-research/HaltingVT.
Revisiting Cephalometric Landmark Detection from the view of Human Pose Estimation with Lightweight Super-Resolution Head
Sep 29, 2023



Accurate localization of cephalometric landmarks holds great importance in the fields of orthodontics and orthognathics due to its potential for automating key point labeling. In the context of landmark detection, particularly in cephalometrics, it has been observed that existing methods often lack standardized pipelines and well-designed bias reduction processes, which significantly impact their performance. In this paper, we revisit a related task, human pose estimation (HPE), which shares numerous similarities with cephalometric landmark detection (CLD), and emphasize the potential for transferring techniques from the former field to benefit the latter. Motivated by this insight, we have developed a robust and adaptable benchmark based on the well-established HPE codebase known as MMPose. This benchmark can serve as a dependable baseline for achieving exceptional CLD performance. Furthermore, we introduce an upscaling design within the framework to further enhance performance. This enhancement involves the incorporation of a lightweight and efficient super-resolution module, which generates heatmap predictions on high-resolution features and leads to further performance refinement, benefiting from its ability to reduce quantization bias. In the MICCAI CLDetection2023 challenge, our method achieves 1st place ranking on three metrics and 3rd place on the remaining one. The code for our method is available at https://github.com/5k5000/CLdetection2023.
Differentiable Resolution Compression and Alignment for Efficient Video Classification and Retrieval
Sep 15, 2023Optimizing video inference efficiency has become increasingly important with the growing demand for video analysis in various fields. Some existing methods achieve high efficiency by explicit discard of spatial or temporal information, which poses challenges in fast-changing and fine-grained scenarios. To address these issues, we propose an efficient video representation network with Differentiable Resolution Compression and Alignment mechanism, which compresses non-essential information in the early stage of the network to reduce computational costs while maintaining consistent temporal correlations. Specifically, we leverage a Differentiable Context-aware Compression Module to encode the saliency and non-saliency frame features, refining and updating the features into a high-low resolution video sequence. To process the new sequence, we introduce a new Resolution-Align Transformer Layer to capture global temporal correlations among frame features with different resolutions, while reducing spatial computation costs quadratically by utilizing fewer spatial tokens in low-resolution non-saliency frames. The entire network can be end-to-end optimized via the integration of the differentiable compression module. Experimental results show that our method achieves the best trade-off between efficiency and performance on near-duplicate video retrieval and competitive results on dynamic video classification compared to state-of-the-art methods. Code:https://github.com/dun-research/DRCA
GaitFormer: Revisiting Intrinsic Periodicity for Gait Recognition
Jul 25, 2023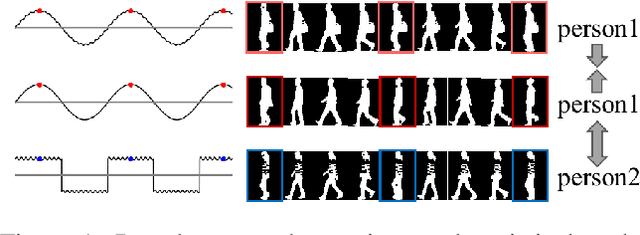
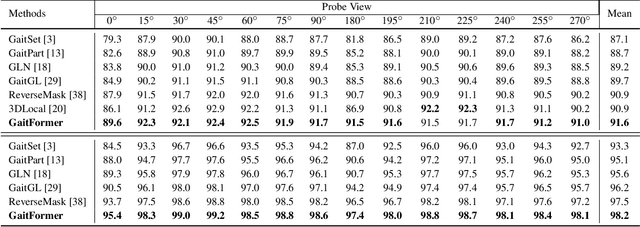
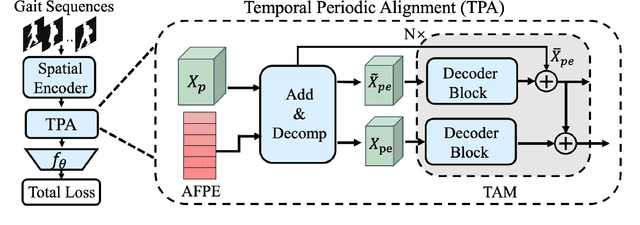
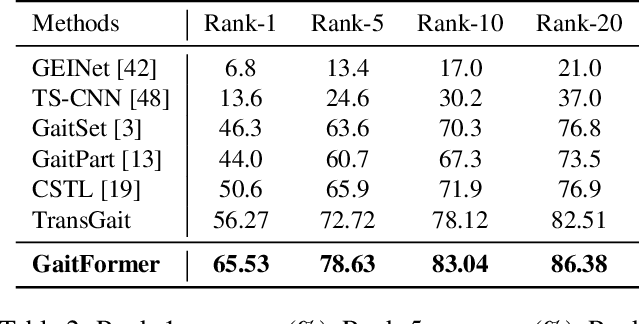
Gait recognition aims to distinguish different walking patterns by analyzing video-level human silhouettes, rather than relying on appearance information. Previous research on gait recognition has primarily focused on extracting local or global spatial-temporal representations, while overlooking the intrinsic periodic features of gait sequences, which, when fully utilized, can significantly enhance performance. In this work, we propose a plug-and-play strategy, called Temporal Periodic Alignment (TPA), which leverages the periodic nature and fine-grained temporal dependencies of gait patterns. The TPA strategy comprises two key components. The first component is Adaptive Fourier-transform Position Encoding (AFPE), which adaptively converts features and discrete-time signals into embeddings that are sensitive to periodic walking patterns. The second component is the Temporal Aggregation Module (TAM), which separates embeddings into trend and seasonal components, and extracts meaningful temporal correlations to identify primary components, while filtering out random noise. We present a simple and effective baseline method for gait recognition, based on the TPA strategy. Extensive experiments conducted on three popular public datasets (CASIA-B, OU-MVLP, and GREW) demonstrate that our proposed method achieves state-of-the-art performance on multiple benchmark tests.