 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepASMR: LLM-Based Zero-Shot ASMR Speech Generation for Anyone of Any Voice
Jan 22, 2026While modern Text-to-Speech (TTS) systems achieve high fidelity for read-style speech, they struggle to generate Autonomous Sensory Meridian Response (ASMR), a specialized, low-intensity speech style essential for relaxation. The inherent challenges include ASMR's subtle, often unvoiced characteristics and the demand for zero-shot speaker adaptation. In this paper, we introduce DeepASMR, the first framework designed for zero-shot ASMR generation. We demonstrate that a single short snippet of a speaker's ordinary, read-style speech is sufficient to synthesize high-fidelity ASMR in their voice, eliminating the need for whispered training data from the target speaker. Methodologically, we first identify that discrete speech tokens provide a soft factorization of ASMR style from speaker timbre. Leveraging this insight, we propose a two-stage pipeline incorporating a Large Language Model (LLM) for content-style encoding and a flow-matching acoustic decoder for timbre reconstruction. Furthermore, we contribute DeepASMR-DB, a comprehensive 670-hour English-Chinese multi-speaker ASMR speech corpus, and introduce a novel evaluation protocol integrating objective metrics, human listening tests, LLM-based scoring and unvoiced speech analysis. Extensive experiments confirm that DeepASMR achieves state-of-the-art naturalness and style fidelity in ASMR generation for anyone of any voice, while maintaining competitive performance on normal speech synthesis.
REF-VC: Robust, Expressive and Fast Zero-Shot Voice Conversion with Diffusion Transformers
Aug 07, 2025In real-world voice conversion applications, environmental noise in source speech and user demands for expressive output pose critical challenges. Traditional ASR-based methods ensure noise robustness but suppress prosody, while SSL-based models improve expressiveness but suffer from timbre leakage and noise sensitivity. This paper proposes REF-VC, a noise-robust expressive voice conversion system. Key innovations include: (1) A random erasing strategy to mitigate the information redundancy inherent in SSL feature, enhancing noise robustness and expressiveness; (2) Implicit alignment inspired by E2TTS to suppress non-essential feature reconstruction; (3) Integration of Shortcut Models to accelerate flow matching inference, significantly reducing to 4 steps. Experimental results demonstrate that our model outperforms baselines such as Seed-VC in zero-shot scenarios on the noisy set, while also performing comparably to Seed-VC on the clean set. In addition, REF-VC can be compatible with singing voice conversion within one model.
Multimodal Latent Diffusion Model for Complex Sewing Pattern Generation
Dec 19, 2024



Generating sewing patterns in garment design is receiving increasing attention due to its CG-friendly and flexible-editing nature. Previous sewing pattern generation methods have been able to produce exquisite clothing, but struggle to design complex garments with detailed control. To address these issues, we propose SewingLDM, a multi-modal generative model that generates sewing patterns controlled by text prompts, body shapes, and garment sketches. Initially, we extend the original vector of sewing patterns into a more comprehensive representation to cover more intricate details and then compress them into a compact latent space. To learn the sewing pattern distribution in the latent space, we design a two-step training strategy to inject the multi-modal conditions, \ie, body shapes, text prompts, and garment sketches, into a diffusion model, ensuring the generated garments are body-suited and detail-controlled. Comprehensive qualitative and quantitative experiments show the effectiveness of our proposed method, significantly surpassing previous approaches in terms of complex garment design and various body adaptability. Our project page: https://shengqiliu1.github.io/SewingLDM.
Revealing Directions for Text-guided 3D Face Editing
Oct 07, 2024



3D face editing is a significant task in multimedia, aimed at the manipulation of 3D face models across various control signals. The success of 3D-aware GAN provides expressive 3D models learned from 2D single-view images only, encouraging researchers to discover semantic editing directions in its latent space. However, previous methods face challenges in balancing quality, efficiency, and generalization. To solve the problem, we explore the possibility of introducing the strength of diffusion model into 3D-aware GANs. In this paper, we present Face Clan, a fast and text-general approach for generating and manipulating 3D faces based on arbitrary attribute descriptions. To achieve disentangled editing, we propose to diffuse on the latent space under a pair of opposite prompts to estimate the mask indicating the region of interest on latent codes. Based on the mask, we then apply denoising to the masked latent codes to reveal the editing direction. Our method offers a precisely controllable manipulation method, allowing users to intuitively customize regions of interest with the text description. Experiments demonstrate the effectiveness and generalization of our Face Clan for various pre-trained GANs. It offers an intuitive and wide application for text-guided face editing that contributes to the landscape of multimedia content creation.
E1 TTS: Simple and Fast Non-Autoregressive TTS
Sep 14, 2024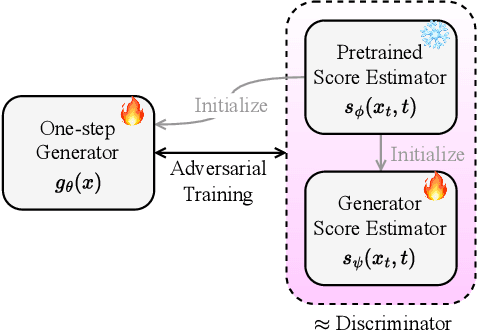
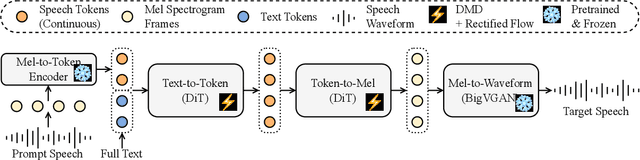
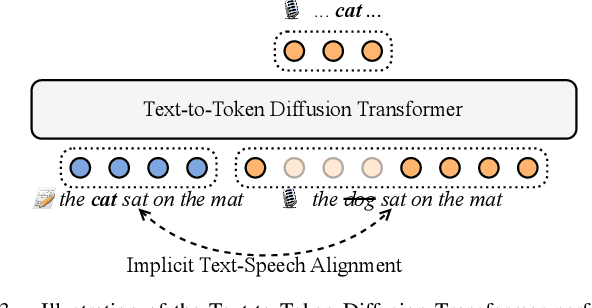
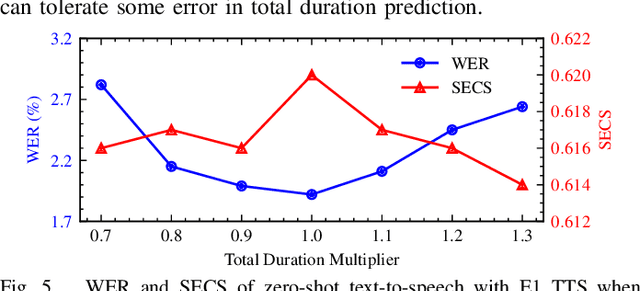
This paper introduces Easy One-Step Text-to-Speech (E1 TTS), an efficient non-autoregressive zero-shot text-to-speech system based on denoising diffusion pretraining and distribution matching distillation. The training of E1 TTS is straightforward; it does not require explicit monotonic alignment between the text and audio pairs. The inference of E1 TTS is efficient, requiring only one neural network evaluation for each utterance. Despite its sampling efficiency, E1 TTS achieves naturalness and speaker similarity comparable to various strong baseline models. Audio samples are available at http://e1tts.github.io/ .
MacST: Multi-Accent Speech Synthesis via Text Transliteration for Accent Conversion
Sep 14, 2024



In accented voice conversion or accent conversion, we seek to convert the accent in speech from one another while preserving speaker identity and semantic content. In this study, we formulate a novel method for creating multi-accented speech samples, thus pairs of accented speech samples by the same speaker, through text transliteration for training accent conversion systems. We begin by generating transliterated text with Large Language Models (LLMs), which is then fed into multilingual TTS models to synthesize accented English speech. As a reference system, we built a sequence-to-sequence model on the synthetic parallel corpus for accent conversion. We validated the proposed method for both native and non-native English speakers. Subjective and objective evaluations further validate our dataset's effectiveness in accent conversion studies.
HIMO: A New Benchmark for Full-Body Human Interacting with Multiple Objects
Jul 17, 2024



Generating human-object interactions (HOIs) is critical with the tremendous advances of digital avatars. Existing datasets are typically limited to humans interacting with a single object while neglecting the ubiquitous manipulation of multiple objects. Thus, we propose HIMO, a large-scale MoCap dataset of full-body human interacting with multiple objects, containing 3.3K 4D HOI sequences and 4.08M 3D HOI frames. We also annotate HIMO with detailed textual descriptions and temporal segments, benchmarking two novel tasks of HOI synthesis conditioned on either the whole text prompt or the segmented text prompts as fine-grained timeline control. To address these novel tasks, we propose a dual-branch conditional diffusion model with a mutual interaction module for HOI synthesis. Besides, an auto-regressive generation pipeline is also designed to obtain smooth transitions between HOI segments. Experimental results demonstrate the generalization ability to unseen object geometries and temporal compositions.
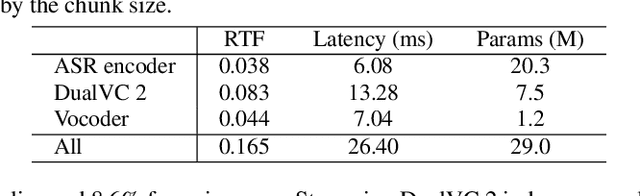
DualVC 3: Leveraging Language Model Generated Pseudo Context for End-to-end Low Latency Streaming Voice Conversion
Jun 12, 2024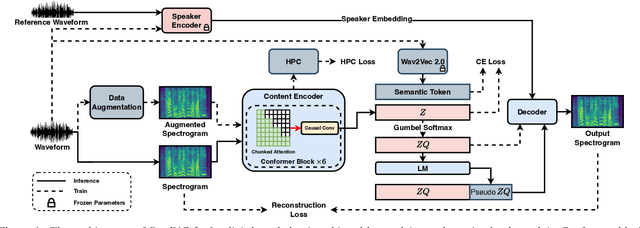
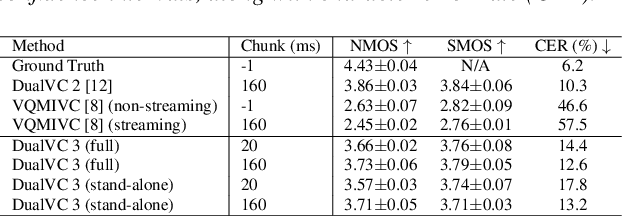
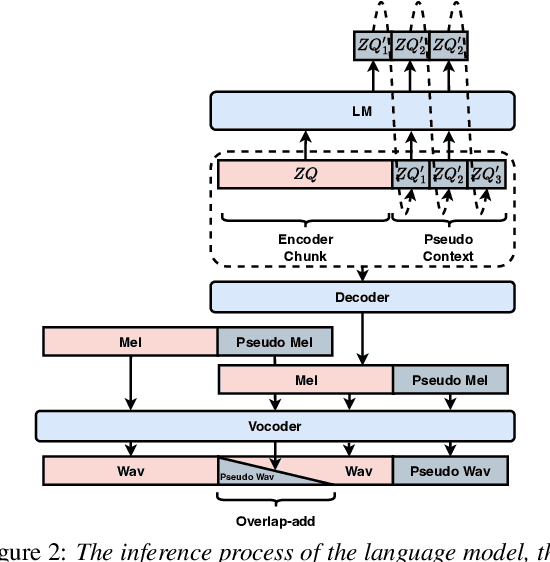
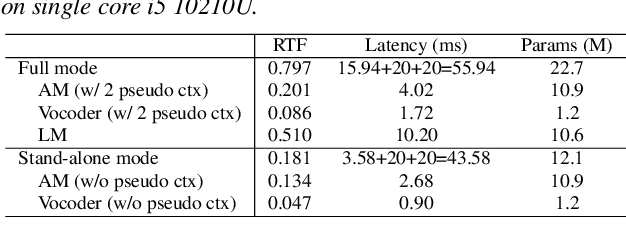
Streaming voice conversion has become increasingly popular for its potential in real-time applications. The recently proposed DualVC 2 has achieved robust and high-quality streaming voice conversion with a latency of about 180ms. Nonetheless, the recognition-synthesis framework hinders end-to-end optimization, and the instability of automatic speech recognition (ASR) model with short chunks makes it challenging to further reduce latency. To address these issues, we propose an end-to-end model, DualVC 3. With speaker-independent semantic tokens to guide the training of the content encoder, the dependency on ASR is removed and the model can operate under extremely small chunks, with cascading errors eliminated. A language model is trained on the content encoder output to produce pseudo context by iteratively predicting future frames, providing more contextual information for the decoder to improve conversion quality. Experimental results demonstrate that DualVC 3 achieves comparable performance to DualVC 2 in subjective and objective metrics, with a latency of only 50 ms.
EDTalk: Efficient Disentanglement for Emotional Talking Head Synthesis
Apr 02, 2024
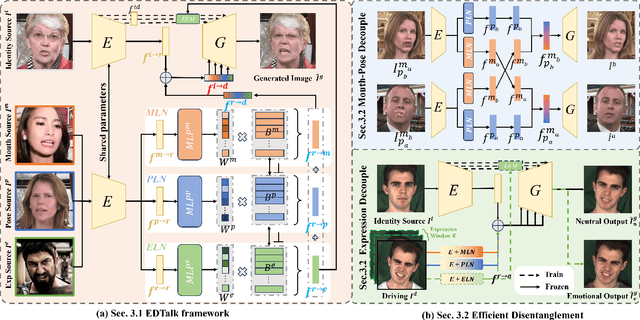
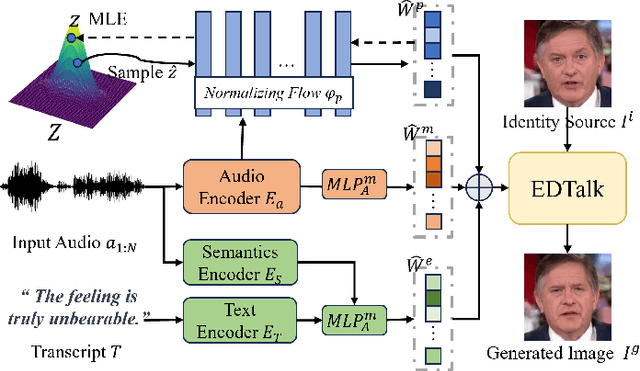

Achieving disentangled control over multiple facial motions and accommodating diverse input modalities greatly enhances the application and entertainment of the talking head generation. This necessitates a deep exploration of the decoupling space for facial features, ensuring that they a) operate independently without mutual interference and b) can be preserved to share with different modal input, both aspects often neglected in existing methods. To address this gap, this paper proposes a novel Efficient Disentanglement framework for Talking head generation (EDTalk). Our framework enables individual manipulation of mouth shape, head pose, and emotional expression, conditioned on video or audio inputs. Specifically, we employ three lightweight modules to decompose the facial dynamics into three distinct latent spaces representing mouth, pose, and expression, respectively. Each space is characterized by a set of learnable bases whose linear combinations define specific motions. To ensure independence and accelerate training, we enforce orthogonality among bases and devise an efficient training strategy to allocate motion responsibilities to each space without relying on external knowledge. The learned bases are then stored in corresponding banks, enabling shared visual priors with audio input. Furthermore, considering the properties of each space, we propose an Audio-to-Motion module for audio-driven talking head synthesis. Experiments are conducted to demonstrate the effectiveness of EDTalk. We recommend watching the project website: https://tanshuai0219.github.io/EDTalk/
DualVC 2: Dynamic Masked Convolution for Unified Streaming and Non-Streaming Voice Conversion
Sep 27, 2023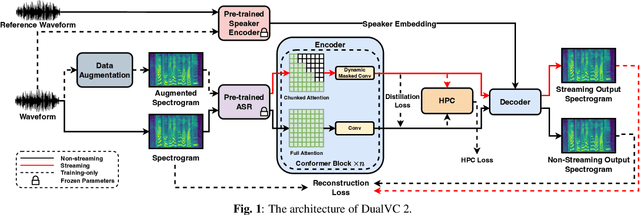
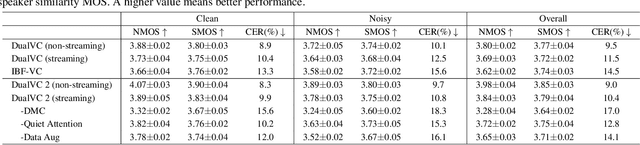
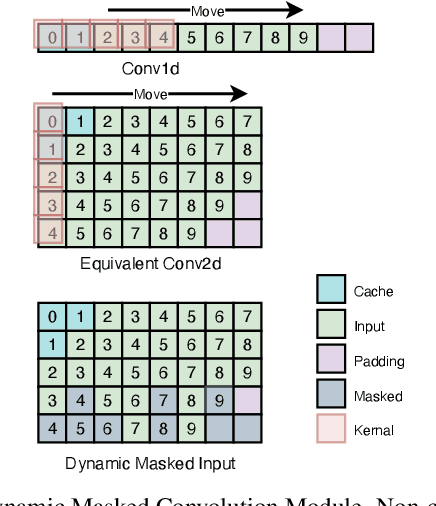
Voice conversion is becoming increasingly popular, and a growing number of application scenarios require models with streaming inference capabilities. The recently proposed DualVC attempts to achieve this objective through streaming model architecture design and intra-model knowledge distillation along with hybrid predictive coding to compensate for the lack of future information. However, DualVC encounters several problems that limit its performance. First, the autoregressive decoder has error accumulation in its nature and limits the inference speed as well. Second, the causal convolution enables streaming capability but cannot sufficiently use future information within chunks. Third, the model is unable to effectively address the noise in the unvoiced segments, lowering the sound quality. In this paper, we propose DualVC 2 to address these issues. Specifically, the model backbone is migrated to a Conformer-based architecture, empowering parallel inference. Causal convolution is replaced by non-causal convolution with dynamic chunk mask to make better use of within-chunk future information. Also, quiet attention is introduced to enhance the model's noise robustness. Experiments show that DualVC 2 outperforms DualVC and other baseline systems in both subjective and objective metrics, with only 186.4 ms latency. Our audio samples are made publicly available.