 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix3D: Large Photogrammetry Model All-in-One
Feb 11, 2025We present Matrix3D, a unified model that performs several photogrammetry subtasks, including pose estimation, depth prediction, and novel view synthesis using just the same model. Matrix3D utilizes a multi-modal diffusion transformer (DiT) to integrate transformations across several modalities, such as images, camera parameters, and depth maps. The key to Matrix3D's large-scale multi-modal training lies in the incorporation of a mask learning strategy. This enables full-modality model training even with partially complete data, such as bi-modality data of image-pose and image-depth pairs, thus significantly increases the pool of available training data. Matrix3D demonstrates state-of-the-art performance in pose estimation and novel view synthesis tasks. Additionally, it offers fine-grained control through multi-round interactions, making it an innovative tool for 3D content creation. Project page: https://nju-3dv.github.io/projects/matrix3d.
EmoTalk3D: High-Fidelity Free-View Synthesis of Emotional 3D Talking Head
Aug 01, 2024



We present a novel approach for synthesizing 3D talking heads with controllable emotion, featuring enhanced lip synchronization and rendering quality. Despite significant progress in the field, prior methods still suffer from multi-view consistency and a lack of emotional expressiveness. To address these issues, we collect EmoTalk3D dataset with calibrated multi-view videos, emotional annotations, and per-frame 3D geometry. By training on the EmoTalk3D dataset, we propose a \textit{`Speech-to-Geometry-to-Appearance'} mapping framework that first predicts faithful 3D geometry sequence from the audio features, then the appearance of a 3D talking head represented by 4D Gaussians is synthesized from the predicted geometry. The appearance is further disentangled into canonical and dynamic Gaussians, learned from multi-view videos, and fused to render free-view talking head animation. Moreover, our model enables controllable emotion in the generated talking heads and can be rendered in wide-range views. Our method exhibits improved rendering quality and stability in lip motion generation while capturing dynamic facial details such as wrinkles and subtle expressions. Experiments demonstrate the effectiveness of our approach in generating high-fidelity and emotion-controllable 3D talking heads. The code and EmoTalk3D dataset are released at https://nju-3dv.github.io/projects/EmoTalk3D.
STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians
Mar 22, 2024
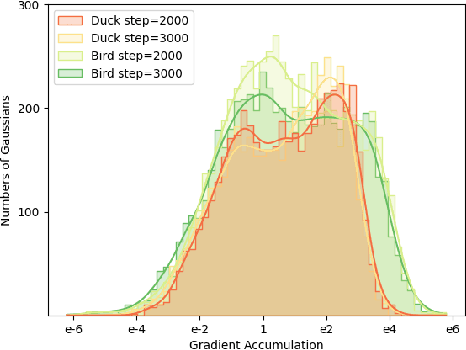

Recent progress in pre-trained diffusion models and 3D generation have spurred interest in 4D content creation. However, achieving high-fidelity 4D generation with spatial-temporal consistency remains a challenge. In this work, we propose STAG4D, a novel framework that combines pre-trained diffusion models with dynamic 3D Gaussian splatting for high-fidelity 4D generation. Drawing inspiration from 3D generation techniques, we utilize a multi-view diffusion model to initialize multi-view images anchoring on the input video frames, where the video can be either real-world captured or generated by a video diffusion model. To ensure the temporal consistency of the multi-view sequence initialization, we introduce a simple yet effective fusion strategy to leverage the first frame as a temporal anchor in the self-attention computation. With the almost consistent multi-view sequences, we then apply the score distillation sampling to optimize the 4D Gaussian point cloud. The 4D Gaussian spatting is specially crafted for the generation task, where an adaptive densification strategy is proposed to mitigate the unstable Gaussian gradient for robust optimization. Notably, the proposed pipeline does not require any pre-training or fine-tuning of diffusion networks, offering a more accessible and practical solution for the 4D generation task. Extensive experiments demonstrate that our method outperforms prior 4D generation works in rendering quality, spatial-temporal consistency, and generation robustness, setting a new state-of-the-art for 4D generation from diverse inputs, including text, image, and video.
Direct2.5: Diverse Text-to-3D Generation via Multi-view 2.5D Diffusion
Nov 27, 2023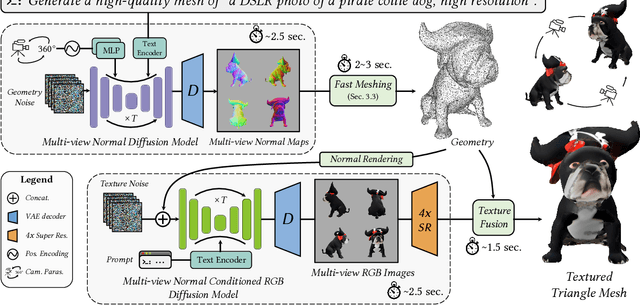



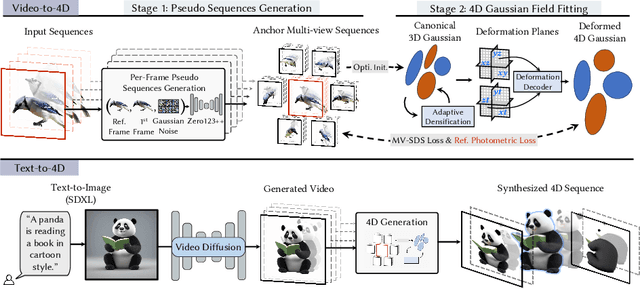
Recent advances in generative AI have unveiled significant potential for the creation of 3D content. However, current methods either apply a pre-trained 2D diffusion model with the time-consuming score distillation sampling (SDS), or a direct 3D diffusion model trained on limited 3D data losing generation diversity. In this work, we approach the problem by employing a multi-view 2.5D diffusion fine-tuned from a pre-trained 2D diffusion model. The multi-view 2.5D diffusion directly models the structural distribution of 3D data, while still maintaining the strong generalization ability of the original 2D diffusion model, filling the gap between 2D diffusion-based and direct 3D diffusion-based methods for 3D content generation. During inference, multi-view normal maps are generated using the 2.5D diffusion, and a novel differentiable rasterization scheme is introduced to fuse the almost consistent multi-view normal maps into a consistent 3D model. We further design a normal-conditioned multi-view image generation module for fast appearance generation given the 3D geometry. Our method is a one-pass diffusion process and does not require any SDS optimization as post-processing. We demonstrate through extensive experiments that, our direct 2.5D generation with the specially-designed fusion scheme can achieve diverse, mode-seeking-free, and high-fidelity 3D content generation in only 10 seconds. Project page: https://nju-3dv.github.io/projects/direct25.
JointNet: Extending Text-to-Image Diffusion for Dense Distribution Modeling
Oct 10, 2023


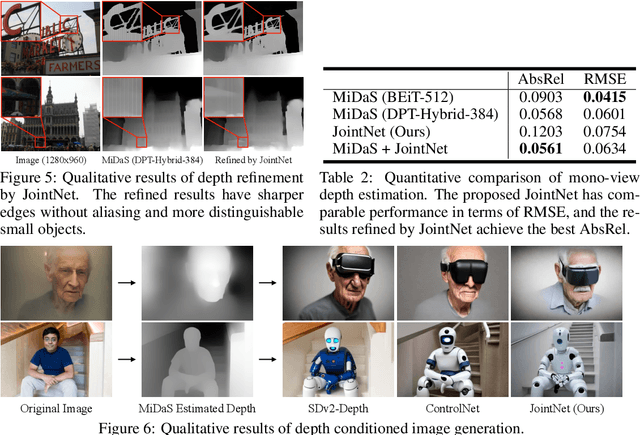
We introduce JointNet, a novel neural network architecture for modeling the joint distribution of images and an additional dense modality (e.g., depth maps). JointNet is extended from a pre-trained text-to-image diffusion model, where a copy of the original network is created for the new dense modality branch and is densely connected with the RGB branch. The RGB branch is locked during network fine-tuning, which enables efficient learning of the new modality distribution while maintaining the strong generalization ability of the large-scale pre-trained diffusion model. We demonstrate the effectiveness of JointNet by using RGBD diffusion as an example and through extensive experiments, showcasing its applicability in a variety of applications, including joint RGBD generation, dense depth prediction, depth-conditioned image generation, and coherent tile-based 3D panorama generation.
AvatarBooth: High-Quality and Customizable 3D Human Avatar Generation
Jun 16, 2023



We introduce AvatarBooth, a novel method for generating high-quality 3D avatars using text prompts or specific images. Unlike previous approaches that can only synthesize avatars based on simple text descriptions, our method enables the creation of personalized avatars from casually captured face or body images, while still supporting text-based model generation and editing. Our key contribution is the precise avatar generation control by using dual fine-tuned diffusion models separately for the human face and body. This enables us to capture intricate details of facial appearance, clothing, and accessories, resulting in highly realistic avatar generations. Furthermore, we introduce pose-consistent constraint to the optimization process to enhance the multi-view consistency of synthesized head images from the diffusion model and thus eliminate interference from uncontrolled human poses. In addition, we present a multi-resolution rendering strategy that facilitates coarse-to-fine supervision of 3D avatar generation, thereby enhancing the performance of the proposed system. The resulting avatar model can be further edited using additional text descriptions and driven by motion sequences. Experiments show that AvatarBooth outperforms previous text-to-3D methods in terms of rendering and geometric quality from either text prompts or specific images. Please check our project website at https://zeng-yifei.github.io/avatarbooth_page/.
High-Fidelity 3D Face Generation from Natural Language Descriptions
May 05, 2023

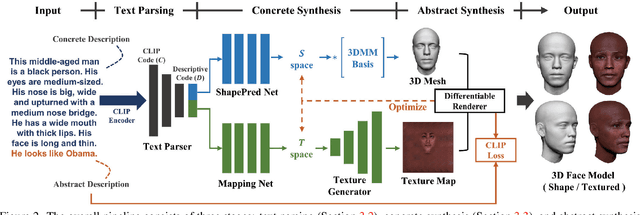

Synthesizing high-quality 3D face models from natural language descriptions is very valuable for many applications, including avatar creation, virtual reality, and telepresence. However, little research ever tapped into this task. We argue the major obstacle lies in 1) the lack of high-quality 3D face data with descriptive text annotation, and 2) the complex mapping relationship between descriptive language space and shape/appearance space. To solve these problems, we build Describe3D dataset, the first large-scale dataset with fine-grained text descriptions for text-to-3D face generation task. Then we propose a two-stage framework to first generate a 3D face that matches the concrete descriptions, then optimize the parameters in the 3D shape and texture space with abstract description to refine the 3D face model. Extensive experimental results show that our method can produce a faithful 3D face that conforms to the input descriptions with higher accuracy and quality than previous methods. The code and Describe3D dataset are released at https://github.com/zhuhao-nju/describe3d .
RAFaRe: Learning Robust and Accurate Non-parametric 3D Face Reconstruction from Pseudo 2D&3D Pairs
Feb 10, 2023



We propose a robust and accurate non-parametric method for single-view 3D face reconstruction (SVFR). While tremendous efforts have been devoted to parametric SVFR, a visible gap still lies between the result 3D shape and the ground truth. We believe there are two major obstacles: 1) the representation of the parametric model is limited to a certain face database; 2) 2D images and 3D shapes in the fitted datasets are distinctly misaligned. To resolve these issues, a large-scale pseudo 2D\&3D dataset is created by first rendering the detailed 3D faces, then swapping the face in the wild images with the rendered face. These pseudo 2D&3D pairs are created from publicly available datasets which eliminate the gaps between 2D and 3D data while covering diverse appearances, poses, scenes, and illumination. We further propose a non-parametric scheme to learn a well-generalized SVFR model from the created dataset, and the proposed hierarchical signed distance function turns out to be effective in predicting middle-scale and small-scale 3D facial geometry. Our model outperforms previous methods on FaceScape-wild/lab and MICC benchmarks and is well generalized to various appearances, poses, expressions, and in-the-wild environments. The code is released at http://github.com/zhuhao-nju/rafare .
Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation
Sep 24, 2021
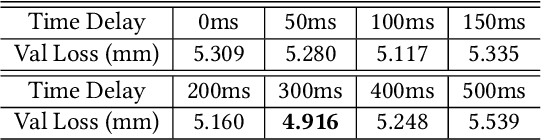
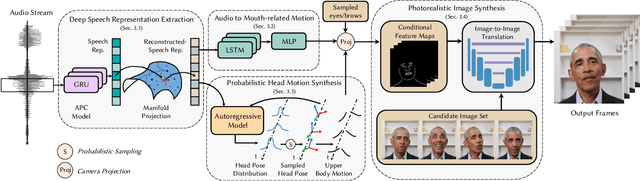
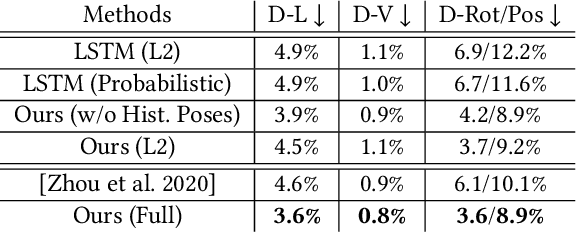
To the best of our knowledge, we first present a live system that generates personalized photorealistic talking-head animation only driven by audio signals at over 30 fps. Our system contains three stages. The first stage is a deep neural network that extracts deep audio features along with a manifold projection to project the features to the target person's speech space. In the second stage, we learn facial dynamics and motions from the projected audio features. The predicted motions include head poses and upper body motions, where the former is generated by an autoregressive probabilistic model which models the head pose distribution of the target person. Upper body motions are deduced from head poses. In the final stage, we generate conditional feature maps from previous predictions and send them with a candidate image set to an image-to-image translation network to synthesize photorealistic renderings. Our method generalizes well to wild audio and successfully synthesizes high-fidelity personalized facial details, e.g., wrinkles, teeth. Our method also allows explicit control of head poses. Extensive qualitative and quantitative evaluations, along with user studies, demonstrate the superiority of our method over state-of-the-art techniques.