 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder Gradient Shields: A Family of Provable and High-Fidelity Methods Against Gradient-Based Box-Free Watermark Removal
Jan 17, 2026Box-free model watermarking has gained significant attention in deep neural network (DNN) intellectual property protection due to its model-agnostic nature and its ability to flexibly manage high-entropy image outputs from generative models. Typically operating in a black-box manner, it employs an encoder-decoder framework for watermark embedding and extraction. While existing research has focused primarily on the encoders for the robustness to resist various attacks, the decoders have been largely overlooked, leading to attacks against the watermark. In this paper, we identify one such attack against the decoder, where query responses are utilized to obtain backpropagated gradients to train a watermark remover. To address this issue, we propose Decoder Gradient Shields (DGSs), a family of defense mechanisms, including DGS at the output (DGS-O), at the input (DGS-I), and in the layers (DGS-L) of the decoder, with a closed-form solution for DGS-O and provable performance for all DGS. Leveraging the joint design of reorienting and rescaling of the gradients from watermark channel gradient leaking queries, the proposed DGSs effectively prevent the watermark remover from achieving training convergence to the desired low-loss value, while preserving image quality of the decoder output. We demonstrate the effectiveness of our proposed DGSs in diverse application scenarios. Our experimental results on deraining and image generation tasks with the state-of-the-art box-free watermarking show that our DGSs achieve a defense success rate of 100% under all settings.
DiffPixelFormer: Differential Pixel-Aware Transformer for RGB-D Indoor Scene Segmentation
Nov 17, 2025Indoor semantic segmentation is fundamental to computer vision and robotics, supporting applications such as autonomous navigation, augmented reality, and smart environments. Although RGB-D fusion leverages complementary appearance and geometric cues, existing methods often depend on computationally intensive cross-attention mechanisms and insufficiently model intra- and inter-modal feature relationships, resulting in imprecise feature alignment and limited discriminative representation. To address these challenges, we propose DiffPixelFormer, a differential pixel-aware Transformer for RGB-D indoor scene segmentation that simultaneously enhances intra-modal representations and models inter-modal interactions. At its core, the Intra-Inter Modal Interaction Block (IIMIB) captures intra-modal long-range dependencies via self-attention and models inter-modal interactions with the Differential-Shared Inter-Modal (DSIM) module to disentangle modality-specific and shared cues, enabling fine-grained, pixel-level cross-modal alignment. Furthermore, a dynamic fusion strategy balances modality contributions and fully exploits RGB-D information according to scene characteristics. Extensive experiments on the SUN RGB-D and NYUDv2 benchmarks demonstrate that DiffPixelFormer-L achieves mIoU scores of 54.28% and 59.95%, outperforming DFormer-L by 1.78% and 2.75%, respectively. Code is available at https://github.com/gongyan1/DiffPixelFormer.
Progressive Bird's Eye View Perception for Safety-Critical Autonomous Driving: A Comprehensive Survey
Aug 11, 2025Bird's-Eye-View (BEV) perception has become a foundational paradigm in autonomous driving, enabling unified spatial representations that support robust multi-sensor fusion and multi-agent collaboration. As autonomous vehicles transition from controlled environments to real-world deployment, ensuring the safety and reliability of BEV perception in complex scenarios - such as occlusions, adverse weather, and dynamic traffic - remains a critical challenge. This survey provides the first comprehensive review of BEV perception from a safety-critical perspective, systematically analyzing state-of-the-art frameworks and implementation strategies across three progressive stages: single-modality vehicle-side, multimodal vehicle-side, and multi-agent collaborative perception. Furthermore, we examine public datasets encompassing vehicle-side, roadside, and collaborative settings, evaluating their relevance to safety and robustness. We also identify key open-world challenges - including open-set recognition, large-scale unlabeled data, sensor degradation, and inter-agent communication latency - and outline future research directions, such as integration with end-to-end autonomous driving systems, embodied intelligence, and large language models.
Bootstrap Deep Spectral Clustering with Optimal Transport
Aug 06, 2025Spectral clustering is a leading clustering method. Two of its major shortcomings are the disjoint optimization process and the limited representation capacity. To address these issues, we propose a deep spectral clustering model (named BootSC), which jointly learns all stages of spectral clustering -- affinity matrix construction, spectral embedding, and $k$-means clustering -- using a single network in an end-to-end manner. BootSC leverages effective and efficient optimal-transport-derived supervision to bootstrap the affinity matrix and the cluster assignment matrix. Moreover, a semantically-consistent orthogonal re-parameterization technique is introduced to orthogonalize spectral embeddings, significantly enhancing the discrimination capability. Experimental results indicate that BootSC achieves state-of-the-art clustering performance. For example, it accomplishes a notable 16\% NMI improvement over the runner-up method on the challenging ImageNet-Dogs dataset. Our code is available at https://github.com/spdj2271/BootSC.
NWaaS: Nonintrusive Watermarking as a Service for X-to-Image DNN
Jul 24, 2025The intellectual property of deep neural network (DNN) models can be protected with DNN watermarking, which embeds copyright watermarks into model parameters (white-box), model behavior (black-box), or model outputs (box-free), and the watermarks can be subsequently extracted to verify model ownership or detect model theft. Despite recent advances, these existing methods are inherently intrusive, as they either modify the model parameters or alter the structure. This natural intrusiveness raises concerns about watermarking-induced shifts in model behavior and the additional cost of fine-tuning, further exacerbated by the rapidly growing model size. As a result, model owners are often reluctant to adopt DNN watermarking in practice, which limits the development of practical Watermarking as a Service (WaaS) systems. To address this issue, we introduce Nonintrusive Watermarking as a Service (NWaaS), a novel trustless paradigm designed for X-to-Image models, in which we hypothesize that with the model untouched, an owner-defined watermark can still be extracted from model outputs. Building on this concept, we propose ShadowMark, a concrete implementation of NWaaS which addresses critical deployment challenges by establishing a robust and nonintrusive side channel in the protected model's black-box API, leveraging a key encoder and a watermark decoder. It is significantly distinctive from existing solutions by attaining the so-called absolute fidelity and being applicable to different DNN architectures, while being also robust against existing attacks, eliminating the fidelity-robustness trade-off. Extensive experiments on image-to-image, noise-to-image, noise-and-text-to-image, and text-to-image models, demonstrate the efficacy and practicality of ShadowMark for real-world deployment of nonintrusive DNN watermarking.
MEDTalk: Multimodal Controlled 3D Facial Animation with Dynamic Emotions by Disentangled Embedding
Jul 08, 2025



Audio-driven emotional 3D facial animation aims to generate synchronized lip movements and vivid facial expressions. However, most existing approaches focus on static and predefined emotion labels, limiting their diversity and naturalness. To address these challenges, we propose MEDTalk, a novel framework for fine-grained and dynamic emotional talking head generation. Our approach first disentangles content and emotion embedding spaces from motion sequences using a carefully designed cross-reconstruction process, enabling independent control over lip movements and facial expressions. Beyond conventional audio-driven lip synchronization, we integrate audio and speech text, predicting frame-wise intensity variations and dynamically adjusting static emotion features to generate realistic emotional expressions. Furthermore, to enhance control and personalization, we incorporate multimodal inputs-including text descriptions and reference expression images-to guide the generation of user-specified facial expressions. With MetaHuman as the priority, our generated results can be conveniently integrated into the industrial production pipeline.
MAP: Revisiting Weight Decomposition for Low-Rank Adaptation
May 29, 2025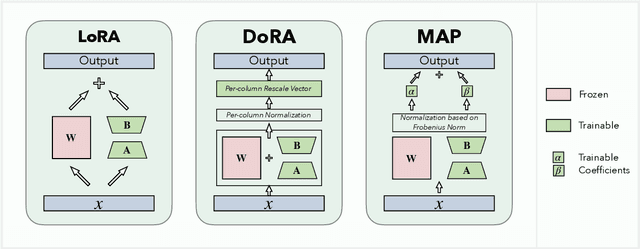
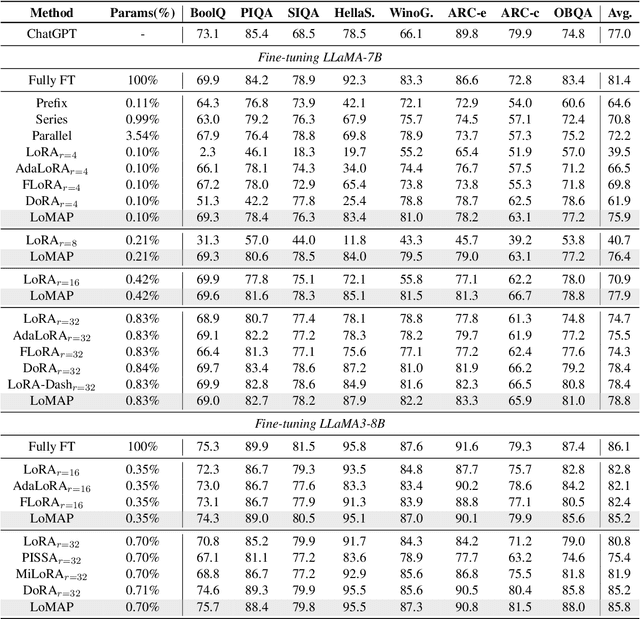
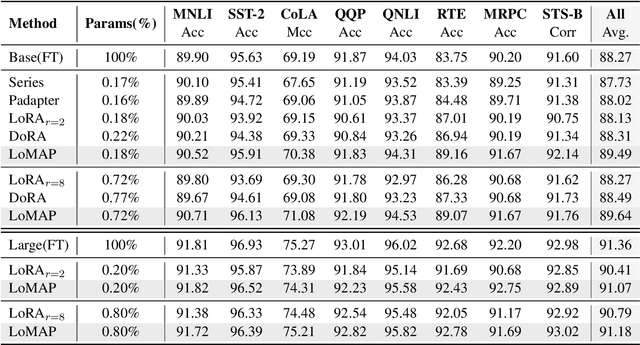

The rapid development of large language models has revolutionized natural language processing, but their fine-tuning remains computationally expensive, hindering broad deployment. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, have emerged as solutions. Recent work like DoRA attempts to further decompose weight adaptation into direction and magnitude components. However, existing formulations often define direction heuristically at the column level, lacking a principled geometric foundation. In this paper, we propose MAP, a novel framework that reformulates weight matrices as high-dimensional vectors and decouples their adaptation into direction and magnitude in a rigorous manner. MAP normalizes the pre-trained weights, learns a directional update, and introduces two scalar coefficients to independently scale the magnitude of the base and update vectors. This design enables more interpretable and flexible adaptation, and can be seamlessly integrated into existing PEFT methods. Extensive experiments show that MAP significantly improves performance when coupling with existing methods, offering a simple yet powerful enhancement to existing PEFT methods. Given the universality and simplicity of MAP, we hope it can serve as a default setting for designing future PEFT methods.
QArtSR: Quantization via Reverse-Module and Timestep-Retraining in One-Step Diffusion based Image Super-Resolution
Mar 07, 2025
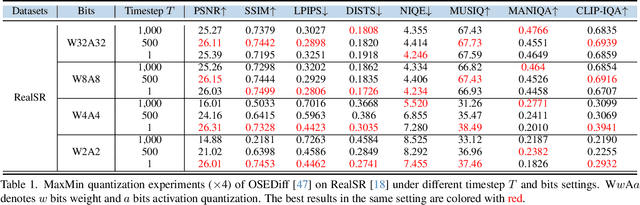
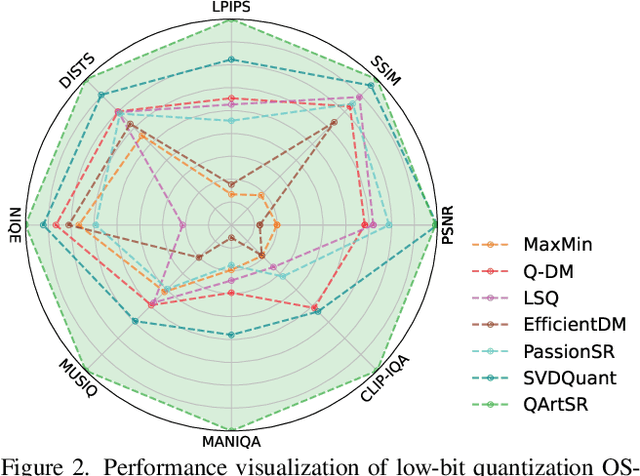
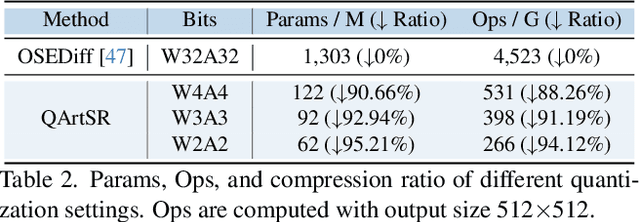
One-step diffusion-based image super-resolution (OSDSR) models are showing increasingly superior performance nowadays. However, although their denoising steps are reduced to one and they can be quantized to 8-bit to reduce the costs further, there is still significant potential for OSDSR to quantize to lower bits. To explore more possibilities of quantized OSDSR, we propose an efficient method, Quantization via reverse-module and timestep-retraining for OSDSR, named QArtSR. Firstly, we investigate the influence of timestep value on the performance of quantized models. Then, we propose Timestep Retraining Quantization (TRQ) and Reversed Per-module Quantization (RPQ) strategies to calibrate the quantized model. Meanwhile, we adopt the module and image losses to update all quantized modules. We only update the parameters in quantization finetuning components, excluding the original weights. To ensure that all modules are fully finetuned, we add extended end-to-end training after per-module stage. Our 4-bit and 2-bit quantization experimental results indicate that QArtSR obtains superior effects against the recent leading comparison methods. The performance of 4-bit QArtSR is close to the full-precision one. Our code will be released at https://github.com/libozhu03/QArtSR.
Decoder Gradient Shield: Provable and High-Fidelity Prevention of Gradient-Based Box-Free Watermark Removal
Feb 28, 2025



The intellectual property of deep image-to-image models can be protected by the so-called box-free watermarking. It uses an encoder and a decoder, respectively, to embed into and extract from the model's output images invisible copyright marks. Prior works have improved watermark robustness, focusing on the design of better watermark encoders. In this paper, we reveal an overlooked vulnerability of the unprotected watermark decoder which is jointly trained with the encoder and can be exploited to train a watermark removal network. To defend against such an attack, we propose the decoder gradient shield (DGS) as a protection layer in the decoder API to prevent gradient-based watermark removal with a closed-form solution. The fundamental idea is inspired by the classical adversarial attack, but is utilized for the first time as a defensive mechanism in the box-free model watermarking. We then demonstrate that DGS can reorient and rescale the gradient directions of watermarked queries and stop the watermark remover's training loss from converging to the level without DGS, while retaining decoder output image quality. Experimental results verify the effectiveness of proposed method. Code of paper will be made available upon acceptance.
Weakly-supervised anomaly detection for multimodal data distributions
Jun 13, 2024



Weakly-supervised anomaly detection can outperform existing unsupervised methods with the assistance of a very small number of labeled anomalies, which attracts increasing attention from researchers. However, existing weakly-supervised anomaly detection methods are limited as these methods do not factor in the multimodel nature of the real-world data distribution. To mitigate this, we propose the Weakly-supervised Variational-mixture-model-based Anomaly Detector (WVAD). WVAD excels in multimodal datasets. It consists of two components: a deep variational mixture model, and an anomaly score estimator. The deep variational mixture model captures various features of the data from different clusters, then these features are delivered to the anomaly score estimator to assess the anomaly levels. Experimental results on three real-world datasets demonstrate WVAD's superiority.