 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
Direct3D-S2: Gigascale 3D Generation Made Easy with Spatial Sparse Attention
May 26, 2025Generating high-resolution 3D shapes using volumetric representations such as Signed Distance Functions (SDFs) presents substantial computational and memory challenges. We introduce Direct3D-S2, a scalable 3D generation framework based on sparse volumes that achieves superior output quality with dramatically reduced training costs. Our key innovation is the Spatial Sparse Attention (SSA) mechanism, which greatly enhances the efficiency of Diffusion Transformer (DiT) computations on sparse volumetric data. SSA allows the model to effectively process large token sets within sparse volumes, substantially reducing computational overhead and achieving a 3.9x speedup in the forward pass and a 9.6x speedup in the backward pass. Our framework also includes a variational autoencoder (VAE) that maintains a consistent sparse volumetric format across input, latent, and output stages. Compared to previous methods with heterogeneous representations in 3D VAE, this unified design significantly improves training efficiency and stability. Our model is trained on public available datasets, and experiments demonstrate that Direct3D-S2 not only surpasses state-of-the-art methods in generation quality and efficiency, but also enables training at 1024 resolution using only 8 GPUs, a task typically requiring at least 32 GPUs for volumetric representations at 256 resolution, thus making gigascale 3D generation both practical and accessible. Project page: https://www.neural4d.com/research/direct3d-s2.
Align Your Rhythm: Generating Highly Aligned Dance Poses with Gating-Enhanced Rhythm-Aware Feature Representation
Mar 21, 2025Automatically generating natural, diverse and rhythmic human dance movements driven by music is vital for virtual reality and film industries. However, generating dance that naturally follows music remains a challenge, as existing methods lack proper beat alignment and exhibit unnatural motion dynamics. In this paper, we propose Danceba, a novel framework that leverages gating mechanism to enhance rhythm-aware feature representation for music-driven dance generation, which achieves highly aligned dance poses with enhanced rhythmic sensitivity. Specifically, we introduce Phase-Based Rhythm Extraction (PRE) to precisely extract rhythmic information from musical phase data, capitalizing on the intrinsic periodicity and temporal structures of music. Additionally, we propose Temporal-Gated Causal Attention (TGCA) to focus on global rhythmic features, ensuring that dance movements closely follow the musical rhythm. We also introduce Parallel Mamba Motion Modeling (PMMM) architecture to separately model upper and lower body motions along with musical features, thereby improving the naturalness and diversity of generated dance movements. Extensive experiments confirm that Danceba outperforms state-of-the-art methods, achieving significantly better rhythmic alignment and motion diversity. Project page: https://danceba.github.io/ .
Flow Distillation Sampling: Regularizing 3D Gaussians with Pre-trained Matching Priors
Feb 11, 20253D Gaussian Splatting (3DGS) has achieved excellent rendering quality with fast training and rendering speed. However, its optimization process lacks explicit geometric constraints, leading to suboptimal geometric reconstruction in regions with sparse or no observational input views. In this work, we try to mitigate the issue by incorporating a pre-trained matching prior to the 3DGS optimization process. We introduce Flow Distillation Sampling (FDS), a technique that leverages pre-trained geometric knowledge to bolster the accuracy of the Gaussian radiance field. Our method employs a strategic sampling technique to target unobserved views adjacent to the input views, utilizing the optical flow calculated from the matching model (Prior Flow) to guide the flow analytically calculated from the 3DGS geometry (Radiance Flow). Comprehensive experiments in depth rendering, mesh reconstruction, and novel view synthesis showcase the significant advantages of FDS over state-of-the-art methods. Additionally, our interpretive experiments and analysis aim to shed light on the effects of FDS on geometric accuracy and rendering quality, potentially providing readers with insights into its performance. Project page: https://nju-3dv.github.io/projects/fds
FastDrag: Manipulate Anything in One Step
May 24, 2024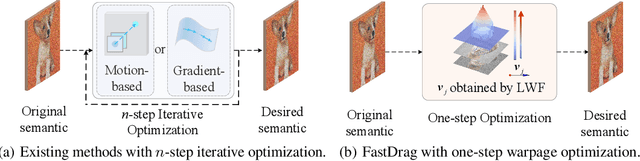


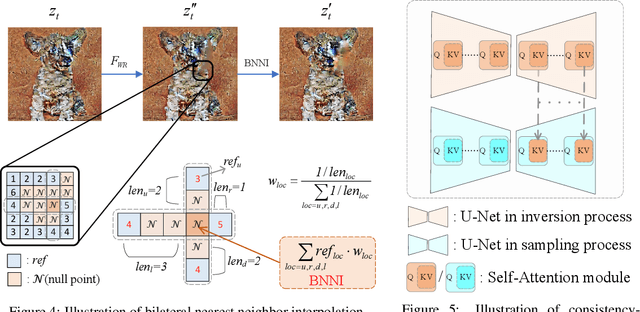
Drag-based image editing using generative models provides precise control over image contents, enabling users to manipulate anything in an image with a few clicks. However, prevailing methods typically adopt $n$-step iterations for latent semantic optimization to achieve drag-based image editing, which is time-consuming and limits practical applications. In this paper, we introduce a novel one-step drag-based image editing method, i.e., FastDrag, to accelerate the editing process. Central to our approach is a latent warpage function (LWF), which simulates the behavior of a stretched material to adjust the location of individual pixels within the latent space. This innovation achieves one-step latent semantic optimization and hence significantly promotes editing speeds. Meanwhile, null regions emerging after applying LWF are addressed by our proposed bilateral nearest neighbor interpolation (BNNI) strategy. This strategy interpolates these regions using similar features from neighboring areas, thus enhancing semantic integrity. Additionally, a consistency-preserving strategy is introduced to maintain the consistency between the edited and original images by adopting semantic information from the original image, saved as key and value pairs in self-attention module during diffusion inversion, to guide the diffusion sampling. Our FastDrag is validated on the DragBench dataset, demonstrating substantial improvements in processing time over existing methods, while achieving enhanced editing performance.
Direct3D: Scalable Image-to-3D Generation via 3D Latent Diffusion Transformer
May 23, 2024Generating high-quality 3D assets from text and images has long been challenging, primarily due to the absence of scalable 3D representations capable of capturing intricate geometry distributions. In this work, we introduce Direct3D, a native 3D generative model scalable to in-the-wild input images, without requiring a multiview diffusion model or SDS optimization. Our approach comprises two primary components: a Direct 3D Variational Auto-Encoder (D3D-VAE) and a Direct 3D Diffusion Transformer (D3D-DiT). D3D-VAE efficiently encodes high-resolution 3D shapes into a compact and continuous latent triplane space. Notably, our method directly supervises the decoded geometry using a semi-continuous surface sampling strategy, diverging from previous methods relying on rendered images as supervision signals. D3D-DiT models the distribution of encoded 3D latents and is specifically designed to fuse positional information from the three feature maps of the triplane latent, enabling a native 3D generative model scalable to large-scale 3D datasets. Additionally, we introduce an innovative image-to-3D generation pipeline incorporating semantic and pixel-level image conditions, allowing the model to produce 3D shapes consistent with the provided conditional image input. Extensive experiments demonstrate the superiority of our large-scale pre-trained Direct3D over previous image-to-3D approaches, achieving significantly better generation quality and generalization ability, thus establishing a new state-of-the-art for 3D content creation. Project page: https://nju-3dv.github.io/projects/Direct3D/.
STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians
Mar 22, 2024

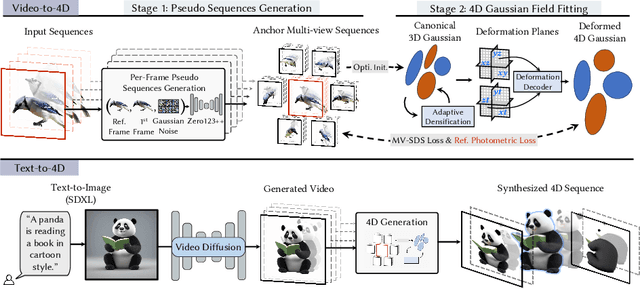
Recent progress in pre-trained diffusion models and 3D generation have spurred interest in 4D content creation. However, achieving high-fidelity 4D generation with spatial-temporal consistency remains a challenge. In this work, we propose STAG4D, a novel framework that combines pre-trained diffusion models with dynamic 3D Gaussian splatting for high-fidelity 4D generation. Drawing inspiration from 3D generation techniques, we utilize a multi-view diffusion model to initialize multi-view images anchoring on the input video frames, where the video can be either real-world captured or generated by a video diffusion model. To ensure the temporal consistency of the multi-view sequence initialization, we introduce a simple yet effective fusion strategy to leverage the first frame as a temporal anchor in the self-attention computation. With the almost consistent multi-view sequences, we then apply the score distillation sampling to optimize the 4D Gaussian point cloud. The 4D Gaussian spatting is specially crafted for the generation task, where an adaptive densification strategy is proposed to mitigate the unstable Gaussian gradient for robust optimization. Notably, the proposed pipeline does not require any pre-training or fine-tuning of diffusion networks, offering a more accessible and practical solution for the 4D generation task. Extensive experiments demonstrate that our method outperforms prior 4D generation works in rendering quality, spatial-temporal consistency, and generation robustness, setting a new state-of-the-art for 4D generation from diverse inputs, including text, image, and video.
UniDream: Unifying Diffusion Priors for Relightable Text-to-3D Generation
Dec 14, 2023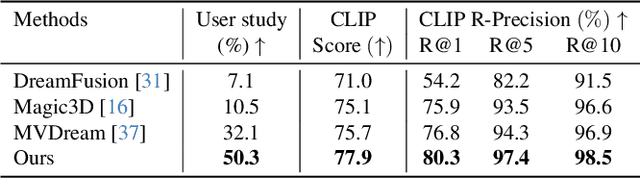
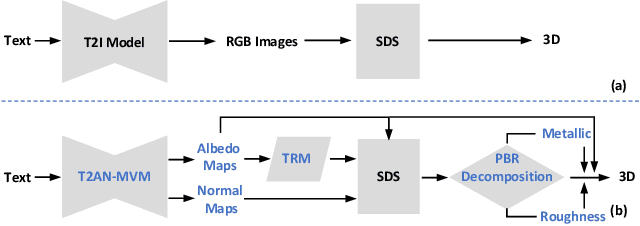
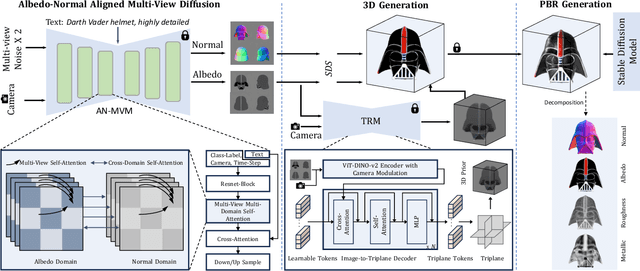

Recent advancements in text-to-3D generation technology have significantly advanced the conversion of textual descriptions into imaginative well-geometrical and finely textured 3D objects. Despite these developments, a prevalent limitation arises from the use of RGB data in diffusion or reconstruction models, which often results in models with inherent lighting and shadows effects that detract from their realism, thereby limiting their usability in applications that demand accurate relighting capabilities. To bridge this gap, we present UniDream, a text-to-3D generation framework by incorporating unified diffusion priors. Our approach consists of three main components: (1) a dual-phase training process to get albedo-normal aligned multi-view diffusion and reconstruction models, (2) a progressive generation procedure for geometry and albedo-textures based on Score Distillation Sample (SDS) using the trained reconstruction and diffusion models, and (3) an innovative application of SDS for finalizing PBR generation while keeping a fixed albedo based on Stable Diffusion model. Extensive evaluations demonstrate that UniDream surpasses existing methods in generating 3D objects with clearer albedo textures, smoother surfaces, enhanced realism, and superior relighting capabilities.
Gaussian-Flow: 4D Reconstruction with Dynamic 3D Gaussian Particle
Dec 06, 2023
We introduce Gaussian-Flow, a novel point-based approach for fast dynamic scene reconstruction and real-time rendering from both multi-view and monocular videos. In contrast to the prevalent NeRF-based approaches hampered by slow training and rendering speeds, our approach harnesses recent advancements in point-based 3D Gaussian Splatting (3DGS). Specifically, a novel Dual-Domain Deformation Model (DDDM) is proposed to explicitly model attribute deformations of each Gaussian point, where the time-dependent residual of each attribute is captured by a polynomial fitting in the time domain, and a Fourier series fitting in the frequency domain. The proposed DDDM is capable of modeling complex scene deformations across long video footage, eliminating the need for training separate 3DGS for each frame or introducing an additional implicit neural field to model 3D dynamics. Moreover, the explicit deformation modeling for discretized Gaussian points ensures ultra-fast training and rendering of a 4D scene, which is comparable to the original 3DGS designed for static 3D reconstruction. Our proposed approach showcases a substantial efficiency improvement, achieving a $5\times$ faster training speed compared to the per-frame 3DGS modeling. In addition, quantitative results demonstrate that the proposed Gaussian-Flow significantly outperforms previous leading methods in novel view rendering quality. Project page: https://nju-3dv.github.io/projects/Gaussian-Flow
Relightable 3D Gaussian: Real-time Point Cloud Relighting with BRDF Decomposition and Ray Tracing
Nov 27, 2023
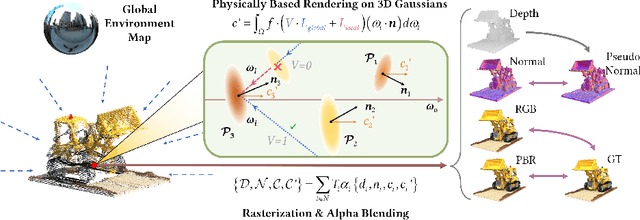
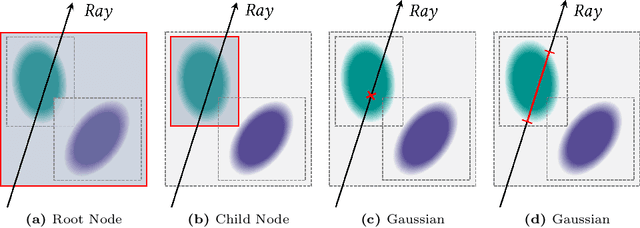
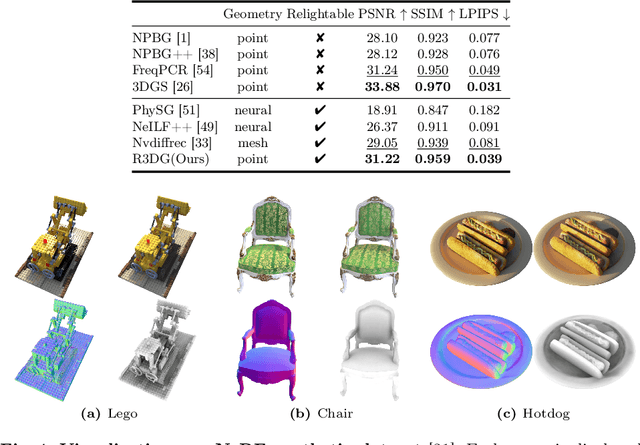
We present a novel differentiable point-based rendering framework for material and lighting decomposition from multi-view images, enabling editing, ray-tracing, and real-time relighting of the 3D point cloud. Specifically, a 3D scene is represented as a set of relightable 3D Gaussian points, where each point is additionally associated with a normal direction, BRDF parameters, and incident lights from different directions. To achieve robust lighting estimation, we further divide incident lights of each point into global and local components, as well as view-dependent visibilities. The 3D scene is optimized through the 3D Gaussian Splatting technique while BRDF and lighting are decomposed by physically-based differentiable rendering. Moreover, we introduce an innovative point-based ray-tracing approach based on the bounding volume hierarchy for efficient visibility baking, enabling real-time rendering and relighting of 3D Gaussian points with accurate shadow effects. Extensive experiments demonstrate improved BRDF estimation and novel view rendering results compared to state-of-the-art material estimation approaches. Our framework showcases the potential to revolutionize the mesh-based graphics pipeline with a relightable, traceable, and editable rendering pipeline solely based on point cloud. Project page:https://nju-3dv.github.io/projects/Relightable3DGaussian/.