 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Poisoning Attacks against Retrieval-Augmented Generation
May 24, 2025


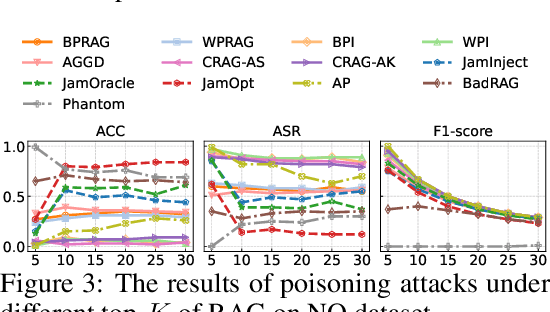
Retrieval-Augmented Generation (RAG) has proven effective in mitigating hallucinations in large language models by incorporating external knowledge during inference. However, this integration introduces new security vulnerabilities, particularly to poisoning attacks. Although prior work has explored various poisoning strategies, a thorough assessment of their practical threat to RAG systems remains missing. To address this gap, we propose the first comprehensive benchmark framework for evaluating poisoning attacks on RAG. Our benchmark covers 5 standard question answering (QA) datasets and 10 expanded variants, along with 13 poisoning attack methods and 7 defense mechanisms, representing a broad spectrum of existing techniques. Using this benchmark, we conduct a comprehensive evaluation of all included attacks and defenses across the full dataset spectrum. Our findings show that while existing attacks perform well on standard QA datasets, their effectiveness drops significantly on the expanded versions. Moreover, our results demonstrate that various advanced RAG architectures, such as sequential, branching, conditional, and loop RAG, as well as multi-turn conversational RAG, multimodal RAG systems, and RAG-based LLM agent systems, remain susceptible to poisoning attacks. Notably, current defense techniques fail to provide robust protection, underscoring the pressing need for more resilient and generalizable defense strategies.
Sound event localization and classification using WASN in Outdoor Environment
Mar 29, 2024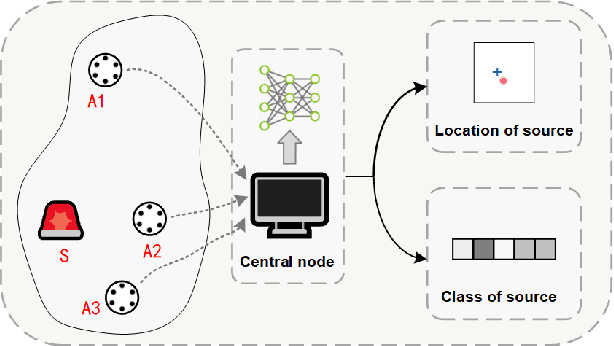
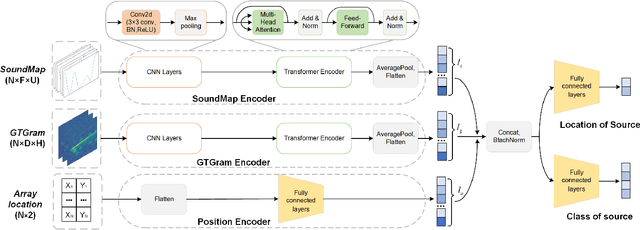
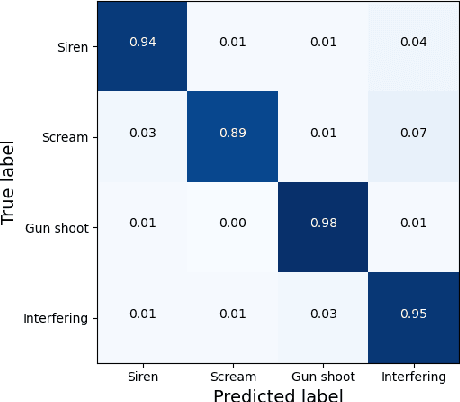
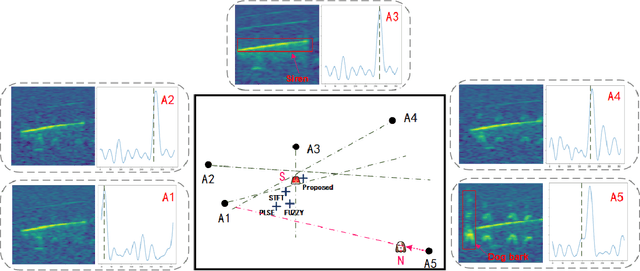
Deep learning-based sound event localization and classification is an emerging research area within wireless acoustic sensor networks. However, current methods for sound event localization and classification typically rely on a single microphone array, making them susceptible to signal attenuation and environmental noise, which limits their monitoring range. Moreover, methods using multiple microphone arrays often focus solely on source localization, neglecting the aspect of sound event classification. In this paper, we propose a deep learning-based method that employs multiple features and attention mechanisms to estimate the location and class of sound source. We introduce a Soundmap feature to capture spatial information across multiple frequency bands. We also use the Gammatone filter to generate acoustic features more suitable for outdoor environments. Furthermore, we integrate attention mechanisms to learn channel-wise relationships and temporal dependencies within the acoustic features. To evaluate our proposed method, we conduct experiments using simulated datasets with different levels of noise and size of monitoring areas, as well as different arrays and source positions. The experimental results demonstrate the superiority of our proposed method over state-of-the-art methods in both sound event classification and sound source localization tasks. And we provide further analysis to explain the reasons for the observed errors.
Description on IEEE ICME 2024 Grand Challenge: Semi-supervised Acoustic Scene Classification under Domain Shift
Feb 05, 2024
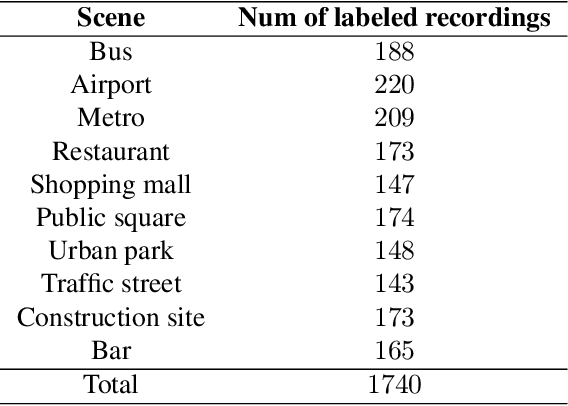

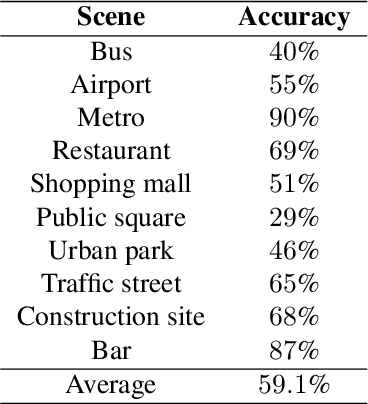
Acoustic scene classification (ASC) is a crucial research problem in computational auditory scene analysis, and it aims to recognize the unique acoustic characteristics of an environment. One of the challenges of the ASC task is domain shift caused by a distribution gap between training and testing data. Since 2018, ASC challenges have focused on the generalization of ASC models across different recording devices. Although this task in recent years has achieved substantial progress in device generalization, the challenge of domain shift between different regions, involving characteristics such as time, space, culture, and language, remains insufficiently explored at present. In addition, considering the abundance of unlabeled acoustic scene data in the real world, it is important to study the possible ways to utilize these unlabelled data. Therefore, we introduce the task Semi-supervised Acoustic Scene Classification under Domain Shift in the ICME 2024 Grand Challenge. We encourage participants to innovate with semi-supervised learning techniques, aiming to develop more robust ASC models under domain shift.
Dynamic Kernel Convolution Network with Scene-dedicate Training for Sound Event Localization and Detection
Jul 17, 2023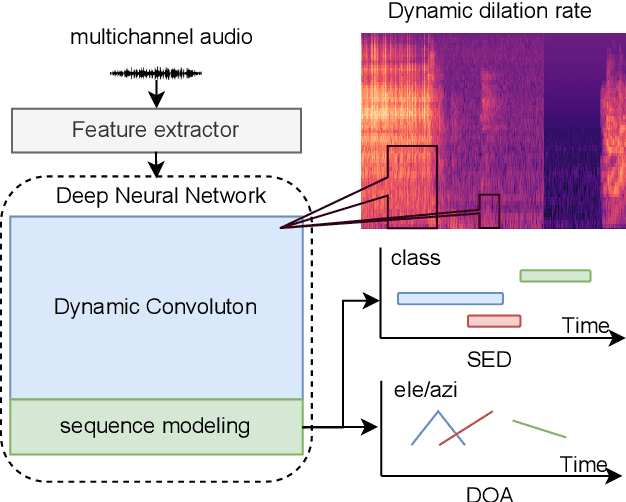
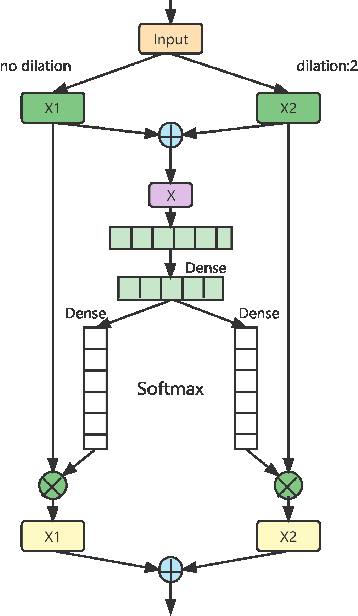
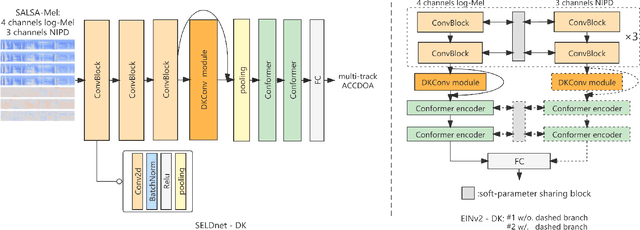
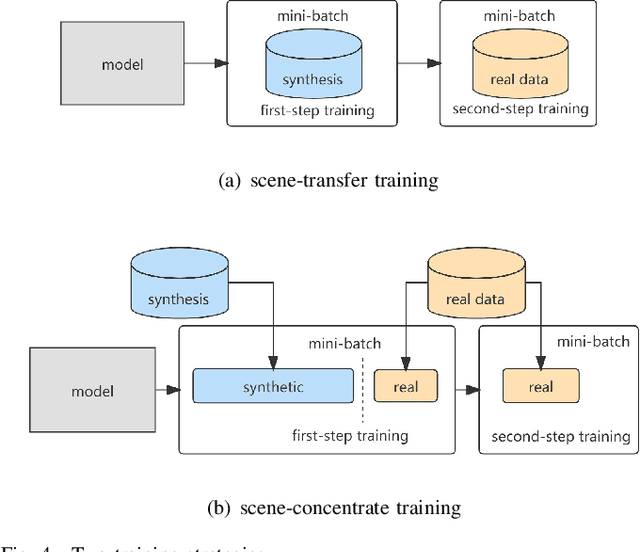
DNN-based methods have shown high performance in sound event localization and detection(SELD). While in real spatial sound scenes, reverberation and the imbalanced presence of various sound events increase the complexity of the SELD task. In this paper, we propose an effective SELD system in real spatial scenes.In our approach, a dynamic kernel convolution module is introduced after the convolution blocks to adaptively model the channel-wise features with different receptive fields. Secondly, we incorporate the SELDnet and EINv2 framework into the proposed SELD system with multi-track ACCDOA. Moreover, two scene-dedicated strategies are introduced into the training stage to improve the generalization of the system in realistic spatial sound scenes. Finally, we apply data augmentation methods to extend the dataset using channel rotation, spatial data synthesis. Four joint metrics are used to evaluate the performance of the SELD system on the Sony-TAu Realistic Spatial Soundscapes 2022 dataset.Experimental results show that the proposed systems outperform the fixed-kernel convolution SELD systems. In addition, the proposed system achieved an SELD score of 0.348 in the DCASE SELD task and surpassed the SOTA methods.