 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance
Mar 21, 2024
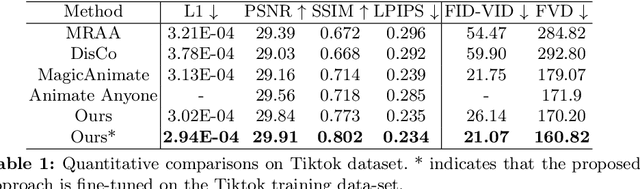
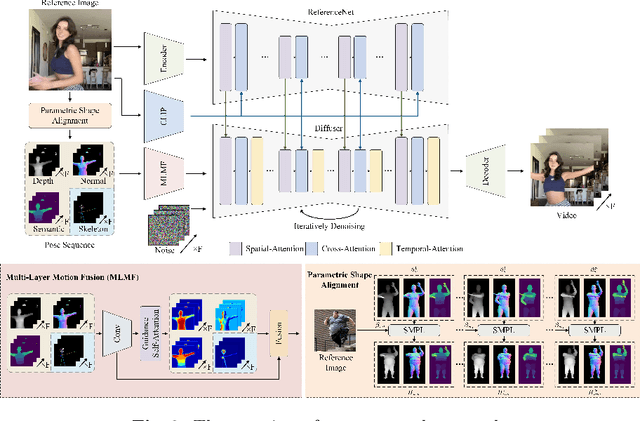
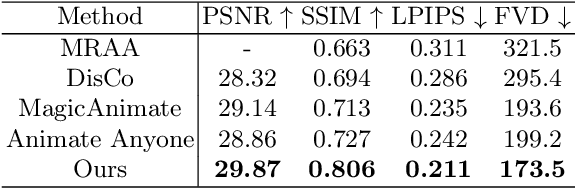
In this study, we introduce a methodology for human image animation by leveraging a 3D human parametric model within a latent diffusion framework to enhance shape alignment and motion guidance in curernt human generative techniques. The methodology utilizes the SMPL(Skinned Multi-Person Linear) model as the 3D human parametric model to establish a unified representation of body shape and pose. This facilitates the accurate capture of intricate human geometry and motion characteristics from source videos. Specifically, we incorporate rendered depth images, normal maps, and semantic maps obtained from SMPL sequences, alongside skeleton-based motion guidance, to enrich the conditions to the latent diffusion model with comprehensive 3D shape and detailed pose attributes. A multi-layer motion fusion module, integrating self-attention mechanisms, is employed to fuse the shape and motion latent representations in the spatial domain. By representing the 3D human parametric model as the motion guidance, we can perform parametric shape alignment of the human body between the reference image and the source video motion. Experimental evaluations conducted on benchmark datasets demonstrate the methodology's superior ability to generate high-quality human animations that accurately capture both pose and shape variations. Furthermore, our approach also exhibits superior generalization capabilities on the proposed wild dataset. Project page: https://fudan-generative-vision.github.io/champ.
EffiVED:Efficient Video Editing via Text-instruction Diffusion Models
Mar 18, 2024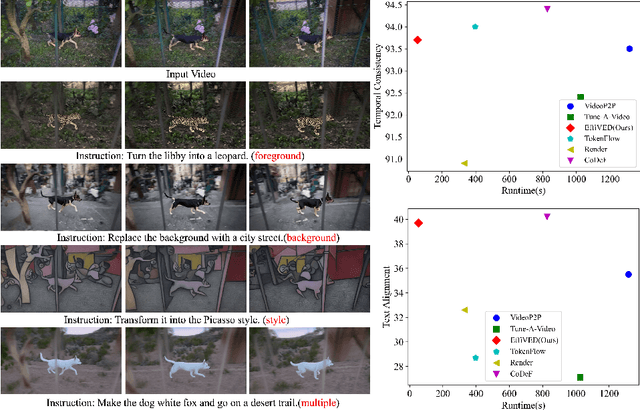
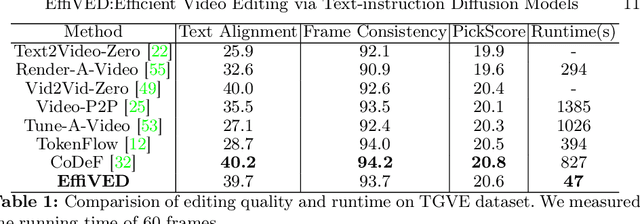
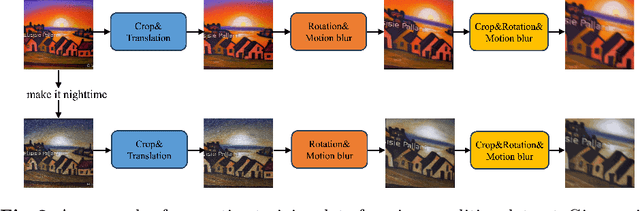
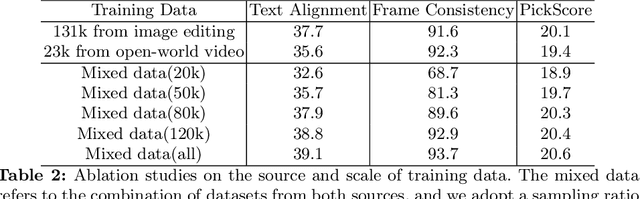
Large-scale text-to-video models have shown remarkable abilities, but their direct application in video editing remains challenging due to limited available datasets. Current video editing methods commonly require per-video fine-tuning of diffusion models or specific inversion optimization to ensure high-fidelity edits. In this paper, we introduce EffiVED, an efficient diffusion-based model that directly supports instruction-guided video editing. To achieve this, we present two efficient workflows to gather video editing pairs, utilizing augmentation and fundamental vision-language techniques. These workflows transform vast image editing datasets and open-world videos into a high-quality dataset for training EffiVED. Experimental results reveal that EffiVED not only generates high-quality editing videos but also executes rapidly. Finally, we demonstrate that our data collection method significantly improves editing performance and can potentially tackle the scarcity of video editing data. The datasets will be made publicly available upon publication.
Gaussian-Flow: 4D Reconstruction with Dynamic 3D Gaussian Particle
Dec 06, 2023
We introduce Gaussian-Flow, a novel point-based approach for fast dynamic scene reconstruction and real-time rendering from both multi-view and monocular videos. In contrast to the prevalent NeRF-based approaches hampered by slow training and rendering speeds, our approach harnesses recent advancements in point-based 3D Gaussian Splatting (3DGS). Specifically, a novel Dual-Domain Deformation Model (DDDM) is proposed to explicitly model attribute deformations of each Gaussian point, where the time-dependent residual of each attribute is captured by a polynomial fitting in the time domain, and a Fourier series fitting in the frequency domain. The proposed DDDM is capable of modeling complex scene deformations across long video footage, eliminating the need for training separate 3DGS for each frame or introducing an additional implicit neural field to model 3D dynamics. Moreover, the explicit deformation modeling for discretized Gaussian points ensures ultra-fast training and rendering of a 4D scene, which is comparable to the original 3DGS designed for static 3D reconstruction. Our proposed approach showcases a substantial efficiency improvement, achieving a $5\times$ faster training speed compared to the per-frame 3DGS modeling. In addition, quantitative results demonstrate that the proposed Gaussian-Flow significantly outperforms previous leading methods in novel view rendering quality. Project page: https://nju-3dv.github.io/projects/Gaussian-Flow
AnimateAnything: Fine-Grained Open Domain Image Animation with Motion Guidance
Dec 04, 2023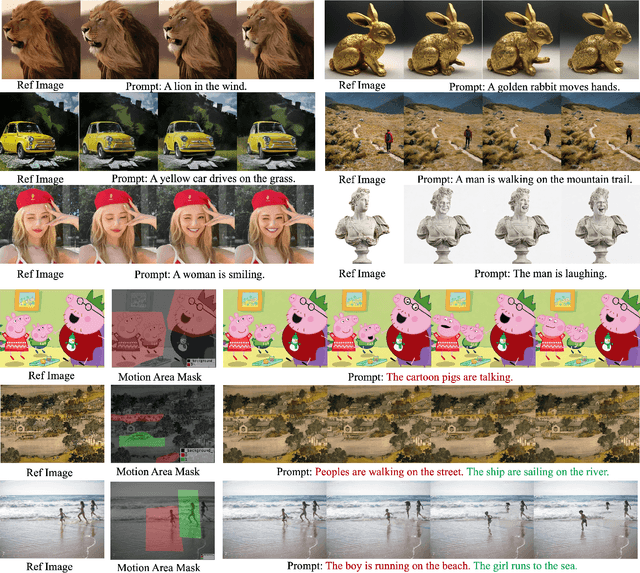
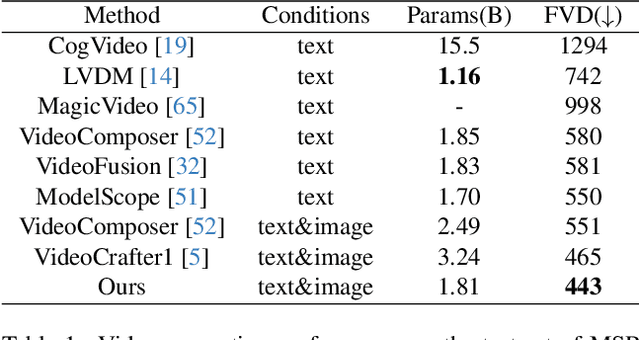
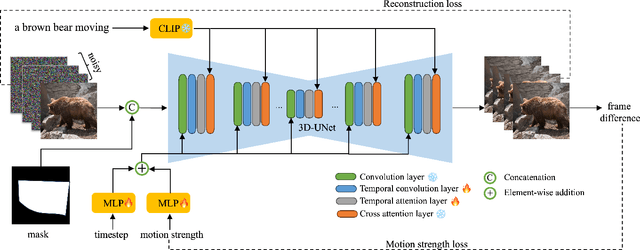
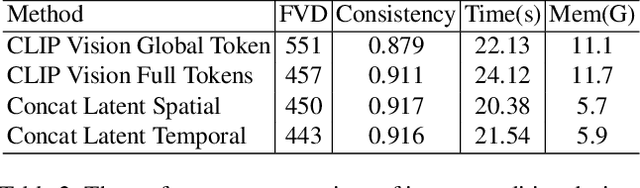
Image animation is a key task in computer vision which aims to generate dynamic visual content from static image. Recent image animation methods employ neural based rendering technique to generate realistic animations. Despite these advancements, achieving fine-grained and controllable image animation guided by text remains challenging, particularly for open-domain images captured in diverse real environments. In this paper, we introduce an open domain image animation method that leverages the motion prior of video diffusion model. Our approach introduces targeted motion area guidance and motion strength guidance, enabling precise control the movable area and its motion speed. This results in enhanced alignment between the animated visual elements and the prompting text, thereby facilitating a fine-grained and interactive animation generation process for intricate motion sequences. We validate the effectiveness of our method through rigorous experiments on an open-domain dataset, with the results showcasing its superior performance. Project page can be found at https://animationai.github.io/AnimateAnything.
Fine-grained Text-Video Retrieval with Frozen Image Encoders
Jul 14, 2023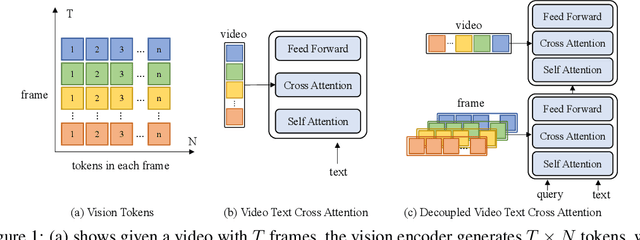
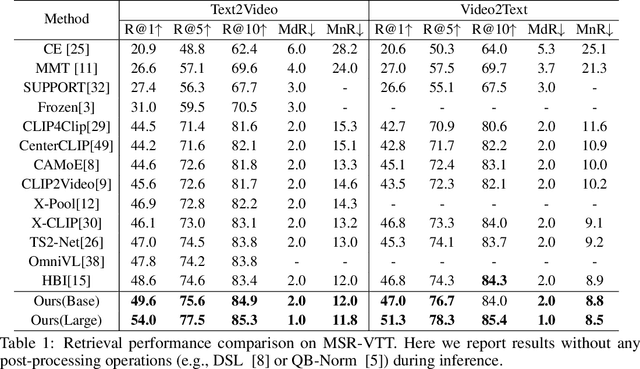
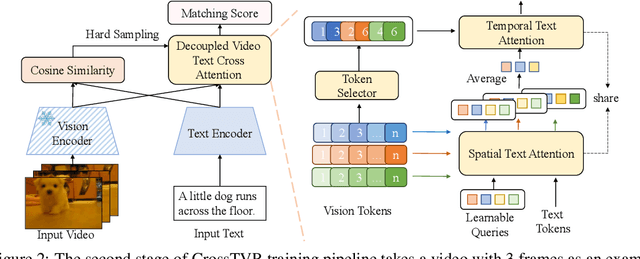

State-of-the-art text-video retrieval (TVR) methods typically utilize CLIP and cosine similarity for efficient retrieval. Meanwhile, cross attention methods, which employ a transformer decoder to compute attention between each text query and all frames in a video, offer a more comprehensive interaction between text and videos. However, these methods lack important fine-grained spatial information as they directly compute attention between text and video-level tokens. To address this issue, we propose CrossTVR, a two-stage text-video retrieval architecture. In the first stage, we leverage existing TVR methods with cosine similarity network for efficient text/video candidate selection. In the second stage, we propose a novel decoupled video text cross attention module to capture fine-grained multimodal information in spatial and temporal dimensions. Additionally, we employ the frozen CLIP model strategy in fine-grained retrieval, enabling scalability to larger pre-trained vision models like ViT-G, resulting in improved retrieval performance. Experiments on text video retrieval datasets demonstrate the effectiveness and scalability of our proposed CrossTVR compared to state-of-the-art approaches.
UVOSAM: A Mask-free Paradigm for Unsupervised Video Object Segmentation via Segment Anything Model
May 22, 2023



Unsupervised video object segmentation has made significant progress in recent years, but the manual annotation of video mask datasets is expensive and limits the diversity of available datasets. The Segment Anything Model (SAM) has introduced a new prompt-driven paradigm for image segmentation, unlocking a range of previously unexplored capabilities. In this paper, we propose a novel paradigm called UVOSAM, which leverages SAM for unsupervised video object segmentation without requiring video mask labels. To address SAM's limitations in instance discovery and identity association, we introduce a video salient object tracking network that automatically generates trajectories for prominent foreground objects. These trajectories then serve as prompts for SAM to produce video masks on a frame-by-frame basis. Our experimental results demonstrate that UVOSAM significantly outperforms current mask-supervised methods. These findings suggest that UVOSAM has the potential to improve unsupervised video object segmentation and reduce the cost of manual annotation.
Towards Robust Video Instance Segmentation with Temporal-Aware Transformer
Jan 20, 2023Most existing transformer based video instance segmentation methods extract per frame features independently, hence it is challenging to solve the appearance deformation problem. In this paper, we observe the temporal information is important as well and we propose TAFormer to aggregate spatio-temporal features both in transformer encoder and decoder. Specifically, in transformer encoder, we propose a novel spatio-temporal joint multi-scale deformable attention module which dynamically integrates the spatial and temporal information to obtain enriched spatio-temporal features. In transformer decoder, we introduce a temporal self-attention module to enhance the frame level box queries with the temporal relation. Moreover, TAFormer adopts an instance level contrastive loss to increase the discriminability of instance query embeddings. Therefore the tracking error caused by visually similar instances can be decreased. Experimental results show that TAFormer effectively leverages the spatial and temporal information to obtain context-aware feature representation and outperforms state-of-the-art methods.
RCP: Recurrent Closest Point for Scene Flow Estimation on 3D Point Clouds
May 24, 2022
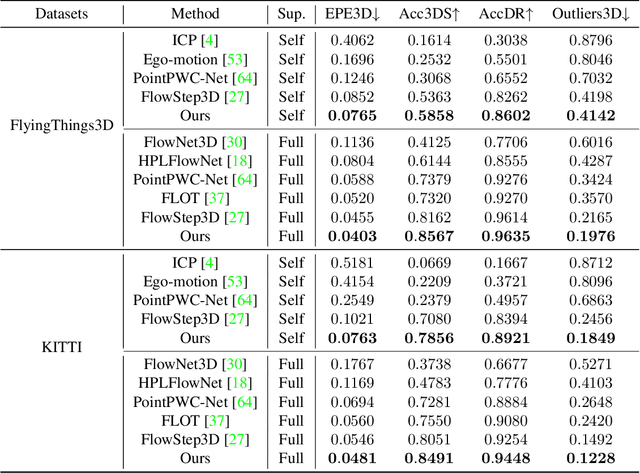
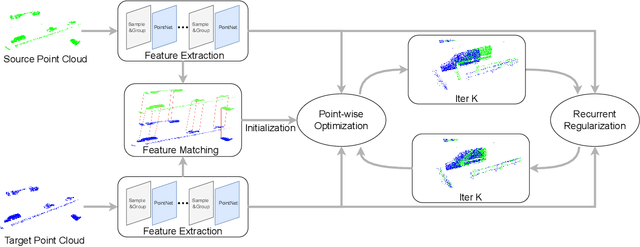
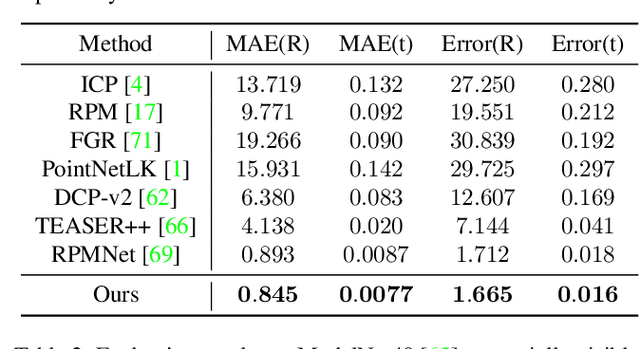
3D motion estimation including scene flow and point cloud registration has drawn increasing interest. Inspired by 2D flow estimation, recent methods employ deep neural networks to construct the cost volume for estimating accurate 3D flow. However, these methods are limited by the fact that it is difficult to define a search window on point clouds because of the irregular data structure. In this paper, we avoid this irregularity by a simple yet effective method.We decompose the problem into two interlaced stages, where the 3D flows are optimized point-wisely at the first stage and then globally regularized in a recurrent network at the second stage. Therefore, the recurrent network only receives the regular point-wise information as the input. In the experiments, we evaluate the proposed method on both the 3D scene flow estimation and the point cloud registration task. For 3D scene flow estimation, we make comparisons on the widely used FlyingThings3D and KITTIdatasets. For point cloud registration, we follow previous works and evaluate the data pairs with large pose and partially overlapping from ModelNet40. The results show that our method outperforms the previous method and achieves a new state-of-the-art performance on both 3D scene flow estimation and point cloud registration, which demonstrates the superiority of the proposed zero-order method on irregular point cloud data.
NeW CRFs: Neural Window Fully-connected CRFs for Monocular Depth Estimation
Mar 03, 2022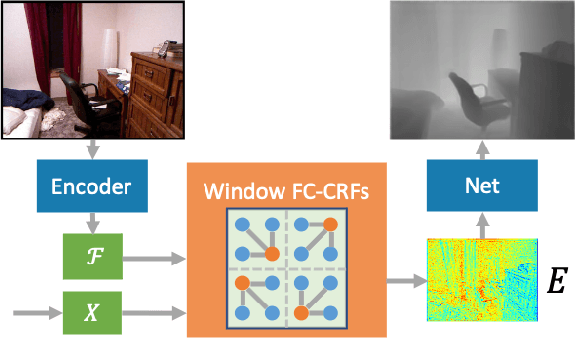
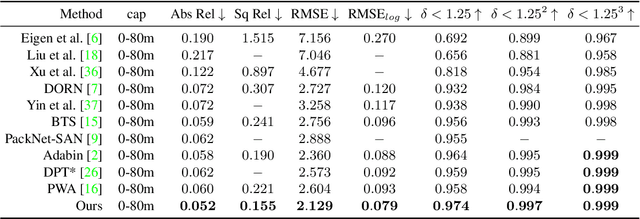
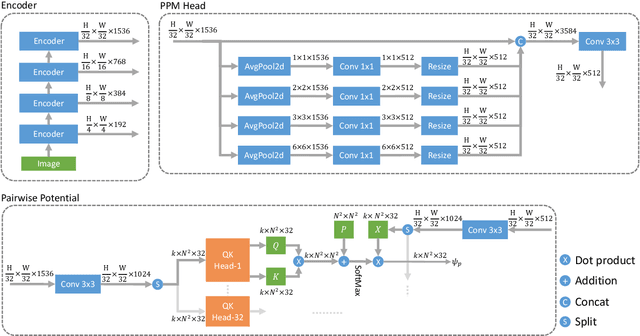
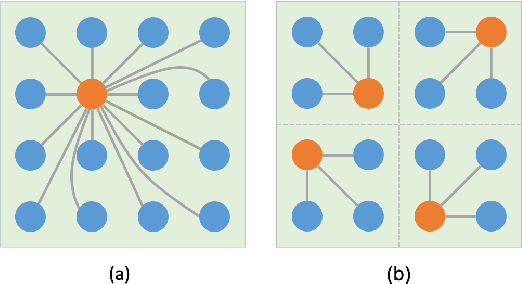
Estimating the accurate depth from a single image is challenging since it is inherently ambiguous and ill-posed. While recent works design increasingly complicated and powerful networks to directly regress the depth map, we take the path of CRFs optimization. Due to the expensive computation, CRFs are usually performed between neighborhoods rather than the whole graph. To leverage the potential of fully-connected CRFs, we split the input into windows and perform the FC-CRFs optimization within each window, which reduces the computation complexity and makes FC-CRFs feasible. To better capture the relationships between nodes in the graph, we exploit the multi-head attention mechanism to compute a multi-head potential function, which is fed to the networks to output an optimized depth map. Then we build a bottom-up-top-down structure, where this neural window FC-CRFs module serves as the decoder, and a vision transformer serves as the encoder. The experiments demonstrate that our method significantly improves the performance across all metrics on both the KITTI and NYUv2 datasets, compared to previous methods. Furthermore, the proposed method can be directly applied to panorama images and outperforms all previous panorama methods on the MatterPort3D dataset. The source code of our method will be made public.