 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFleSpeech: Flexibly Controllable Speech Generation with Various Prompts
Jan 08, 2025



Controllable speech generation methods typically rely on single or fixed prompts, hindering creativity and flexibility. These limitations make it difficult to meet specific user needs in certain scenarios, such as adjusting the style while preserving a selected speaker's timbre, or choosing a style and generating a voice that matches a character's visual appearance. To overcome these challenges, we propose \textit{FleSpeech}, a novel multi-stage speech generation framework that allows for more flexible manipulation of speech attributes by integrating various forms of control. FleSpeech employs a multimodal prompt encoder that processes and unifies different text, audio, and visual prompts into a cohesive representation. This approach enhances the adaptability of speech synthesis and supports creative and precise control over the generated speech. Additionally, we develop a data collection pipeline for multimodal datasets to facilitate further research and applications in this field. Comprehensive subjective and objective experiments demonstrate the effectiveness of FleSpeech. Audio samples are available at https://kkksuper.github.io/FleSpeech/
MSM-VC: High-fidelity Source Style Transfer for Non-Parallel Voice Conversion by Multi-scale Style Modeling
Sep 03, 2023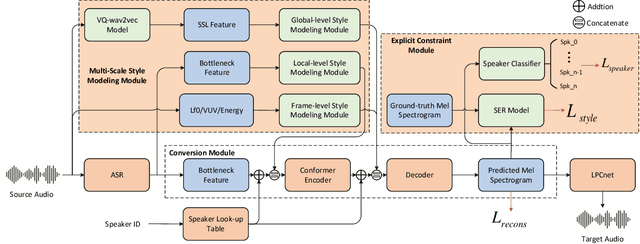



In addition to conveying the linguistic content from source speech to converted speech, maintaining the speaking style of source speech also plays an important role in the voice conversion (VC) task, which is essential in many scenarios with highly expressive source speech, such as dubbing and data augmentation. Previous work generally took explicit prosodic features or fixed-length style embedding extracted from source speech to model the speaking style of source speech, which is insufficient to achieve comprehensive style modeling and target speaker timbre preservation. Inspired by the style's multi-scale nature of human speech, a multi-scale style modeling method for the VC task, referred to as MSM-VC, is proposed in this paper. MSM-VC models the speaking style of source speech from different levels. To effectively convey the speaking style and meanwhile prevent timbre leakage from source speech to converted speech, each level's style is modeled by specific representation. Specifically, prosodic features, pre-trained ASR model's bottleneck features, and features extracted by a model trained with a self-supervised strategy are adopted to model the frame, local, and global-level styles, respectively. Besides, to balance the performance of source style modeling and target speaker timbre preservation, an explicit constraint module consisting of a pre-trained speech emotion recognition model and a speaker classifier is introduced to MSM-VC. This explicit constraint module also makes it possible to simulate the style transfer inference process during the training to improve the disentanglement ability and alleviate the mismatch between training and inference. Experiments performed on the highly expressive speech corpus demonstrate that MSM-VC is superior to the state-of-the-art VC methods for modeling source speech style while maintaining good speech quality and speaker similarity.
UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
Dec 06, 2022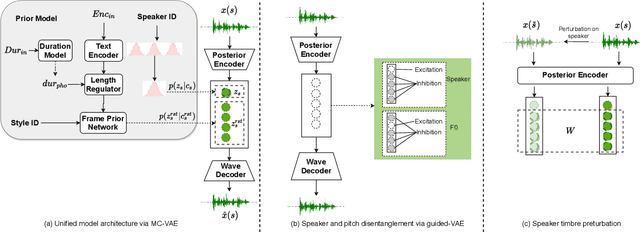



Text-to-speech (TTS) and singing voice synthesis (SVS) aim at generating high-quality speaking and singing voice according to textual input and music scores, respectively. Unifying TTS and SVS into a single system is crucial to the applications requiring both of them. Existing methods usually suffer from some limitations, which rely on either both singing and speaking data from the same person or cascaded models of multiple tasks. To address these problems, a simplified elegant framework for TTS and SVS, named UniSyn, is proposed in this paper. It is an end-to-end unified model that can make a voice speak and sing with only singing or speaking data from this person. To be specific, a multi-conditional variational autoencoder (MC-VAE), which constructs two independent latent sub-spaces with the speaker- and style-related (i.e. speak or sing) conditions for flexible control, is proposed in UniSyn. Moreover, supervised guided-VAE and timbre perturbation with the Wasserstein distance constraint are leveraged to further disentangle the speaker timbre and style. Experiments conducted on two speakers and two singers demonstrate that UniSyn can generate natural speaking and singing voice without corresponding training data. The proposed approach outperforms the state-of-the-art end-to-end voice generation work, which proves the effectiveness and advantages of UniSyn.
Expressive-VC: Highly Expressive Voice Conversion with Attention Fusion of Bottleneck and Perturbation Features
Nov 09, 2022



Voice conversion for highly expressive speech is challenging. Current approaches struggle with the balancing between speaker similarity, intelligibility and expressiveness. To address this problem, we propose Expressive-VC, a novel end-to-end voice conversion framework that leverages advantages from both neural bottleneck feature (BNF) approach and information perturbation approach. Specifically, we use a BNF encoder and a Perturbed-Wav encoder to form a content extractor to learn linguistic and para-linguistic features respectively, where BNFs come from a robust pre-trained ASR model and the perturbed wave becomes speaker-irrelevant after signal perturbation. We further fuse the linguistic and para-linguistic features through an attention mechanism, where speaker-dependent prosody features are adopted as the attention query, which result from a prosody encoder with target speaker embedding and normalized pitch and energy of source speech as input. Finally the decoder consumes the integrated features and the speaker-dependent prosody feature to generate the converted speech. Experiments demonstrate that Expressive-VC is superior to several state-of-the-art systems, achieving both high expressiveness captured from the source speech and high speaker similarity with the target speaker; meanwhile intelligibility is well maintained.
Cross-speaker Emotion Transfer Based On Prosody Compensation for End-to-End Speech Synthesis
Jul 04, 2022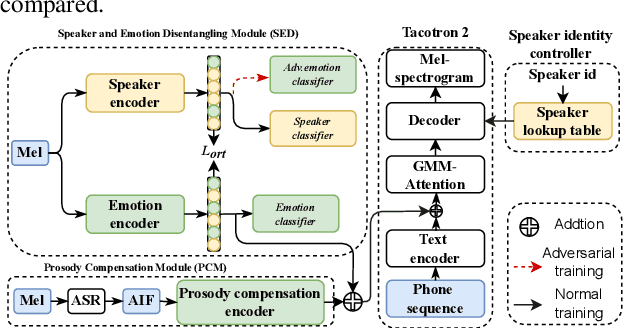
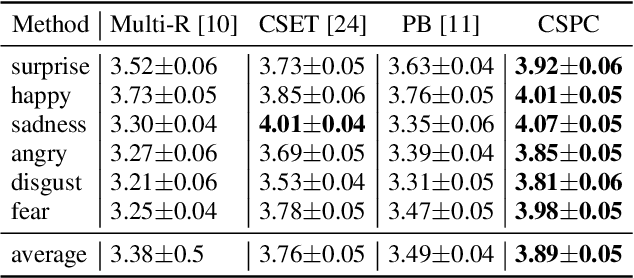
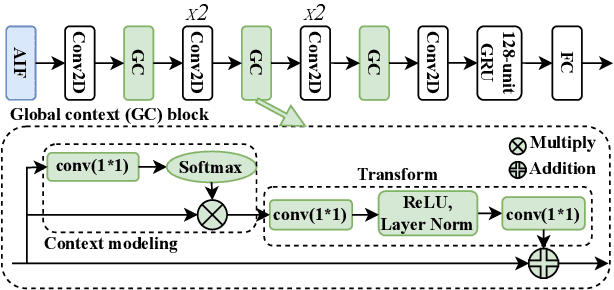
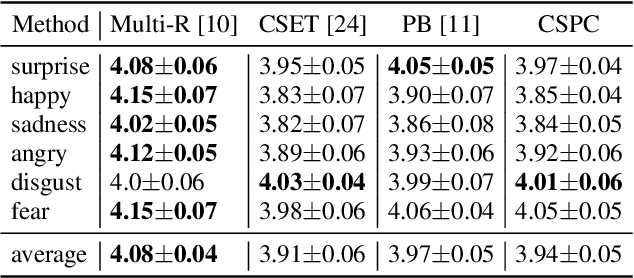
Cross-speaker emotion transfer speech synthesis aims to synthesize emotional speech for a target speaker by transferring the emotion from reference speech recorded by another (source) speaker. In this task, extracting speaker-independent emotion embedding from reference speech plays an important role. However, the emotional information conveyed by such emotion embedding tends to be weakened in the process to squeeze out the source speaker's timbre information. In response to this problem, a prosody compensation module (PCM) is proposed in this paper to compensate for the emotional information loss. Specifically, the PCM tries to obtain speaker-independent emotional information from the intermediate feature of a pre-trained ASR model. To this end, a prosody compensation encoder with global context (GC) blocks is introduced to obtain global emotional information from the ASR model's intermediate feature. Experiments demonstrate that the proposed PCM can effectively compensate the emotion embedding for the emotional information loss, and meanwhile maintain the timbre of the target speaker. Comparisons with state-of-the-art models show that our proposed method presents obvious superiority on the cross-speaker emotion transfer task.
End-to-End Voice Conversion with Information Perturbation
Jun 15, 2022

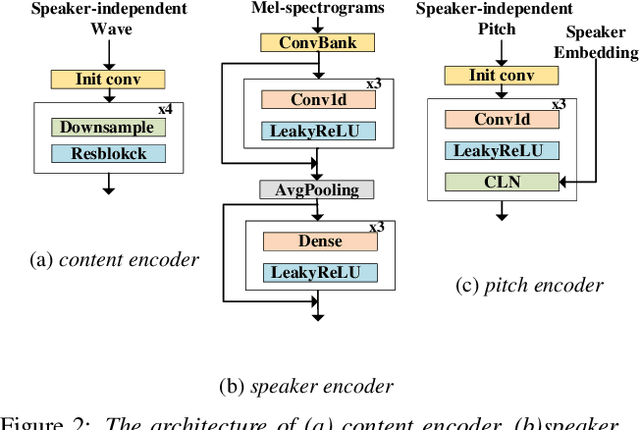
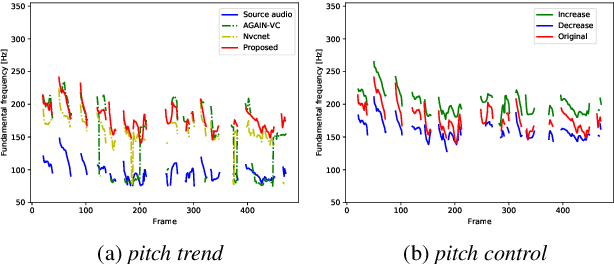
The ideal goal of voice conversion is to convert the source speaker's speech to sound naturally like the target speaker while maintaining the linguistic content and the prosody of the source speech. However, current approaches are insufficient to achieve comprehensive source prosody transfer and target speaker timbre preservation in the converted speech, and the quality of the converted speech is also unsatisfied due to the mismatch between the acoustic model and the vocoder. In this paper, we leverage the recent advances in information perturbation and propose a fully end-to-end approach to conduct high-quality voice conversion. We first adopt information perturbation to remove speaker-related information in the source speech to disentangle speaker timbre and linguistic content and thus the linguistic information is subsequently modeled by a content encoder. To better transfer the prosody of the source speech to the target, we particularly introduce a speaker-related pitch encoder which can maintain the general pitch pattern of the source speaker while flexibly modifying the pitch intensity of the generated speech. Finally, one-shot voice conversion is set up through continuous speaker space modeling. Experimental results indicate that the proposed end-to-end approach significantly outperforms the state-of-the-art models in terms of intelligibility, naturalness, and speaker similarity.
Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Training Data Scenarios
Dec 23, 2021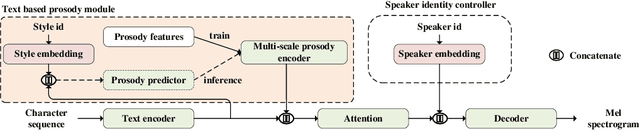

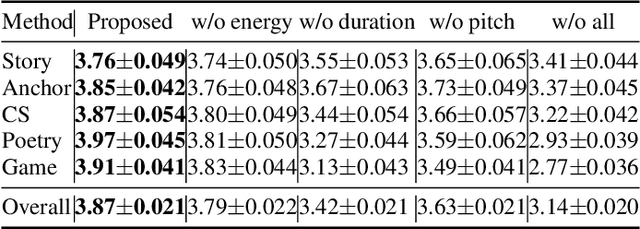
In the existing cross-speaker style transfer task, a source speaker with multi-style recordings is necessary to provide the style for a target speaker. However, it is hard for one speaker to express all expected styles. In this paper, a more general task, which is to produce expressive speech by combining any styles and timbres from a multi-speaker corpus in which each speaker has a unique style, is proposed. To realize this task, a novel method is proposed. This method is a Tacotron2-based framework but with a fine-grained text-based prosody predicting module and a speaker identity controller. Experiments demonstrate that the proposed method can successfully express a style of one speaker with the timber of another speaker bypassing the dependency on a single speaker's multi-style corpus. Moreover, the explicit prosody features used in the prosody predicting module can increase the diversity of synthetic speech by adjusting the value of prosody features.
One-shot Voice Conversion For Style Transfer Based On Speaker Adaptation
Nov 24, 2021One-shot style transfer is a challenging task, since training on one utterance makes model extremely easy to over-fit to training data and causes low speaker similarity and lack of expressiveness. In this paper, we build on the recognition-synthesis framework and propose a one-shot voice conversion approach for style transfer based on speaker adaptation. First, a speaker normalization module is adopted to remove speaker-related information in bottleneck features extracted by ASR. Second, we adopt weight regularization in the adaptation process to prevent over-fitting caused by using only one utterance from target speaker as training data. Finally, to comprehensively decouple the speech factors, i.e., content, speaker, style, and transfer source style to the target, a prosody module is used to extract prosody representation. Experiments show that our approach is superior to the state-of-the-art one-shot VC systems in terms of style and speaker similarity; additionally, our approach also maintains good speech quality.
Controllable cross-speaker emotion transfer for end-to-end speech synthesis
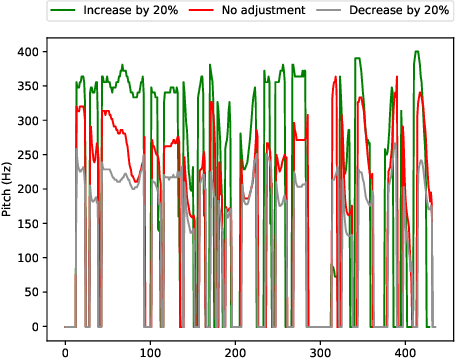
Sep 14, 2021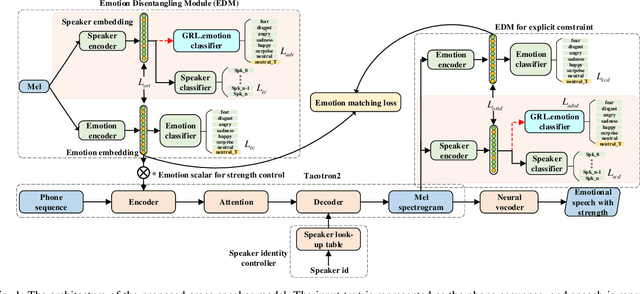
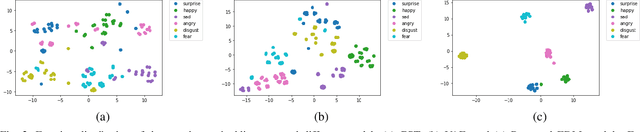
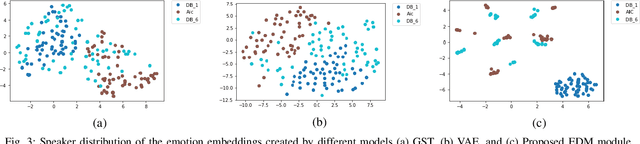
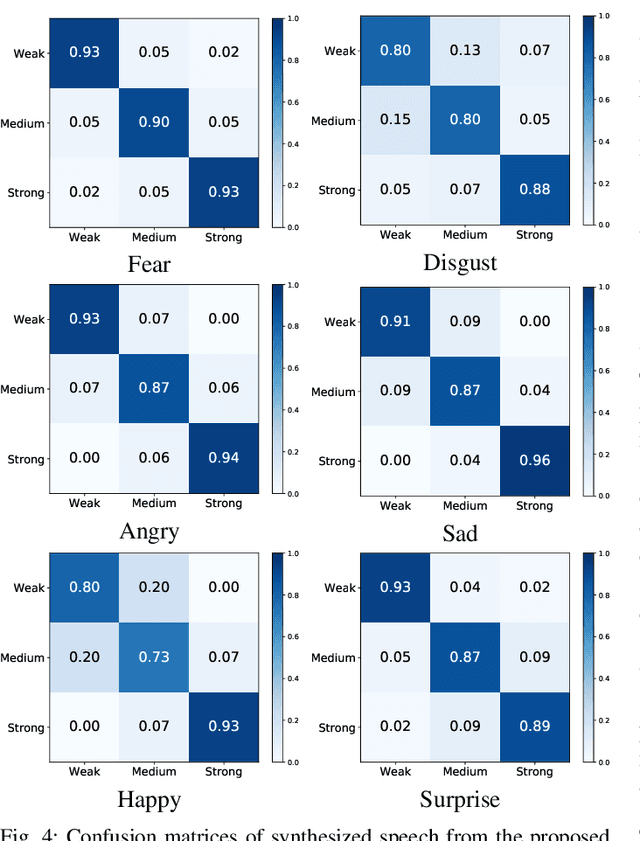
The cross-speaker emotion transfer task in TTS particularly aims to synthesize speech for a target speaker with the emotion transferred from reference speech recorded by another (source) speaker. During the emotion transfer process, the identity information of the source speaker could also affect the synthesized results, resulting in the issue of speaker leakage. This paper proposes a new method with the aim to synthesize controllable emotional expressive speech and meanwhile maintain the target speaker's identity in the cross-speaker emotion TTS task. The proposed method is a Tacotron2-based framework with the emotion embedding as the conditioning variable to provide emotion information. Two emotion disentangling modules are contained in our method to 1) get speaker-independent and emotion-discriminative embedding, and 2) explicitly constrain the emotion and speaker identity of synthetic speech to be that as expected. Moreover, we present an intuitive method to control the emotional strength in the synthetic speech for the target speaker. Specifically, the learned emotion embedding is adjusted with a flexible scalar value, which allows controlling the emotion strength conveyed by the embedding. Extensive experiments have been conducted on a Mandarin disjoint corpus, and the results demonstrate that the proposed method is able to synthesize reasonable emotional speech for the target speaker. Compared to the state-of-the-art reference embedding learned methods, our method gets the best performance on the cross-speaker emotion transfer task, indicating that our method achieves the new state-of-the-art performance on learning the speaker-independent emotion embedding. Furthermore, the strength ranking test and pitch trajectories plots demonstrate that the proposed method can effectively control the emotion strength, leading to prosody-diverse synthetic speech.
AnyoneNet: Synchronized Speech and Talking Head Generation for Arbitrary Person
Aug 11, 2021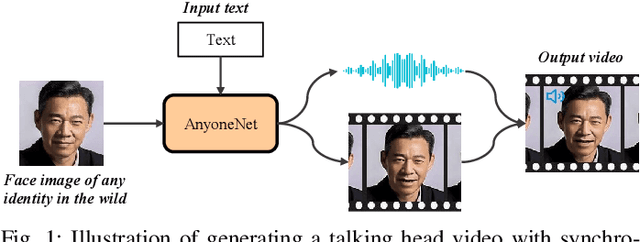
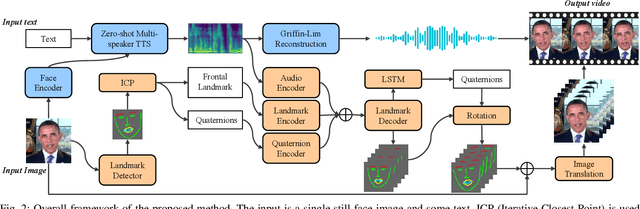
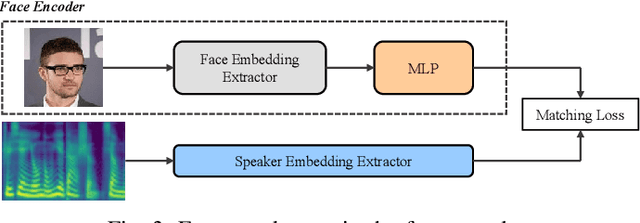

Automatically generating videos in which synthesized speech is synchronized with lip movements in a talking head has great potential in many human-computer interaction scenarios. In this paper, we present an automatic method to generate synchronized speech and talking-head videos on the basis of text and a single face image of an arbitrary person as input. In contrast to previous text-driven talking head generation methods, which can only synthesize the voice of a specific person, the proposed method is capable of synthesizing speech for any person that is inaccessible in the training stage. Specifically, the proposed method decomposes the generation of synchronized speech and talking head videos into two stages, i.e., a text-to-speech (TTS) stage and a speech-driven talking head generation stage. The proposed TTS module is a face-conditioned multi-speaker TTS model that gets the speaker identity information from face images instead of speech, which allows us to synthesize a personalized voice on the basis of the input face image. To generate the talking head videos from the face images, a facial landmark-based method that can predict both lip movements and head rotations is proposed. Extensive experiments demonstrate that the proposed method is able to generate synchronized speech and talking head videos for arbitrary persons and non-persons. Synthesized speech shows consistency with the given face regarding to the synthesized voice's timbre and one's appearance in the image, and the proposed landmark-based talking head method outperforms the state-of-the-art landmark-based method on generating natural talking head videos.