 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Text-Video Retrieval with Frozen Image Encoders
Jul 14, 2023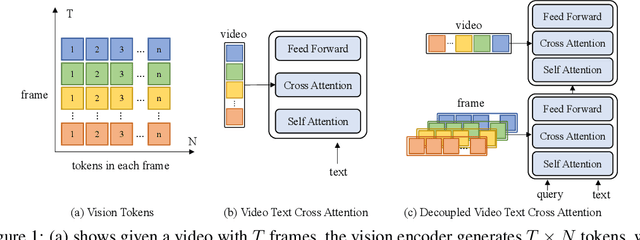
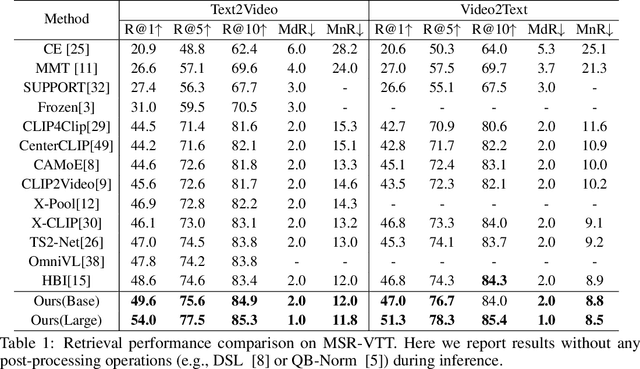
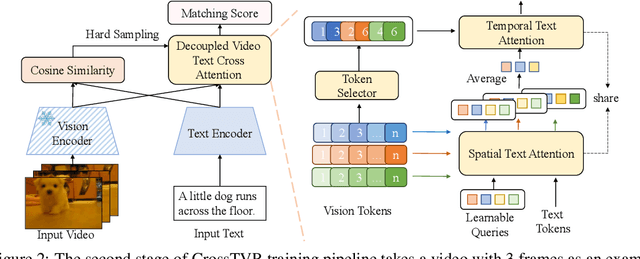

State-of-the-art text-video retrieval (TVR) methods typically utilize CLIP and cosine similarity for efficient retrieval. Meanwhile, cross attention methods, which employ a transformer decoder to compute attention between each text query and all frames in a video, offer a more comprehensive interaction between text and videos. However, these methods lack important fine-grained spatial information as they directly compute attention between text and video-level tokens. To address this issue, we propose CrossTVR, a two-stage text-video retrieval architecture. In the first stage, we leverage existing TVR methods with cosine similarity network for efficient text/video candidate selection. In the second stage, we propose a novel decoupled video text cross attention module to capture fine-grained multimodal information in spatial and temporal dimensions. Additionally, we employ the frozen CLIP model strategy in fine-grained retrieval, enabling scalability to larger pre-trained vision models like ViT-G, resulting in improved retrieval performance. Experiments on text video retrieval datasets demonstrate the effectiveness and scalability of our proposed CrossTVR compared to state-of-the-art approaches.
Towards Robust Video Instance Segmentation with Temporal-Aware Transformer
Jan 20, 2023Most existing transformer based video instance segmentation methods extract per frame features independently, hence it is challenging to solve the appearance deformation problem. In this paper, we observe the temporal information is important as well and we propose TAFormer to aggregate spatio-temporal features both in transformer encoder and decoder. Specifically, in transformer encoder, we propose a novel spatio-temporal joint multi-scale deformable attention module which dynamically integrates the spatial and temporal information to obtain enriched spatio-temporal features. In transformer decoder, we introduce a temporal self-attention module to enhance the frame level box queries with the temporal relation. Moreover, TAFormer adopts an instance level contrastive loss to increase the discriminability of instance query embeddings. Therefore the tracking error caused by visually similar instances can be decreased. Experimental results show that TAFormer effectively leverages the spatial and temporal information to obtain context-aware feature representation and outperforms state-of-the-art methods.
Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision
Jul 13, 2020
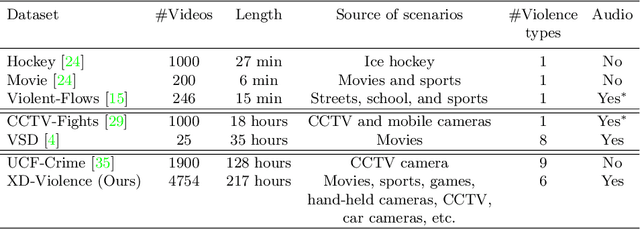
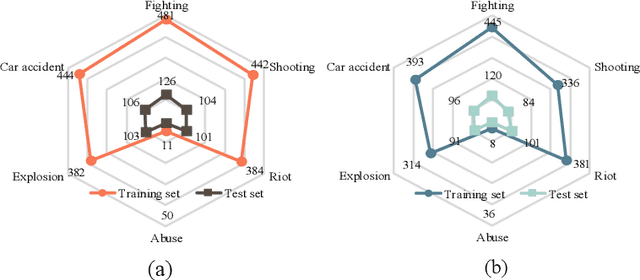
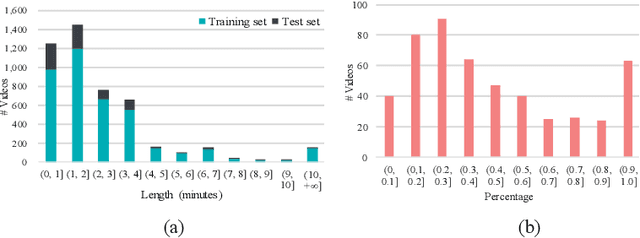
Violence detection has been studied in computer vision for years. However, previous work are either superficial, e.g., classification of short-clips, and the single scenario, or undersupplied, e.g., the single modality, and hand-crafted features based multimodality. To address this problem, in this work we first release a large-scale and multi-scene dataset named XD-Violence with a total duration of 217 hours, containing 4754 untrimmed videos with audio signals and weak labels. Then we propose a neural network containing three parallel branches to capture different relations among video snippets and integrate features, where holistic branch captures long-range dependencies using similarity prior, localized branch captures local positional relation using proximity prior, and score branch dynamically captures the closeness of predicted score. Besides, our method also includes an approximator to meet the needs of online detection. Our method outperforms other state-of-the-art methods on our released dataset and other existing benchmark. Moreover, extensive experimental results also show the positive effect of multimodal (audio-visual) input and modeling relationships. The code and dataset will be released in https://roc-ng.github.io/XD-Violence/.