 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecureSplit: Mitigating Backdoor Attacks in Split Learning
Jan 20, 2026Split Learning (SL) offers a framework for collaborative model training that respects data privacy by allowing participants to share the same dataset while maintaining distinct feature sets. However, SL is susceptible to backdoor attacks, in which malicious clients subtly alter their embeddings to insert hidden triggers that compromise the final trained model. To address this vulnerability, we introduce SecureSplit, a defense mechanism tailored to SL. SecureSplit applies a dimensionality transformation strategy to accentuate subtle differences between benign and poisoned embeddings, facilitating their separation. With this enhanced distinction, we develop an adaptive filtering approach that uses a majority-based voting scheme to remove contaminated embeddings while preserving clean ones. Rigorous experiments across four datasets (CIFAR-10, MNIST, CINIC-10, and ImageNette), five backdoor attack scenarios, and seven alternative defenses confirm the effectiveness of SecureSplit under various challenging conditions.
Practical Framework for Privacy-Preserving and Byzantine-robust Federated Learning
Dec 19, 2025Federated Learning (FL) allows multiple clients to collaboratively train a model without sharing their private data. However, FL is vulnerable to Byzantine attacks, where adversaries manipulate client models to compromise the federated model, and privacy inference attacks, where adversaries exploit client models to infer private data. Existing defenses against both backdoor and privacy inference attacks introduce significant computational and communication overhead, creating a gap between theory and practice. To address this, we propose ABBR, a practical framework for Byzantine-robust and privacy-preserving FL. We are the first to utilize dimensionality reduction to speed up the private computation of complex filtering rules in privacy-preserving FL. Additionally, we analyze the accuracy loss of vector-wise filtering in low-dimensional space and introduce an adaptive tuning strategy to minimize the impact of malicious models that bypass filtering on the global model. We implement ABBR with state-of-the-art Byzantine-robust aggregation rules and evaluate it on public datasets, showing that it runs significantly faster, has minimal communication overhead, and maintains nearly the same Byzantine-resilience as the baselines.
Enhancing Privacy in Decentralized Min-Max Optimization: A Differentially Private Approach
Aug 10, 2025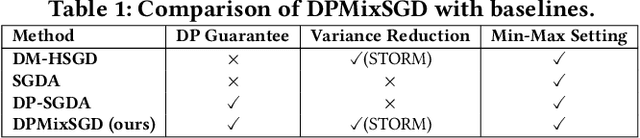

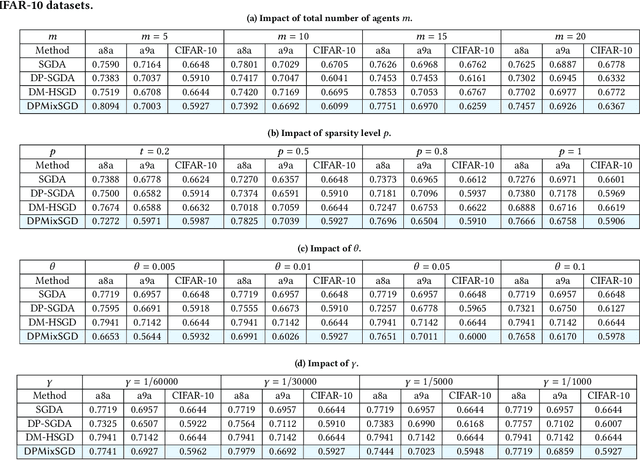

Decentralized min-max optimization allows multi-agent systems to collaboratively solve global min-max optimization problems by facilitating the exchange of model updates among neighboring agents, eliminating the need for a central server. However, sharing model updates in such systems carry a risk of exposing sensitive data to inference attacks, raising significant privacy concerns. To mitigate these privacy risks, differential privacy (DP) has become a widely adopted technique for safeguarding individual data. Despite its advantages, implementing DP in decentralized min-max optimization poses challenges, as the added noise can hinder convergence, particularly in non-convex scenarios with complex agent interactions in min-max optimization problems. In this work, we propose an algorithm called DPMixSGD (Differential Private Minmax Hybrid Stochastic Gradient Descent), a novel privacy-preserving algorithm specifically designed for non-convex decentralized min-max optimization. Our method builds on the state-of-the-art STORM-based algorithm, one of the fastest decentralized min-max solutions. We rigorously prove that the noise added to local gradients does not significantly compromise convergence performance, and we provide theoretical bounds to ensure privacy guarantees. To validate our theoretical findings, we conduct extensive experiments across various tasks and models, demonstrating the effectiveness of our approach.
Benchmarking Poisoning Attacks against Retrieval-Augmented Generation
May 24, 2025


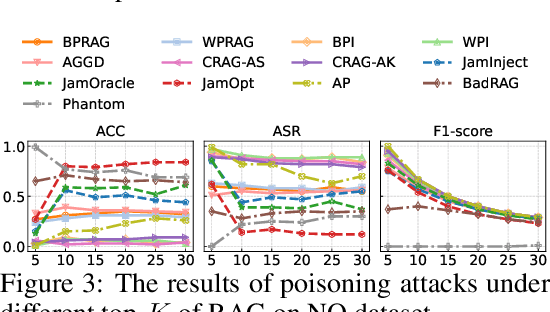
Retrieval-Augmented Generation (RAG) has proven effective in mitigating hallucinations in large language models by incorporating external knowledge during inference. However, this integration introduces new security vulnerabilities, particularly to poisoning attacks. Although prior work has explored various poisoning strategies, a thorough assessment of their practical threat to RAG systems remains missing. To address this gap, we propose the first comprehensive benchmark framework for evaluating poisoning attacks on RAG. Our benchmark covers 5 standard question answering (QA) datasets and 10 expanded variants, along with 13 poisoning attack methods and 7 defense mechanisms, representing a broad spectrum of existing techniques. Using this benchmark, we conduct a comprehensive evaluation of all included attacks and defenses across the full dataset spectrum. Our findings show that while existing attacks perform well on standard QA datasets, their effectiveness drops significantly on the expanded versions. Moreover, our results demonstrate that various advanced RAG architectures, such as sequential, branching, conditional, and loop RAG, as well as multi-turn conversational RAG, multimodal RAG systems, and RAG-based LLM agent systems, remain susceptible to poisoning attacks. Notably, current defense techniques fail to provide robust protection, underscoring the pressing need for more resilient and generalizable defense strategies.
Toward Malicious Clients Detection in Federated Learning
May 14, 2025Federated learning (FL) enables multiple clients to collaboratively train a global machine learning model without sharing their raw data. However, the decentralized nature of FL introduces vulnerabilities, particularly to poisoning attacks, where malicious clients manipulate their local models to disrupt the training process. While Byzantine-robust aggregation rules have been developed to mitigate such attacks, they remain inadequate against more advanced threats. In response, recent advancements have focused on FL detection techniques to identify potentially malicious participants. Unfortunately, these methods often misclassify numerous benign clients as threats or rely on unrealistic assumptions about the server's capabilities. In this paper, we propose a novel algorithm, SafeFL, specifically designed to accurately identify malicious clients in FL. The SafeFL approach involves the server collecting a series of global models to generate a synthetic dataset, which is then used to distinguish between malicious and benign models based on their behavior. Extensive testing demonstrates that SafeFL outperforms existing methods, offering superior efficiency and accuracy in detecting malicious clients.
Traceback of Poisoning Attacks to Retrieval-Augmented Generation
Apr 30, 2025



Large language models (LLMs) integrated with retrieval-augmented generation (RAG) systems improve accuracy by leveraging external knowledge sources. However, recent research has revealed RAG's susceptibility to poisoning attacks, where the attacker injects poisoned texts into the knowledge database, leading to attacker-desired responses. Existing defenses, which predominantly focus on inference-time mitigation, have proven insufficient against sophisticated attacks. In this paper, we introduce RAGForensics, the first traceback system for RAG, designed to identify poisoned texts within the knowledge database that are responsible for the attacks. RAGForensics operates iteratively, first retrieving a subset of texts from the database and then utilizing a specially crafted prompt to guide an LLM in detecting potential poisoning texts. Empirical evaluations across multiple datasets demonstrate the effectiveness of RAGForensics against state-of-the-art poisoning attacks. This work pioneers the traceback of poisoned texts in RAG systems, providing a practical and promising defense mechanism to enhance their security.
Practical Poisoning Attacks against Retrieval-Augmented Generation
Apr 04, 2025Large language models (LLMs) have demonstrated impressive natural language processing abilities but face challenges such as hallucination and outdated knowledge. Retrieval-Augmented Generation (RAG) has emerged as a state-of-the-art approach to mitigate these issues. While RAG enhances LLM outputs, it remains vulnerable to poisoning attacks. Recent studies show that injecting poisoned text into the knowledge database can compromise RAG systems, but most existing attacks assume that the attacker can insert a sufficient number of poisoned texts per query to outnumber correct-answer texts in retrieval, an assumption that is often unrealistic. To address this limitation, we propose CorruptRAG, a practical poisoning attack against RAG systems in which the attacker injects only a single poisoned text, enhancing both feasibility and stealth. Extensive experiments across multiple datasets demonstrate that CorruptRAG achieves higher attack success rates compared to existing baselines.
Synergizing AI and Digital Twins for Next-Generation Network Optimization, Forecasting, and Security
Mar 08, 2025



Digital network twins (DNTs) are virtual representations of physical networks, designed to enable real-time monitoring, simulation, and optimization of network performance. When integrated with machine learning (ML) techniques, particularly federated learning (FL) and reinforcement learning (RL), DNTs emerge as powerful solutions for managing the complexities of network operations. This article presents a comprehensive analysis of the synergy of DNTs, FL, and RL techniques, showcasing their collective potential to address critical challenges in 6G networks. We highlight key technical challenges that need to be addressed, such as ensuring network reliability, achieving joint data-scenario forecasting, and maintaining security in high-risk environments. Additionally, we propose several pipelines that integrate DNT and ML within coherent frameworks to enhance network optimization and security. Case studies demonstrate the practical applications of our proposed pipelines in edge caching and vehicular networks. In edge caching, the pipeline achieves over 80% cache hit rates while balancing base station loads. In autonomous vehicular system, it ensure a 100% no-collision rate, showcasing its reliability in safety-critical scenarios. By exploring these synergies, we offer insights into the future of intelligent and adaptive network systems that automate decision-making and problem-solving.
Provably Robust Federated Reinforcement Learning
Feb 12, 2025Federated reinforcement learning (FRL) allows agents to jointly learn a global decision-making policy under the guidance of a central server. While FRL has advantages, its decentralized design makes it prone to poisoning attacks. To mitigate this, Byzantine-robust aggregation techniques tailored for FRL have been introduced. Yet, in our work, we reveal that these current Byzantine-robust techniques are not immune to our newly introduced Normalized attack. Distinct from previous attacks that targeted enlarging the distance of policy updates before and after an attack, our Normalized attack emphasizes on maximizing the angle of deviation between these updates. To counter these threats, we develop an ensemble FRL approach that is provably secure against both known and our newly proposed attacks. Our ensemble method involves training multiple global policies, where each is learnt by a group of agents using any foundational aggregation rule. These well-trained global policies then individually predict the action for a specific test state. The ultimate action is chosen based on a majority vote for discrete action systems or the geometric median for continuous ones. Our experimental results across different settings show that the Normalized attack can greatly disrupt non-ensemble Byzantine-robust methods, and our ensemble approach offers substantial resistance against poisoning attacks.
Poisoning Attacks and Defenses to Federated Unlearning
Jan 29, 2025


Federated learning allows multiple clients to collaboratively train a global model with the assistance of a server. However, its distributed nature makes it susceptible to poisoning attacks, where malicious clients can compromise the global model by sending harmful local model updates to the server. To unlearn an accurate global model from a poisoned one after identifying malicious clients, federated unlearning has been introduced. Yet, current research on federated unlearning has primarily concentrated on its effectiveness and efficiency, overlooking the security challenges it presents. In this work, we bridge the gap via proposing BadUnlearn, the first poisoning attacks targeting federated unlearning. In BadUnlearn, malicious clients send specifically designed local model updates to the server during the unlearning process, aiming to ensure that the resulting unlearned model remains poisoned. To mitigate these threats, we propose UnlearnGuard, a robust federated unlearning framework that is provably robust against both existing poisoning attacks and our BadUnlearn. The core concept of UnlearnGuard is for the server to estimate the clients' local model updates during the unlearning process and employ a filtering strategy to verify the accuracy of these estimations. Theoretically, we prove that the model unlearned through UnlearnGuard closely resembles one obtained by train-from-scratch. Empirically, we show that BadUnlearn can effectively corrupt existing federated unlearning methods, while UnlearnGuard remains secure against poisoning attacks.