 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Conditioned Evidential Keyframe Sampling for MLLM-Based Long-Form Video Understanding
Apr 01, 2026Multimodal Large Language Models (MLLMs) have shown strong performance on video question answering, but their application to long-form videos is constrained by limited context length and computational cost, making keyframe sampling essential. Existing approaches typically rely on semantic relevance or reinforcement learning, which either fail to capture evidential clues or suffer from inefficient combinatorial optimization. In this work, we propose an evidence-driven keyframe sampling framework grounded in information bottleneck theory. We formulate keyframe selection as maximizing the conditional mutual information between selected frames and the query, providing a principled objective that reflects each frame's contribution to answering the question. To make this objective tractable, we exploit its structure to derive a decomposed optimization that reduces subset selection to independent frame-level scoring. We further introduce a query-conditioned evidence scoring network trained with a contrastive objective to estimate evidential importance efficiently. Experiments on long-form video understanding benchmarks show that our method consistently outperforms prior sampling strategies under strict token budgets, while significantly improving training efficiency.
MUSE: A Run-Centric Platform for Multimodal Unified Safety Evaluation of Large Language Models
Mar 03, 2026Safety evaluation and red-teaming of large language models remain predominantly text-centric, and existing frameworks lack the infrastructure to systematically test whether alignment generalizes to audio, image, and video inputs. We present MUSE (Multimodal Unified Safety Evaluation), an open-source, run-centric platform that integrates automatic cross-modal payload generation, three multi-turn attack algorithms (Crescendo, PAIR, Violent Durian), provider-agnostic model routing, and an LLM judge with a five-level safety taxonomy into a single browser-based system. A dual-metric framework distinguishes hard Attack Success Rate (Compliance only) from soft ASR (including Partial Compliance), capturing partial information leakage that binary metrics miss. To probe whether alignment generalizes across modality boundaries, we introduce Inter-Turn Modality Switching (ITMS), which augments multi-turn attacks with per-turn modality rotation. Experiments across six multimodal LLMs from four providers show that multi-turn strategies can achieve up to 90-100% ASR against models with near-perfect single-turn refusal. ITMS does not uniformly raise final ASR on already-saturated baselines, but accelerates convergence by destabilizing early-turn defenses, and ablation reveals that the direction of modality effects is model-family-specific rather than universal, underscoring the need for provider-aware cross-modal safety testing.
OpenSage: Self-programming Agent Generation Engine
Feb 18, 2026Agent development kits (ADKs) provide effective platforms and tooling for constructing agents, and their designs are critical to the constructed agents' performance, especially the functionality for agent topology, tools, and memory. However, current ADKs either lack sufficient functional support or rely on humans to manually design these components, limiting agents' generalizability and overall performance. We propose OpenSage, the first ADK that enables LLMs to automatically create agents with self-generated topology and toolsets while providing comprehensive and structured memory support. OpenSage offers effective functionality for agents to create and manage their own sub-agents and toolkits. It also features a hierarchical, graph-based memory system for efficient management and a specialized toolkit tailored to software engineering tasks. Extensive experiments across three state-of-the-art benchmarks with various backbone models demonstrate the advantages of OpenSage over existing ADKs. We also conduct rigorous ablation studies to demonstrate the effectiveness of our design for each component. We believe OpenSage can pave the way for the next generation of agent development, shifting the focus from human-centered to AI-centered paradigms.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
SADA: Stability-guided Adaptive Diffusion Acceleration
Jul 23, 2025Diffusion models have achieved remarkable success in generative tasks but suffer from high computational costs due to their iterative sampling process and quadratic attention costs. Existing training-free acceleration strategies that reduce per-step computation cost, while effectively reducing sampling time, demonstrate low faithfulness compared to the original baseline. We hypothesize that this fidelity gap arises because (a) different prompts correspond to varying denoising trajectory, and (b) such methods do not consider the underlying ODE formulation and its numerical solution. In this paper, we propose Stability-guided Adaptive Diffusion Acceleration (SADA), a novel paradigm that unifies step-wise and token-wise sparsity decisions via a single stability criterion to accelerate sampling of ODE-based generative models (Diffusion and Flow-matching). For (a), SADA adaptively allocates sparsity based on the sampling trajectory. For (b), SADA introduces principled approximation schemes that leverage the precise gradient information from the numerical ODE solver. Comprehensive evaluations on SD-2, SDXL, and Flux using both EDM and DPM++ solvers reveal consistent $\ge 1.8\times$ speedups with minimal fidelity degradation (LPIPS $\leq 0.10$ and FID $\leq 4.5$) compared to unmodified baselines, significantly outperforming prior methods. Moreover, SADA adapts seamlessly to other pipelines and modalities: It accelerates ControlNet without any modifications and speeds up MusicLDM by $1.8\times$ with $\sim 0.01$ spectrogram LPIPS.
F^2TTA: Free-Form Test-Time Adaptation on Cross-Domain Medical Image Classification via Image-Level Disentangled Prompt Tuning
Jul 03, 2025Test-Time Adaptation (TTA) has emerged as a promising solution for adapting a source model to unseen medical sites using unlabeled test data, due to the high cost of data annotation. Existing TTA methods consider scenarios where data from one or multiple domains arrives in complete domain units. However, in clinical practice, data usually arrives in domain fragments of arbitrary lengths and in random arrival orders, due to resource constraints and patient variability. This paper investigates a practical Free-Form Test-Time Adaptation (F$^{2}$TTA) task, where a source model is adapted to such free-form domain fragments, with shifts occurring between fragments unpredictably. In this setting, these shifts could distort the adaptation process. To address this problem, we propose a novel Image-level Disentangled Prompt Tuning (I-DiPT) framework. I-DiPT employs an image-invariant prompt to explore domain-invariant representations for mitigating the unpredictable shifts, and an image-specific prompt to adapt the source model to each test image from the incoming fragments. The prompts may suffer from insufficient knowledge representation since only one image is available for training. To overcome this limitation, we first introduce Uncertainty-oriented Masking (UoM), which encourages the prompts to extract sufficient information from the incoming image via masked consistency learning driven by the uncertainty of the source model representations. Then, we further propose a Parallel Graph Distillation (PGD) method that reuses knowledge from historical image-specific and image-invariant prompts through parallel graph networks. Experiments on breast cancer and glaucoma classification demonstrate the superiority of our method over existing TTA approaches in F$^{2}$TTA. Code is available at https://github.com/mar-cry/F2TTA.
Phi: Leveraging Pattern-based Hierarchical Sparsity for High-Efficiency Spiking Neural Networks
May 16, 2025Spiking Neural Networks (SNNs) are gaining attention for their energy efficiency and biological plausibility, utilizing 0-1 activation sparsity through spike-driven computation. While existing SNN accelerators exploit this sparsity to skip zero computations, they often overlook the unique distribution patterns inherent in binary activations. In this work, we observe that particular patterns exist in spike activations, which we can utilize to reduce the substantial computation of SNN models. Based on these findings, we propose a novel \textbf{pattern-based hierarchical sparsity} framework, termed \textbf{\textit{Phi}}, to optimize computation. \textit{Phi} introduces a two-level sparsity hierarchy: Level 1 exhibits vector-wise sparsity by representing activations with pre-defined patterns, allowing for offline pre-computation with weights and significantly reducing most runtime computation. Level 2 features element-wise sparsity by complementing the Level 1 matrix, using a highly sparse matrix to further reduce computation while maintaining accuracy. We present an algorithm-hardware co-design approach. Algorithmically, we employ a k-means-based pattern selection method to identify representative patterns and introduce a pattern-aware fine-tuning technique to enhance Level 2 sparsity. Architecturally, we design \textbf{\textit{Phi}}, a dedicated hardware architecture that efficiently processes the two levels of \textit{Phi} sparsity on the fly. Extensive experiments demonstrate that \textit{Phi} achieves a $3.45\times$ speedup and a $4.93\times$ improvement in energy efficiency compared to state-of-the-art SNN accelerators, showcasing the effectiveness of our framework in optimizing SNN computation.
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
Apr 30, 2025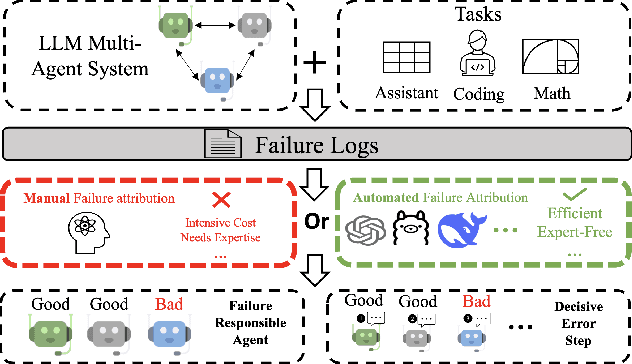
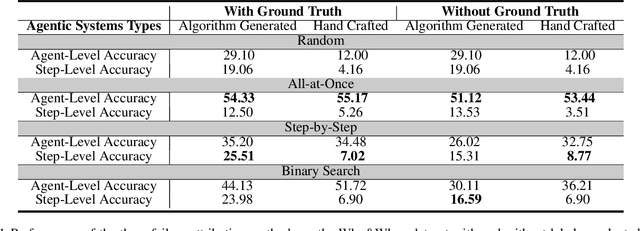
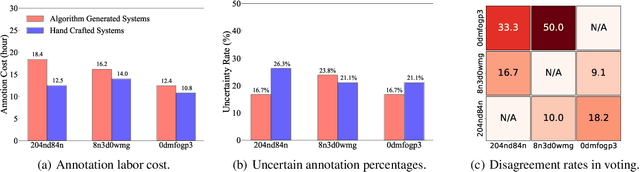

Failure attribution in LLM multi-agent systems-identifying the agent and step responsible for task failures-provides crucial clues for systems debugging but remains underexplored and labor-intensive. In this paper, we propose and formulate a new research area: automated failure attribution for LLM multi-agent systems. To support this initiative, we introduce the Who&When dataset, comprising extensive failure logs from 127 LLM multi-agent systems with fine-grained annotations linking failures to specific agents and decisive error steps. Using the Who&When, we develop and evaluate three automated failure attribution methods, summarizing their corresponding pros and cons. The best method achieves 53.5% accuracy in identifying failure-responsible agents but only 14.2% in pinpointing failure steps, with some methods performing below random. Even SOTA reasoning models, such as OpenAI o1 and DeepSeek R1, fail to achieve practical usability. These results highlight the task's complexity and the need for further research in this area. Code and dataset are available at https://github.com/mingyin1/Agents_Failure_Attribution
Dynamic Allocation Hypernetwork with Adaptive Model Recalibration for Federated Continual Learning
Mar 25, 2025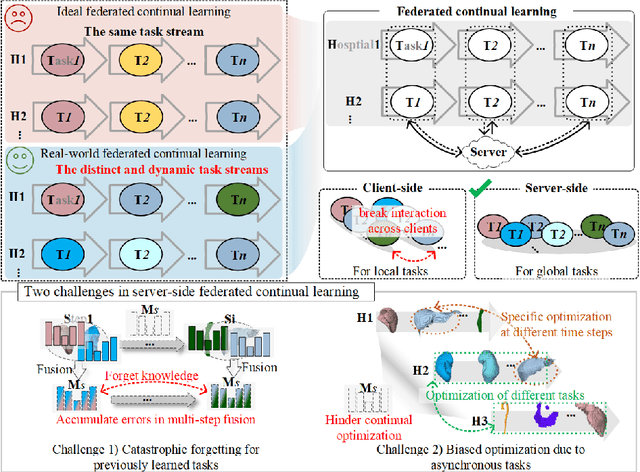

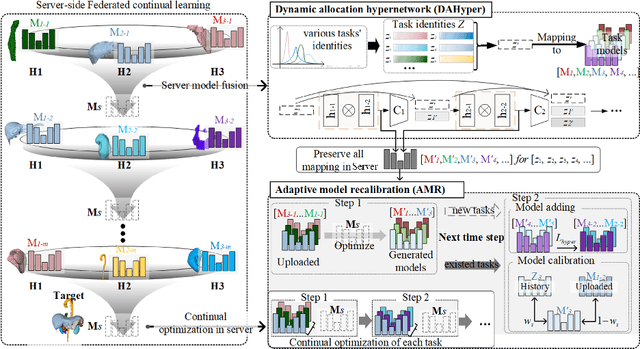

Federated continual learning (FCL) offers an emerging pattern to facilitate the applicability of federated learning (FL) in real-world scenarios, where tasks evolve dynamically and asynchronously across clients, especially in medical scenario. Existing server-side FCL methods in nature domain construct a continually learnable server model by client aggregation on all-involved tasks. However, they are challenged by: (1) Catastrophic forgetting for previously learned tasks, leading to error accumulation in server model, making it difficult to sustain comprehensive knowledge across all tasks. (2) Biased optimization due to asynchronous tasks handled across different clients, leading to the collision of optimization targets of different clients at the same time steps. In this work, we take the first step to propose a novel server-side FCL pattern in medical domain, Dynamic Allocation Hypernetwork with adaptive model recalibration (FedDAH). It is to facilitate collaborative learning under the distinct and dynamic task streams across clients. To alleviate the catastrophic forgetting, we propose a dynamic allocation hypernetwork (DAHyper) where a continually updated hypernetwork is designed to manage the mapping between task identities and their associated model parameters, enabling the dynamic allocation of the model across clients. For the biased optimization, we introduce a novel adaptive model recalibration (AMR) to incorporate the candidate changes of historical models into current server updates, and assign weights to identical tasks across different time steps based on the similarity for continual optimization. Extensive experiments on the AMOS dataset demonstrate the superiority of our FedDAH to other FCL methods on sites with different task streams. The code is available:https://github.com/jinlab-imvr/FedDAH.