 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoIntent: An Egocentric Step-level Benchmark for Understanding What, Why, and Next
Mar 12, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable video reasoning capabilities across diverse tasks. However, their ability to understand human intent at a fine-grained level in egocentric videos remains largely unexplored. Existing benchmarks focus primarily on episode-level intent reasoning, overlooking the finer granularity of step-level intent understanding. Yet applications such as intelligent assistants, robotic imitation learning, and augmented reality guidance require understanding not only what a person is doing at each step, but also why and what comes next, in order to provide timely and context-aware support. To this end, we introduce EgoIntent, a step-level intent understanding benchmark for egocentric videos. It comprises 3,014 steps spanning 15 diverse indoor and outdoor daily-life scenarios, and evaluates models on three complementary dimensions: local intent (What), global intent (Why), and next-step plan (Next). Crucially, each clip is truncated immediately before the key outcome of the queried step (e.g., contact or grasp) occurs and contains no frames from subsequent steps, preventing future-frame leakage and enabling a clean evaluation of anticipatory step understanding and next-step planning. We evaluate 15 MLLMs, including both state-of-the-art closed-source and open-source models. Even the best-performing model achieves an average score of only 33.31 across the three intent dimensions, underscoring that step-level intent understanding in egocentric videos remains a highly challenging problem that calls for further investigation.
CausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding
Jan 29, 2026Although Multimodal Large Language Models (MLLMs) have shown remarkable potential in Visual Document Retrieval (VDR) through generating high-quality multi-vector embeddings, the substantial storage overhead caused by representing a page with thousands of visual tokens limits their practicality in real-world applications. To address this challenge, we propose an auto-regressive generation approach, CausalEmbed, for constructing multi-vector embeddings. By incorporating iterative margin loss during contrastive training, CausalEmbed encourages the embedding models to learn compact and well-structured representations. Our method enables efficient VDR tasks using only dozens of visual tokens, achieving a 30-155x reduction in token count while maintaining highly competitive performance across various backbones and benchmarks. Theoretical analysis and empirical results demonstrate the unique advantages of auto-regressive embedding generation in terms of training efficiency and scalability at test time. As a result, CausalEmbed introduces a flexible test-time scaling strategy for multi-vector VDR representations and sheds light on the generative paradigm within multimodal document retrieval.
ESGaussianFace: Emotional and Stylized Audio-Driven Facial Animation via 3D Gaussian Splatting
Jan 05, 2026Most current audio-driven facial animation research primarily focuses on generating videos with neutral emotions. While some studies have addressed the generation of facial videos driven by emotional audio, efficiently generating high-quality talking head videos that integrate both emotional expressions and style features remains a significant challenge. In this paper, we propose ESGaussianFace, an innovative framework for emotional and stylized audio-driven facial animation. Our approach leverages 3D Gaussian Splatting to reconstruct 3D scenes and render videos, ensuring efficient generation of 3D consistent results. We propose an emotion-audio-guided spatial attention method that effectively integrates emotion features with audio content features. Through emotion-guided attention, the model is able to reconstruct facial details across different emotional states more accurately. To achieve emotional and stylized deformations of the 3D Gaussian points through emotion and style features, we introduce two 3D Gaussian deformation predictors. Futhermore, we propose a multi-stage training strategy, enabling the step-by-step learning of the character's lip movements, emotional variations, and style features. Our generated results exhibit high efficiency, high quality, and 3D consistency. Extensive experimental results demonstrate that our method outperforms existing state-of-the-art techniques in terms of lip movement accuracy, expression variation, and style feature expressiveness.
MienCap: Realtime Performance-Based Facial Animation with Live Mood Dynamics
Aug 06, 2025



Our purpose is to improve performance-based animation which can drive believable 3D stylized characters that are truly perceptual. By combining traditional blendshape animation techniques with multiple machine learning models, we present both non-real time and real time solutions which drive character expressions in a geometrically consistent and perceptually valid way. For the non-real time system, we propose a 3D emotion transfer network makes use of a 2D human image to generate a stylized 3D rig parameters. For the real time system, we propose a blendshape adaption network which generates the character rig parameter motions with geometric consistency and temporally stability. We demonstrate the effectiveness of our system by comparing to a commercial product Faceware. Results reveal that ratings of the recognition, intensity, and attractiveness of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the animation pipeline, and provide animators with a system for creating the expressions they wish to use more quickly and accurately.
MEDTalk: Multimodal Controlled 3D Facial Animation with Dynamic Emotions by Disentangled Embedding
Jul 08, 2025



Audio-driven emotional 3D facial animation aims to generate synchronized lip movements and vivid facial expressions. However, most existing approaches focus on static and predefined emotion labels, limiting their diversity and naturalness. To address these challenges, we propose MEDTalk, a novel framework for fine-grained and dynamic emotional talking head generation. Our approach first disentangles content and emotion embedding spaces from motion sequences using a carefully designed cross-reconstruction process, enabling independent control over lip movements and facial expressions. Beyond conventional audio-driven lip synchronization, we integrate audio and speech text, predicting frame-wise intensity variations and dynamically adjusting static emotion features to generate realistic emotional expressions. Furthermore, to enhance control and personalization, we incorporate multimodal inputs-including text descriptions and reference expression images-to guide the generation of user-specified facial expressions. With MetaHuman as the priority, our generated results can be conveniently integrated into the industrial production pipeline.
FixTalk: Taming Identity Leakage for High-Quality Talking Head Generation in Extreme Cases
Jul 02, 2025Talking head generation is gaining significant importance across various domains, with a growing demand for high-quality rendering. However, existing methods often suffer from identity leakage (IL) and rendering artifacts (RA), particularly in extreme cases. Through an in-depth analysis of previous approaches, we identify two key insights: (1) IL arises from identity information embedded within motion features, and (2) this identity information can be leveraged to address RA. Building on these findings, this paper introduces FixTalk, a novel framework designed to simultaneously resolve both issues for high-quality talking head generation. Firstly, we propose an Enhanced Motion Indicator (EMI) to effectively decouple identity information from motion features, mitigating the impact of IL on generated talking heads. To address RA, we introduce an Enhanced Detail Indicator (EDI), which utilizes the leaked identity information to supplement missing details, thus fixing the artifacts. Extensive experiments demonstrate that FixTalk effectively mitigates IL and RA, achieving superior performance compared to state-of-the-art methods.
EmoFace: Audio-driven Emotional 3D Face Animation
Jul 17, 2024



Audio-driven emotional 3D face animation aims to generate emotionally expressive talking heads with synchronized lip movements. However, previous research has often overlooked the influence of diverse emotions on facial expressions or proved unsuitable for driving MetaHuman models. In response to this deficiency, we introduce EmoFace, a novel audio-driven methodology for creating facial animations with vivid emotional dynamics. Our approach can generate facial expressions with multiple emotions, and has the ability to generate random yet natural blinks and eye movements, while maintaining accurate lip synchronization. We propose independent speech encoders and emotion encoders to learn the relationship between audio, emotion and corresponding facial controller rigs, and finally map into the sequence of controller values. Additionally, we introduce two post-processing techniques dedicated to enhancing the authenticity of the animation, particularly in blinks and eye movements. Furthermore, recognizing the scarcity of emotional audio-visual data suitable for MetaHuman model manipulation, we contribute an emotional audio-visual dataset and derive control parameters for each frames. Our proposed methodology can be applied in producing dialogues animations of non-playable characters (NPCs) in video games, and driving avatars in virtual reality environments. Our further quantitative and qualitative experiments, as well as an user study comparing with existing researches show that our approach demonstrates superior results in driving 3D facial models. The code and sample data are available at https://github.com/SJTU-Lucy/EmoFace.
Cost-Effective RF Fingerprinting Based on Hybrid CVNN-RF Classifier with Automated Multi-Dimensional Early-Exit Strategy
Jun 21, 2024



While the Internet of Things (IoT) technology is booming and offers huge opportunities for information exchange, it also faces unprecedented security challenges. As an important complement to the physical layer security technologies for IoT, radio frequency fingerprinting (RFF) is of great interest due to its difficulty in counterfeiting. Recently, many machine learning (ML)-based RFF algorithms have emerged. In particular, deep learning (DL) has shown great benefits in automatically extracting complex and subtle features from raw data with high classification accuracy. However, DL algorithms face the computational cost problem as the difficulty of the RFF task and the size of the DNN have increased dramatically. To address the above challenge, this paper proposes a novel costeffective early-exit neural network consisting of a complex-valued neural network (CVNN) backbone with multiple random forest branches, called hybrid CVNN-RF. Unlike conventional studies that use a single fixed DL model to process all RF samples, our hybrid CVNN-RF considers differences in the recognition difficulty of RF samples and introduces an early-exit mechanism to dynamically process the samples. When processing "easy" samples that can be well classified with high confidence, the hybrid CVNN-RF can end early at the random forest branch to reduce computational cost. Conversely, subsequent network layers will be activated to ensure accuracy. To further improve the early-exit rate, an automated multi-dimensional early-exit strategy is proposed to achieve scheduling control from multiple dimensions within the network depth and classification category. Finally, our experiments on the public ADS-B dataset show that the proposed algorithm can reduce the computational cost by 83% while improving the accuracy by 1.6% under a classification task with 100 categories.
LR-FPN: Enhancing Remote Sensing Object Detection with Location Refined Feature Pyramid Network
Apr 02, 2024Remote sensing target detection aims to identify and locate critical targets within remote sensing images, finding extensive applications in agriculture and urban planning. Feature pyramid networks (FPNs) are commonly used to extract multi-scale features. However, existing FPNs often overlook extracting low-level positional information and fine-grained context interaction. To address this, we propose a novel location refined feature pyramid network (LR-FPN) to enhance the extraction of shallow positional information and facilitate fine-grained context interaction. The LR-FPN consists of two primary modules: the shallow position information extraction module (SPIEM) and the contextual interaction module (CIM). Specifically, SPIEM first maximizes the retention of solid location information of the target by simultaneously extracting positional and saliency information from the low-level feature map. Subsequently, CIM injects this robust location information into different layers of the original FPN through spatial and channel interaction, explicitly enhancing the object area. Moreover, in spatial interaction, we introduce a simple local and non-local interaction strategy to learn and retain the saliency information of the object. Lastly, the LR-FPN can be readily integrated into common object detection frameworks to improve performance significantly. Extensive experiments on two large-scale remote sensing datasets (i.e., DOTAV1.0 and HRSC2016) demonstrate that the proposed LR-FPN is superior to state-of-the-art object detection approaches. Our code and models will be publicly available.
EDTalk: Efficient Disentanglement for Emotional Talking Head Synthesis
Apr 02, 2024
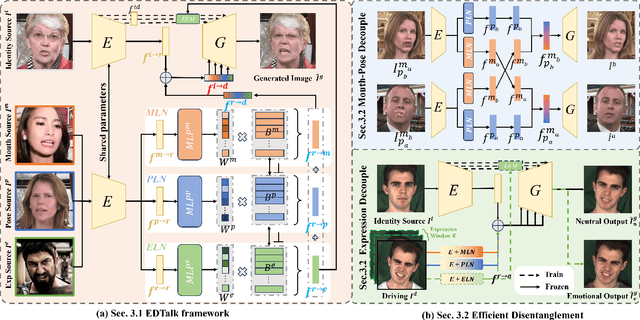
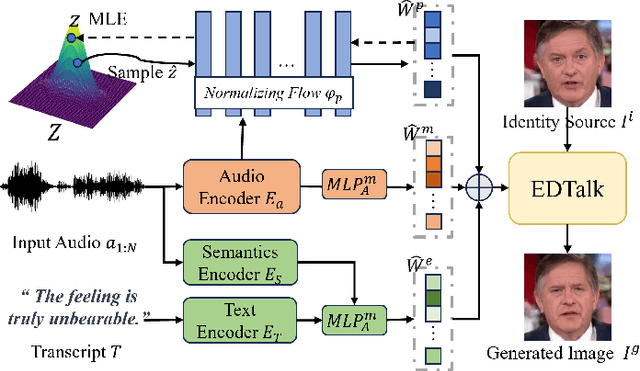

Achieving disentangled control over multiple facial motions and accommodating diverse input modalities greatly enhances the application and entertainment of the talking head generation. This necessitates a deep exploration of the decoupling space for facial features, ensuring that they a) operate independently without mutual interference and b) can be preserved to share with different modal input, both aspects often neglected in existing methods. To address this gap, this paper proposes a novel Efficient Disentanglement framework for Talking head generation (EDTalk). Our framework enables individual manipulation of mouth shape, head pose, and emotional expression, conditioned on video or audio inputs. Specifically, we employ three lightweight modules to decompose the facial dynamics into three distinct latent spaces representing mouth, pose, and expression, respectively. Each space is characterized by a set of learnable bases whose linear combinations define specific motions. To ensure independence and accelerate training, we enforce orthogonality among bases and devise an efficient training strategy to allocate motion responsibilities to each space without relying on external knowledge. The learned bases are then stored in corresponding banks, enabling shared visual priors with audio input. Furthermore, considering the properties of each space, we propose an Audio-to-Motion module for audio-driven talking head synthesis. Experiments are conducted to demonstrate the effectiveness of EDTalk. We recommend watching the project website: https://tanshuai0219.github.io/EDTalk/