 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Far and Clearly: Mitigating Hallucinations in MLLMs with Attention Causal Decoding
May 22, 2025Recent advancements in multimodal large language models (MLLMs) have significantly improved performance in visual question answering. However, they often suffer from hallucinations. In this work, hallucinations are categorized into two main types: initial hallucinations and snowball hallucinations. We argue that adequate contextual information can be extracted directly from the token interaction process. Inspired by causal inference in the decoding strategy, we propose to leverage causal masks to establish information propagation between multimodal tokens. The hypothesis is that insufficient interaction between those tokens may lead the model to rely on outlier tokens, overlooking dense and rich contextual cues. Therefore, we propose to intervene in the propagation process by tackling outlier tokens to enhance in-context inference. With this goal, we present FarSight, a versatile plug-and-play decoding strategy to reduce attention interference from outlier tokens merely by optimizing the causal mask. The heart of our method is effective token propagation. We design an attention register structure within the upper triangular matrix of the causal mask, dynamically allocating attention to capture attention diverted to outlier tokens. Moreover, a positional awareness encoding method with a diminishing masking rate is proposed, allowing the model to attend to further preceding tokens, especially for video sequence tasks. With extensive experiments, FarSight demonstrates significant hallucination-mitigating performance across different MLLMs on both image and video benchmarks, proving its effectiveness.
Efficient training for large-scale optical neural network using an evolutionary strategy and attention pruning
May 19, 2025MZI-based block optical neural networks (BONNs), which can achieve large-scale network models, have increasingly drawn attentions. However, the robustness of the current training algorithm is not high enough. Moreover, large-scale BONNs usually contain numerous trainable parameters, resulting in expensive computation and power consumption. In this article, by pruning matrix blocks and directly optimizing the individuals in population, we propose an on-chip covariance matrix adaptation evolution strategy and attention-based pruning (CAP) algorithm for large-scale BONNs. The calculated results demonstrate that the CAP algorithm can prune 60% and 80% of the parameters for MNIST and Fashion-MNIST datasets, respectively, while only degrades the performance by 3.289% and 4.693%. Considering the influence of dynamic noise in phase shifters, our proposed CAP algorithm (performance degradation of 22.327% for MNIST dataset and 24.019% for Fashion-MNIST dataset utilizing a poor fabricated chip and electrical control with a standard deviation of 0.5) exhibits strongest robustness compared with both our previously reported block adjoint training algorithm (43.963% and 41.074%) and the covariance matrix adaptation evolution strategy (25.757% and 32.871%), respectively. Moreover, when 60% of the parameters are pruned, the CAP algorithm realizes 88.5% accuracy in experiment for the simplified MNIST dataset, which is similar to the simulation result without noise (92.1%). Additionally, we simulationally and experimentally demonstrate that using MZIs with only internal phase shifters to construct BONNs is an efficient way to reduce both the system area and the required trainable parameters. Notably, our proposed CAP algorithm show excellent potential for larger-scale network models and more complex tasks.
SlowFastVAD: Video Anomaly Detection via Integrating Simple Detector and RAG-Enhanced Vision-Language Model
Apr 14, 2025Video anomaly detection (VAD) aims to identify unexpected events in videos and has wide applications in safety-critical domains. While semi-supervised methods trained on only normal samples have gained traction, they often suffer from high false alarm rates and poor interpretability. Recently, vision-language models (VLMs) have demonstrated strong multimodal reasoning capabilities, offering new opportunities for explainable anomaly detection. However, their high computational cost and lack of domain adaptation hinder real-time deployment and reliability. Inspired by dual complementary pathways in human visual perception, we propose SlowFastVAD, a hybrid framework that integrates a fast anomaly detector with a slow anomaly detector (namely a retrieval augmented generation (RAG) enhanced VLM), to address these limitations. Specifically, the fast detector first provides coarse anomaly confidence scores, and only a small subset of ambiguous segments, rather than the entire video, is further analyzed by the slower yet more interpretable VLM for elaborate detection and reasoning. Furthermore, to adapt VLMs to domain-specific VAD scenarios, we construct a knowledge base including normal patterns based on few normal samples and abnormal patterns inferred by VLMs. During inference, relevant patterns are retrieved and used to augment prompts for anomaly reasoning. Finally, we smoothly fuse the anomaly confidence of fast and slow detectors to enhance robustness of anomaly detection. Extensive experiments on four benchmarks demonstrate that SlowFastVAD effectively combines the strengths of both fast and slow detectors, and achieves remarkable detection accuracy and interpretability with significantly reduced computational overhead, making it well-suited for real-world VAD applications with high reliability requirements.
AssistPDA: An Online Video Surveillance Assistant for Video Anomaly Prediction, Detection, and Analysis
Mar 27, 2025The rapid advancements in large language models (LLMs) have spurred growing interest in LLM-based video anomaly detection (VAD). However, existing approaches predominantly focus on video-level anomaly question answering or offline detection, ignoring the real-time nature essential for practical VAD applications. To bridge this gap and facilitate the practical deployment of LLM-based VAD, we introduce AssistPDA, the first online video anomaly surveillance assistant that unifies video anomaly prediction, detection, and analysis (VAPDA) within a single framework. AssistPDA enables real-time inference on streaming videos while supporting interactive user engagement. Notably, we introduce a novel event-level anomaly prediction task, enabling proactive anomaly forecasting before anomalies fully unfold. To enhance the ability to model intricate spatiotemporal relationships in anomaly events, we propose a Spatio-Temporal Relation Distillation (STRD) module. STRD transfers the long-term spatiotemporal modeling capabilities of vision-language models (VLMs) from offline settings to real-time scenarios. Thus it equips AssistPDA with a robust understanding of complex temporal dependencies and long-sequence memory. Additionally, we construct VAPDA-127K, the first large-scale benchmark designed for VLM-based online VAPDA. Extensive experiments demonstrate that AssistPDA outperforms existing offline VLM-based approaches, setting a new state-of-the-art for real-time VAPDA. Our dataset and code will be open-sourced to facilitate further research in the community.
Exploring CLIP's Dense Knowledge for Weakly Supervised Semantic Segmentation
Mar 26, 2025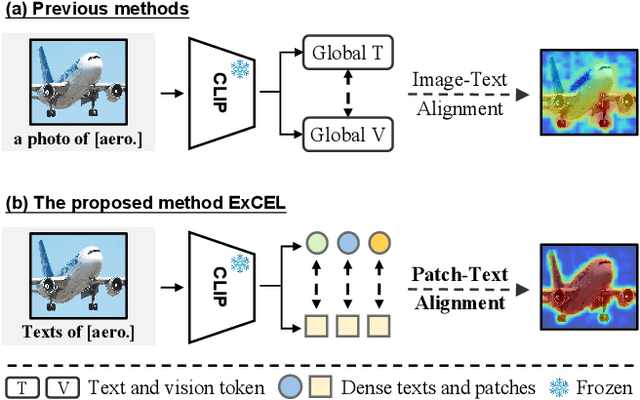


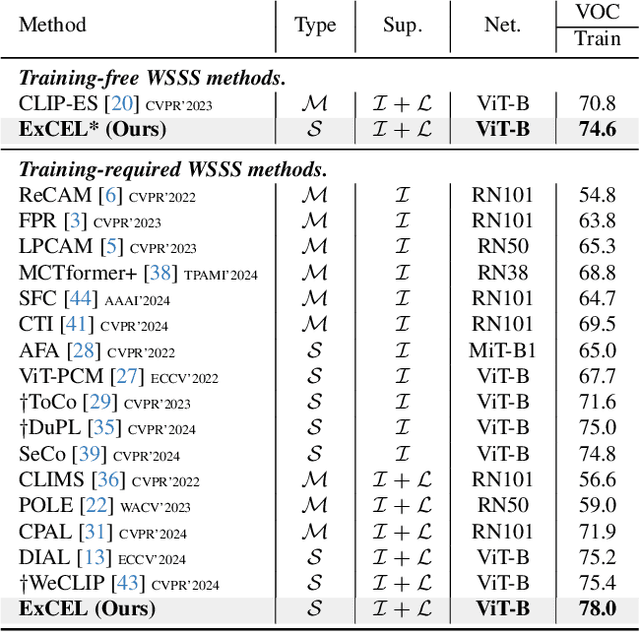
Weakly Supervised Semantic Segmentation (WSSS) with image-level labels aims to achieve pixel-level predictions using Class Activation Maps (CAMs). Recently, Contrastive Language-Image Pre-training (CLIP) has been introduced in WSSS. However, recent methods primarily focus on image-text alignment for CAM generation, while CLIP's potential in patch-text alignment remains unexplored. In this work, we propose ExCEL to explore CLIP's dense knowledge via a novel patch-text alignment paradigm for WSSS. Specifically, we propose Text Semantic Enrichment (TSE) and Visual Calibration (VC) modules to improve the dense alignment across both text and vision modalities. To make text embeddings semantically informative, our TSE module applies Large Language Models (LLMs) to build a dataset-wide knowledge base and enriches the text representations with an implicit attribute-hunting process. To mine fine-grained knowledge from visual features, our VC module first proposes Static Visual Calibration (SVC) to propagate fine-grained knowledge in a non-parametric manner. Then Learnable Visual Calibration (LVC) is further proposed to dynamically shift the frozen features towards distributions with diverse semantics. With these enhancements, ExCEL not only retains CLIP's training-free advantages but also significantly outperforms other state-of-the-art methods with much less training cost on PASCAL VOC and MS COCO.
DM-Mamba: Dual-domain Multi-scale Mamba for MRI reconstruction
Jan 14, 2025The accelerated MRI reconstruction poses a challenging ill-posed inverse problem due to the significant undersampling in k-space. Deep neural networks, such as CNNs and ViT, have shown substantial performance improvements for this task while encountering the dilemma between global receptive fields and efficient computation. To this end, this paper pioneers exploring Mamba, a new paradigm for long-range dependency modeling with linear complexity, for efficient and effective MRI reconstruction. However, directly applying Mamba to MRI reconstruction faces three significant issues: (1) Mamba's row-wise and column-wise scanning disrupts k-space's unique spectrum, leaving its potential in k-space learning unexplored. (2) Existing Mamba methods unfold feature maps with multiple lengthy scanning paths, leading to long-range forgetting and high computational burden. (3) Mamba struggles with spatially-varying contents, resulting in limited diversity of local representations. To address these, we propose a dual-domain multi-scale Mamba for MRI reconstruction from the following perspectives: (1) We pioneer vision Mamba in k-space learning. A circular scanning is customized for spectrum unfolding, benefiting the global modeling of k-space. (2) We propose a multi-scale Mamba with an efficient scanning strategy in both image and k-space domains. It mitigates long-range forgetting and achieves a better trade-off between efficiency and performance. (3) We develop a local diversity enhancement module to improve the spatially-varying representation of Mamba. Extensive experiments are conducted on three public datasets for MRI reconstruction under various undersampling patterns. Comprehensive results demonstrate that our method significantly outperforms state-of-the-art methods with lower computational cost. Implementation code will be available at https://github.com/XiaoMengLiLiLi/DM-Mamba.
MoRe: Class Patch Attention Needs Regularization for Weakly Supervised Semantic Segmentation
Dec 15, 2024



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels typically uses Class Activation Maps (CAM) to achieve dense predictions. Recently, Vision Transformer (ViT) has provided an alternative to generate localization maps from class-patch attention. However, due to insufficient constraints on modeling such attention, we observe that the Localization Attention Maps (LAM) often struggle with the artifact issue, i.e., patch regions with minimal semantic relevance are falsely activated by class tokens. In this work, we propose MoRe to address this issue and further explore the potential of LAM. Our findings suggest that imposing additional regularization on class-patch attention is necessary. To this end, we first view the attention as a novel directed graph and propose the Graph Category Representation module to implicitly regularize the interaction among class-patch entities. It ensures that class tokens dynamically condense the related patch information and suppress unrelated artifacts at a graph level. Second, motivated by the observation that CAM from classification weights maintains smooth localization of objects, we devise the Localization-informed Regularization module to explicitly regularize the class-patch attention. It directly mines the token relations from CAM and further supervises the consistency between class and patch tokens in a learnable manner. Extensive experiments are conducted on PASCAL VOC and MS COCO, validating that MoRe effectively addresses the artifact issue and achieves state-of-the-art performance, surpassing recent single-stage and even multi-stage methods. Code is available at https://github.com/zwyang6/MoRe.
Towards Effective, Efficient and Unsupervised Social Event Detection in the Hyperbolic Space
Dec 14, 2024



The vast, complex, and dynamic nature of social message data has posed challenges to social event detection (SED). Despite considerable effort, these challenges persist, often resulting in inadequately expressive message representations (ineffective) and prolonged learning durations (inefficient). In response to the challenges, this work introduces an unsupervised framework, HyperSED (Hyperbolic SED). Specifically, the proposed framework first models social messages into semantic-based message anchors, and then leverages the structure of the anchor graph and the expressiveness of the hyperbolic space to acquire structure- and geometry-aware anchor representations. Finally, HyperSED builds the partitioning tree of the anchor message graph by incorporating differentiable structural information as the reflection of the detected events. Extensive experiments on public datasets demonstrate HyperSED's competitive performance, along with a substantial improvement in efficiency compared to the current state-of-the-art unsupervised paradigm. Statistically, HyperSED boosts incremental SED by an average of 2%, 2%, and 25% in NMI, AMI, and ARI, respectively; enhancing efficiency by up to 37.41 times and at least 12.10 times, illustrating the advancement of the proposed framework. Our code is publicly available at https://github.com/XiaoyanWork/HyperSED.
Boosting ViT-based MRI Reconstruction from the Perspectives of Frequency Modulation, Spatial Purification, and Scale Diversification
Dec 14, 2024The accelerated MRI reconstruction process presents a challenging ill-posed inverse problem due to the extensive under-sampling in k-space. Recently, Vision Transformers (ViTs) have become the mainstream for this task, demonstrating substantial performance improvements. However, there are still three significant issues remain unaddressed: (1) ViTs struggle to capture high-frequency components of images, limiting their ability to detect local textures and edge information, thereby impeding MRI restoration; (2) Previous methods calculate multi-head self-attention (MSA) among both related and unrelated tokens in content, introducing noise and significantly increasing computational burden; (3) The naive feed-forward network in ViTs cannot model the multi-scale information that is important for image restoration. In this paper, we propose FPS-Former, a powerful ViT-based framework, to address these issues from the perspectives of frequency modulation, spatial purification, and scale diversification. Specifically, for issue (1), we introduce a frequency modulation attention module to enhance the self-attention map by adaptively re-calibrating the frequency information in a Laplacian pyramid. For issue (2), we customize a spatial purification attention module to capture interactions among closely related tokens, thereby reducing redundant or irrelevant feature representations. For issue (3), we propose an efficient feed-forward network based on a hybrid-scale fusion strategy. Comprehensive experiments conducted on three public datasets show that our FPS-Former outperforms state-of-the-art methods while requiring lower computational costs.
Continuous K-space Recovery Network with Image Guidance for Fast MRI Reconstruction
Nov 18, 2024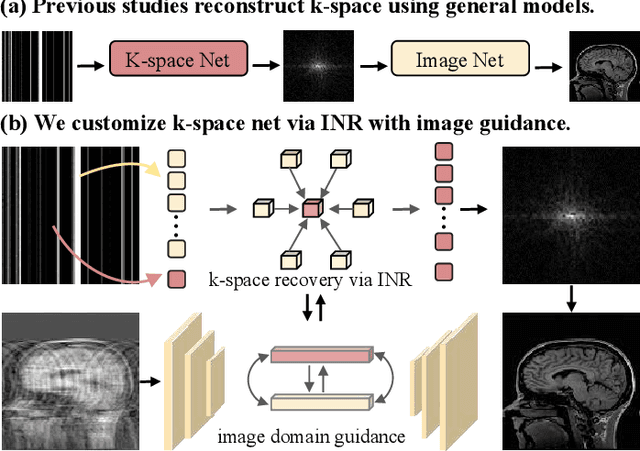
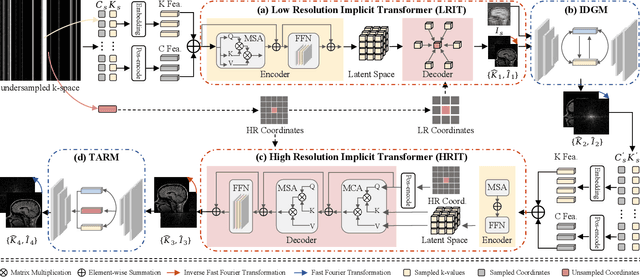
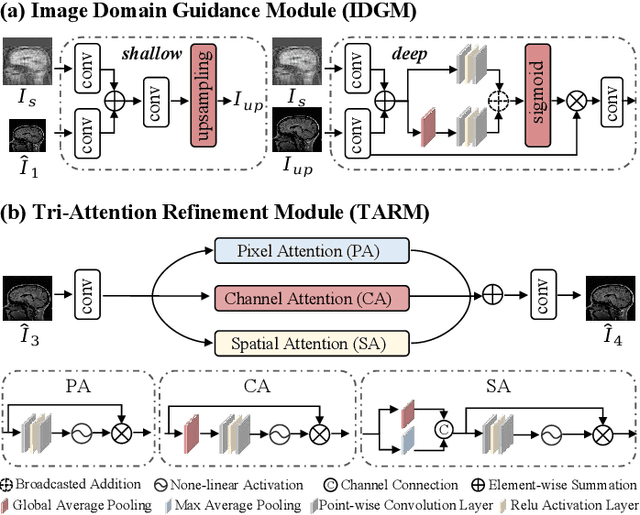
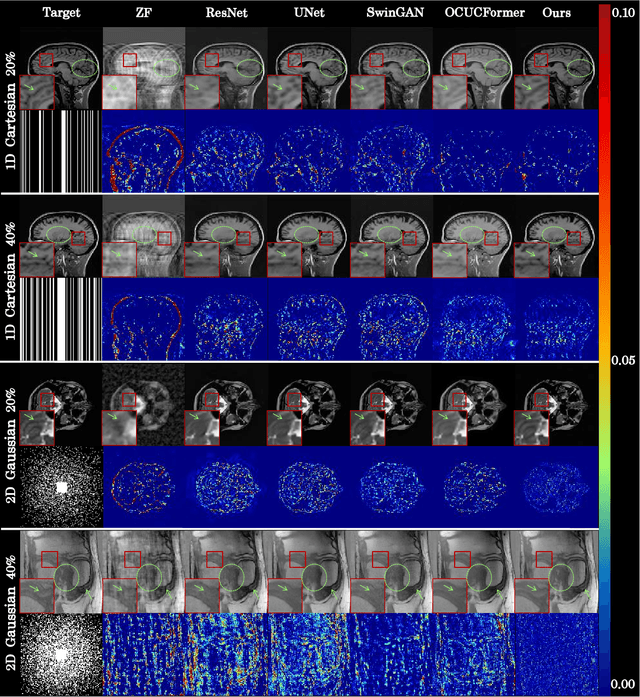
Magnetic resonance imaging (MRI) is a crucial tool for clinical diagnosis while facing the challenge of long scanning time. To reduce the acquisition time, fast MRI reconstruction aims to restore high-quality images from the undersampled k-space. Existing methods typically train deep learning models to map the undersampled data to artifact-free MRI images. However, these studies often overlook the unique properties of k-space and directly apply general networks designed for image processing to k-space recovery, leaving the precise learning of k-space largely underexplored. In this work, we propose a continuous k-space recovery network from a new perspective of implicit neural representation with image domain guidance, which boosts the performance of MRI reconstruction. Specifically, (1) an implicit neural representation based encoder-decoder structure is customized to continuously query unsampled k-values. (2) an image guidance module is designed to mine the semantic information from the low-quality MRI images to further guide the k-space recovery. (3) a multi-stage training strategy is proposed to recover dense k-space progressively. Extensive experiments conducted on CC359, fastMRI, and IXI datasets demonstrate the effectiveness of our method and its superiority over other competitors.