 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSARE: Sample-wise Adaptive Reasoning for Training-free Fine-grained Visual Recognition
Mar 18, 2026Recent advances in Large Vision-Language Models (LVLMs) have enabled training-free Fine-Grained Visual Recognition (FGVR). However, effectively exploiting LVLMs for FGVR remains challenging due to the inherent visual ambiguity of subordinate-level categories. Existing methods predominantly adopt either retrieval-oriented or reasoning-oriented paradigms to tackle this challenge, but both are constrained by two fundamental limitations:(1) They apply the same inference pipeline to all samples without accounting for uneven recognition difficulty, thereby leading to suboptimal accuracy and efficiency; (2) The lack of mechanisms to consolidate and reuse error-specific experience causes repeated failures on similar challenging cases. To address these limitations, we propose SARE, a Sample-wise Adaptive textbfREasoning framework for training-free FGVR. Specifically, SARE adopts a cascaded design that combines fast candidate retrieval with fine-grained reasoning, invoking the latter only when necessary. In the reasoning process, SARE incorporates a self-reflective experience mechanism that leverages past failures to provide transferable discriminative guidance during inference, without any parameter updates. Extensive experiments across 14 datasets substantiate that SARE achieves state-of-the-art performance while substantially reducing computational overhead.
SELECT: Detecting Label Errors in Real-world Scene Text Data
Dec 16, 2025

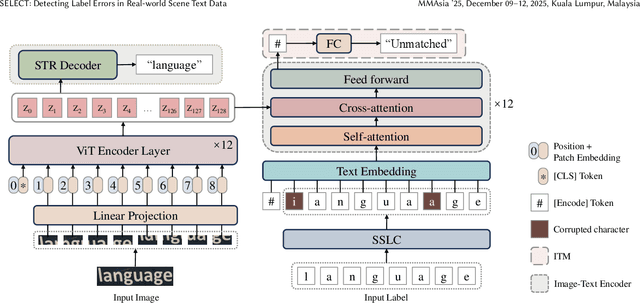

We introduce SELECT (Scene tExt Label Errors deteCTion), a novel approach that leverages multi-modal training to detect label errors in real-world scene text datasets. Utilizing an image-text encoder and a character-level tokenizer, SELECT addresses the issues of variable-length sequence labels, label sequence misalignment, and character-level errors, outperforming existing methods in accuracy and practical utility. In addition, we introduce Similarity-based Sequence Label Corruption (SSLC), a process that intentionally introduces errors into the training labels to mimic real-world error scenarios during training. SSLC not only can cause a change in the sequence length but also takes into account the visual similarity between characters during corruption. Our method is the first to detect label errors in real-world scene text datasets successfully accounting for variable-length labels. Experimental results demonstrate the effectiveness of SELECT in detecting label errors and improving STR accuracy on real-world text datasets, showcasing its practical utility.
XEmoRAG: Cross-Lingual Emotion Transfer with Controllable Intensity Using Retrieval-Augmented Generation
Aug 12, 2025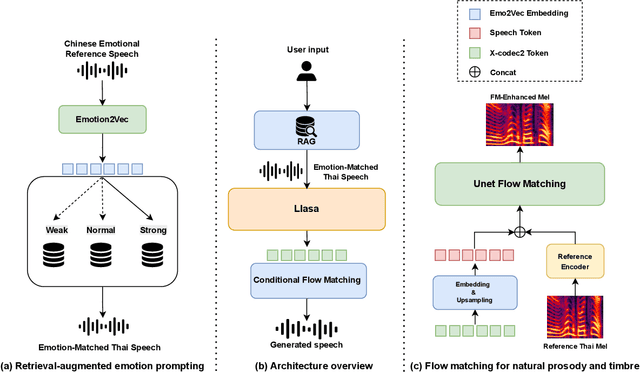
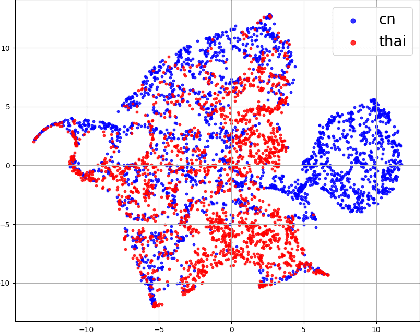
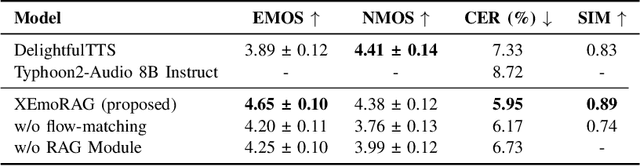
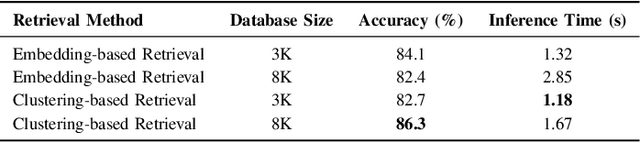
Zero-shot emotion transfer in cross-lingual speech synthesis refers to generating speech in a target language, where the emotion is expressed based on reference speech from a different source language. However, this task remains challenging due to the scarcity of parallel multilingual emotional corpora, the presence of foreign accent artifacts, and the difficulty of separating emotion from language-specific prosodic features. In this paper, we propose XEmoRAG, a novel framework to enable zero-shot emotion transfer from Chinese to Thai using a large language model (LLM)-based model, without relying on parallel emotional data. XEmoRAG extracts language-agnostic emotional embeddings from Chinese speech and retrieves emotionally matched Thai utterances from a curated emotional database, enabling controllable emotion transfer without explicit emotion labels. Additionally, a flow-matching alignment module minimizes pitch and duration mismatches, ensuring natural prosody. It also blends Chinese timbre into the Thai synthesis, enhancing rhythmic accuracy and emotional expression, while preserving speaker characteristics and emotional consistency. Experimental results show that XEmoRAG synthesizes expressive and natural Thai speech using only Chinese reference audio, without requiring explicit emotion labels. These results highlight XEmoRAG's capability to achieve flexible and low-resource emotional transfer across languages. Our demo is available at https://tlzuo-lesley.github.io/Demo-page/ .
CityGo: Lightweight Urban Modeling and Rendering with Proxy Buildings and Residual Gaussians
May 28, 2025



Accurate and efficient modeling of large-scale urban scenes is critical for applications such as AR navigation, UAV based inspection, and smart city digital twins. While aerial imagery offers broad coverage and complements limitations of ground-based data, reconstructing city-scale environments from such views remains challenging due to occlusions, incomplete geometry, and high memory demands. Recent advances like 3D Gaussian Splatting (3DGS) improve scalability and visual quality but remain limited by dense primitive usage, long training times, and poor suit ability for edge devices. We propose CityGo, a hybrid framework that combines textured proxy geometry with residual and surrounding 3D Gaussians for lightweight, photorealistic rendering of urban scenes from aerial perspectives. Our approach first extracts compact building proxy meshes from MVS point clouds, then uses zero order SH Gaussians to generate occlusion-free textures via image-based rendering and back-projection. To capture high-frequency details, we introduce residual Gaussians placed based on proxy-photo discrepancies and guided by depth priors. Broader urban context is represented by surrounding Gaussians, with importance-aware downsampling applied to non-critical regions to reduce redundancy. A tailored optimization strategy jointly refines proxy textures and Gaussian parameters, enabling real-time rendering of complex urban scenes on mobile GPUs with significantly reduced training and memory requirements. Extensive experiments on real-world aerial datasets demonstrate that our hybrid representation significantly reduces training time, achieving on average 1.4x speedup, while delivering comparable visual fidelity to pure 3D Gaussian Splatting approaches. Furthermore, CityGo enables real-time rendering of large-scale urban scenes on mobile consumer GPUs, with substantially reduced memory usage and energy consumption.
Riemannian Complex Hermit Positive Definite Convolution Network for Polarimetric SAR Image Classification
Feb 12, 2025Deep learning can learn high-level semantic features in Euclidean space effectively for PolSAR images, while they need to covert the complex covariance matrix into a feature vector or complex-valued vector as the network input. However, the complex covariance matrices are essentially a complex Hermit positive definite (HPD) matrix endowed in Riemannian manifold rather than Euclidean space. The matrix's real and imagery parts are with the same significance, as the imagery part represents the phase information. The matrix vectorization will destroy the geometric structure and manifold characteristics of complex covariance matrices. To learn complex HPD matrices directly, we propose a Riemannian complex HPD convolution network(HPD\_CNN) for PolSAR images. This method consists of a complex HPD unfolding network(HPDnet) and a CV-3DCNN enhanced network. The proposed complex HPDnet defines the HPD mapping, rectifying and the logEig layers to learn geometric features of complex matrices. In addition, a fast eigenvalue decomposition method is designed to reduce computation burden. Finally, a Riemannian-to-Euclidean enhanced network is defined to enhance contextual information for classification. Experimental results on two real PolSSAR datasets demonstrate the proposed method can achieve superior performance than the state-of-the-art methods especially in heterogeneous regions.
FleSpeech: Flexibly Controllable Speech Generation with Various Prompts
Jan 08, 2025



Controllable speech generation methods typically rely on single or fixed prompts, hindering creativity and flexibility. These limitations make it difficult to meet specific user needs in certain scenarios, such as adjusting the style while preserving a selected speaker's timbre, or choosing a style and generating a voice that matches a character's visual appearance. To overcome these challenges, we propose \textit{FleSpeech}, a novel multi-stage speech generation framework that allows for more flexible manipulation of speech attributes by integrating various forms of control. FleSpeech employs a multimodal prompt encoder that processes and unifies different text, audio, and visual prompts into a cohesive representation. This approach enhances the adaptability of speech synthesis and supports creative and precise control over the generated speech. Additionally, we develop a data collection pipeline for multimodal datasets to facilitate further research and applications in this field. Comprehensive subjective and objective experiments demonstrate the effectiveness of FleSpeech. Audio samples are available at https://kkksuper.github.io/FleSpeech/
CoDiff-VC: A Codec-Assisted Diffusion Model for Zero-shot Voice Conversion
Dec 03, 2024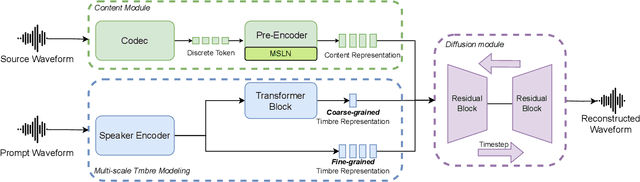
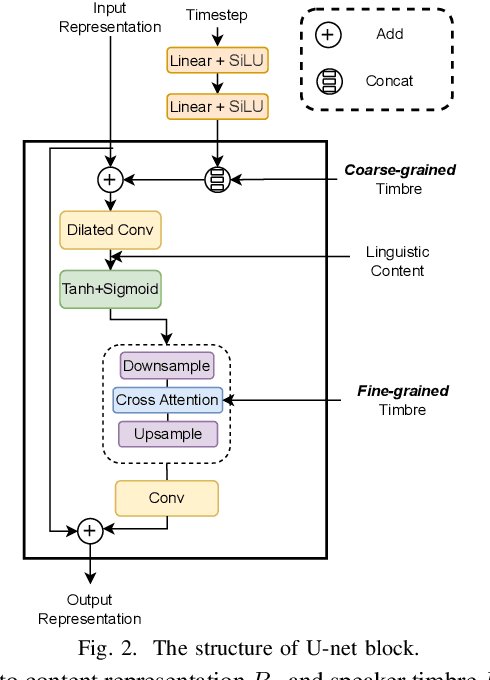
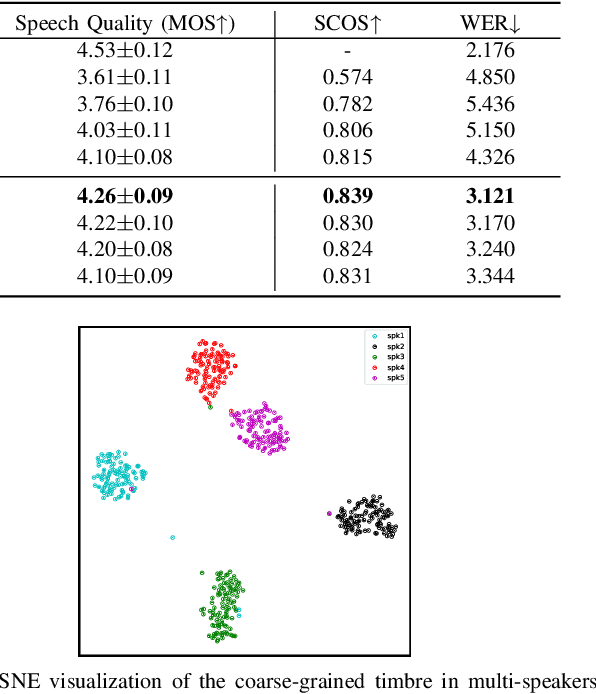
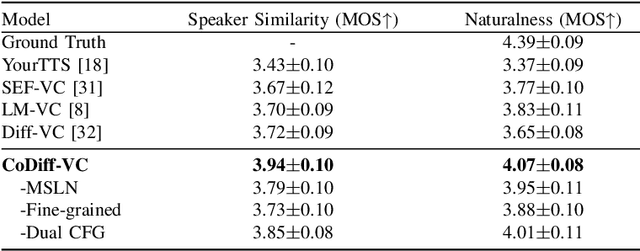
Zero-shot voice conversion (VC) aims to convert the original speaker's timbre to any target speaker while keeping the linguistic content. Current mainstream zero-shot voice conversion approaches depend on pre-trained recognition models to disentangle linguistic content and speaker representation. This results in a timbre residue within the decoupled linguistic content and inadequacies in speaker representation modeling. In this study, we propose CoDiff-VC, an end-to-end framework for zero-shot voice conversion that integrates a speech codec and a diffusion model to produce high-fidelity waveforms. Our approach involves employing a single-codebook codec to separate linguistic content from the source speech. To enhance content disentanglement, we introduce Mix-Style layer normalization (MSLN) to perturb the original timbre. Additionally, we incorporate a multi-scale speaker timbre modeling approach to ensure timbre consistency and improve voice detail similarity. To improve speech quality and speaker similarity, we introduce dual classifier-free guidance, providing both content and timbre guidance during the generation process. Objective and subjective experiments affirm that CoDiff-VC significantly improves speaker similarity, generating natural and higher-quality speech.
Cross-Modal Few-Shot Learning: a Generative Transfer Learning Framework
Oct 14, 2024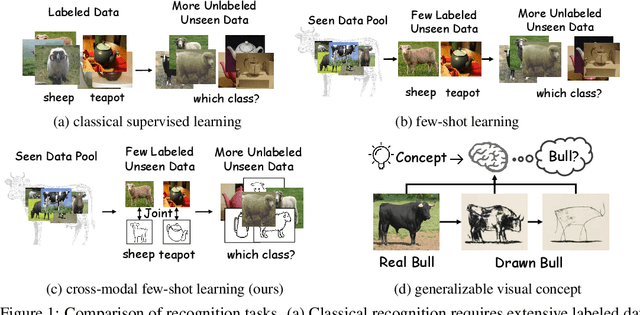
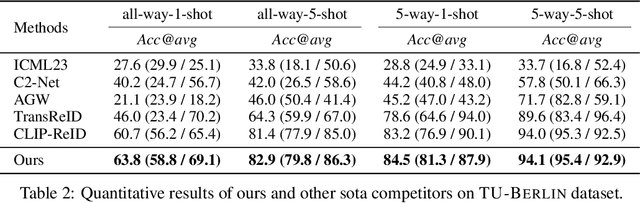
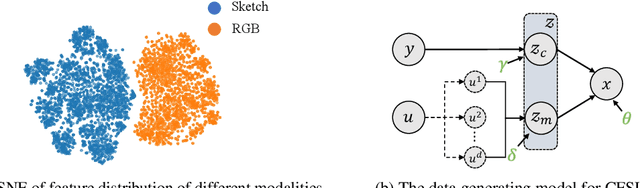
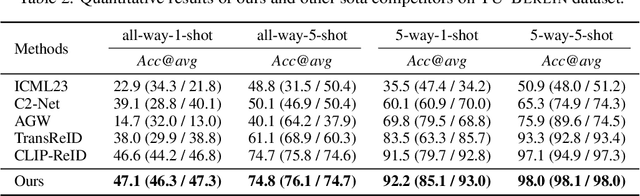
Most existing studies on few-shot learning focus on unimodal settings, where models are trained to generalize on unseen data using only a small number of labeled examples from the same modality. However, real-world data are inherently multi-modal, and unimodal approaches limit the practical applications of few-shot learning. To address this gap, this paper introduces the Cross-modal Few-Shot Learning (CFSL) task, which aims to recognize instances from multiple modalities when only a few labeled examples are available. This task presents additional challenges compared to classical few-shot learning due to the distinct visual characteristics and structural properties unique to each modality. To tackle these challenges, we propose a Generative Transfer Learning (GTL) framework consisting of two stages: the first stage involves training on abundant unimodal data, and the second stage focuses on transfer learning to adapt to novel data. Our GTL framework jointly estimates the latent shared concept across modalities and in-modality disturbance in both stages, while freezing the generative module during the transfer phase to maintain the stability of the learned representations and prevent overfitting to the limited multi-modal samples. Our finds demonstrate that GTL has superior performance compared to state-of-the-art methods across four distinct multi-modal datasets: Sketchy, TU-Berlin, Mask1K, and SKSF-A. Additionally, the results suggest that the model can estimate latent concepts from vast unimodal data and generalize these concepts to unseen modalities using only a limited number of available samples, much like human cognitive processes.
Split to Merge: Unifying Separated Modalities for Unsupervised Domain Adaptation
Mar 11, 2024
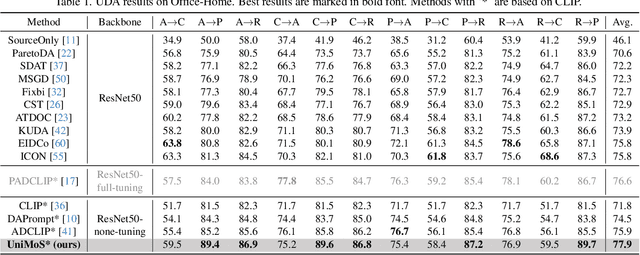
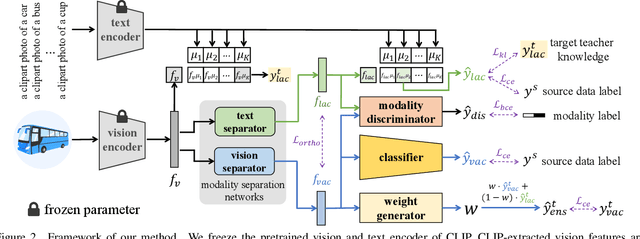
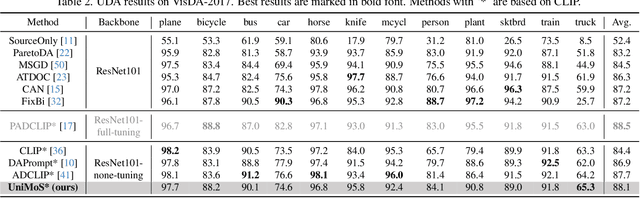
Large vision-language models (VLMs) like CLIP have demonstrated good zero-shot learning performance in the unsupervised domain adaptation task. Yet, most transfer approaches for VLMs focus on either the language or visual branches, overlooking the nuanced interplay between both modalities. In this work, we introduce a Unified Modality Separation (UniMoS) framework for unsupervised domain adaptation. Leveraging insights from modality gap studies, we craft a nimble modality separation network that distinctly disentangles CLIP's features into language-associated and vision-associated components. Our proposed Modality-Ensemble Training (MET) method fosters the exchange of modality-agnostic information while maintaining modality-specific nuances. We align features across domains using a modality discriminator. Comprehensive evaluations on three benchmarks reveal our approach sets a new state-of-the-art with minimal computational costs. Code: https://github.com/TL-UESTC/UniMoS
Learning Domain-Invariant Temporal Dynamics for Few-Shot Action Recognition
Feb 20, 2024
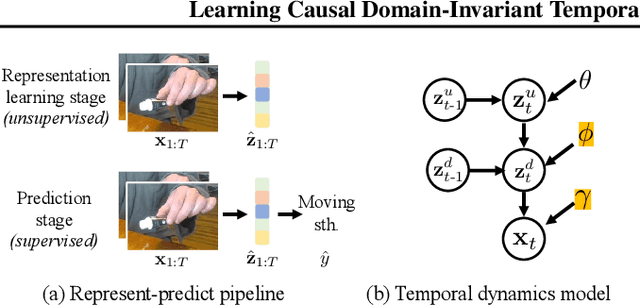

Few-shot action recognition aims at quickly adapting a pre-trained model to the novel data with a distribution shift using only a limited number of samples. Key challenges include how to identify and leverage the transferable knowledge learned by the pre-trained model. Our central hypothesis is that temporal invariance in the dynamic system between latent variables lends itself to transferability (domain-invariance). We therefore propose DITeD, or Domain-Invariant Temporal Dynamics for knowledge transfer. To detect the temporal invariance part, we propose a generative framework with a two-stage training strategy during pre-training. Specifically, we explicitly model invariant dynamics including temporal dynamic generation and transitions, and the variant visual and domain encoders. Then we pre-train the model with the self-supervised signals to learn the representation. After that, we fix the whole representation model and tune the classifier. During adaptation, we fix the transferable temporal dynamics and update the image encoder. The efficacy of our approach is revealed by the superior accuracy of DITeD over leading alternatives across standard few-shot action recognition datasets. Moreover, we validate that the learned temporal dynamic transition and temporal dynamic generation modules possess transferable qualities.