 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHUR-MACL: High-Uncertainty Region-Guided Multi-Architecture Collaborative Learning for Head and Neck Multi-Organ Segmentation
Jan 08, 2026Accurate segmentation of organs at risk in the head and neck is essential for radiation therapy, yet deep learning models often fail on small, complexly shaped organs. While hybrid architectures that combine different models show promise, they typically just concatenate features without exploiting the unique strengths of each component. This results in functional overlap and limited segmentation accuracy. To address these issues, we propose a high uncertainty region-guided multi-architecture collaborative learning (HUR-MACL) model for multi-organ segmentation in the head and neck. This model adaptively identifies high uncertainty regions using a convolutional neural network, and for these regions, Vision Mamba as well as Deformable CNN are utilized to jointly improve their segmentation accuracy. Additionally, a heterogeneous feature distillation loss was proposed to promote collaborative learning between the two architectures in high uncertainty regions to further enhance performance. Our method achieves SOTA results on two public datasets and one private dataset.
Weakly Semi-supervised Whole Slide Image Classification by Two-level Cross Consistency Supervision
Apr 16, 2025
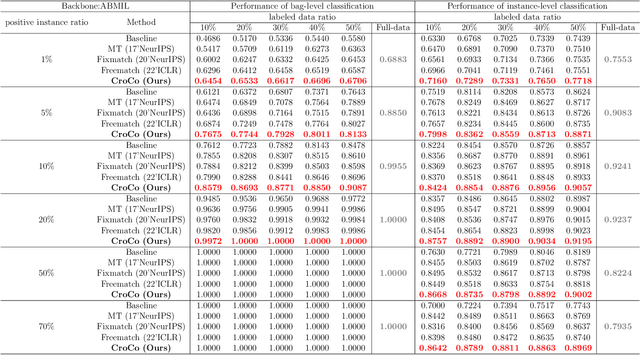
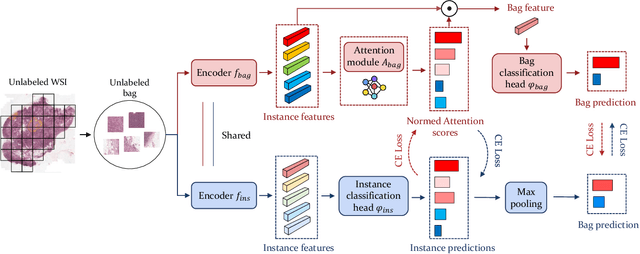
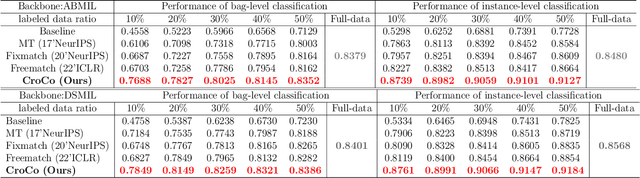
Computer-aided Whole Slide Image (WSI) classification has the potential to enhance the accuracy and efficiency of clinical pathological diagnosis. It is commonly formulated as a Multiple Instance Learning (MIL) problem, where each WSI is treated as a bag and the small patches extracted from the WSI are considered instances within that bag. However, obtaining labels for a large number of bags is a costly and time-consuming process, particularly when utilizing existing WSIs for new classification tasks. This limitation renders most existing WSI classification methods ineffective. To address this issue, we propose a novel WSI classification problem setting, more aligned with clinical practice, termed Weakly Semi-supervised Whole slide image Classification (WSWC). In WSWC, a small number of bags are labeled, while a significant number of bags remain unlabeled. The MIL nature of the WSWC problem, coupled with the absence of patch labels, distinguishes it from typical semi-supervised image classification problems, making existing algorithms for natural images unsuitable for directly solving the WSWC problem. In this paper, we present a concise and efficient framework, named CroCo, to tackle the WSWC problem through two-level Cross Consistency supervision. CroCo comprises two heterogeneous classifier branches capable of performing both instance classification and bag classification. The fundamental idea is to establish cross-consistency supervision at both the bag-level and instance-level between the two branches during training. Extensive experiments conducted on four datasets demonstrate that CroCo achieves superior bag classification and instance classification performance compared to other comparative methods when limited WSIs with bag labels are available. To the best of our knowledge, this paper presents for the first time the WSWC problem and gives a successful resolution.
Exploring CLIP's Dense Knowledge for Weakly Supervised Semantic Segmentation
Mar 26, 2025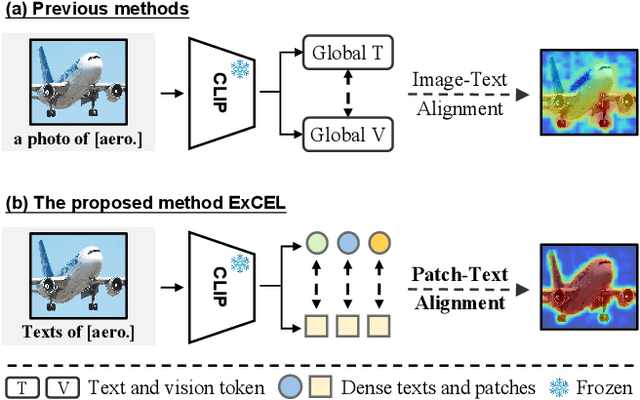


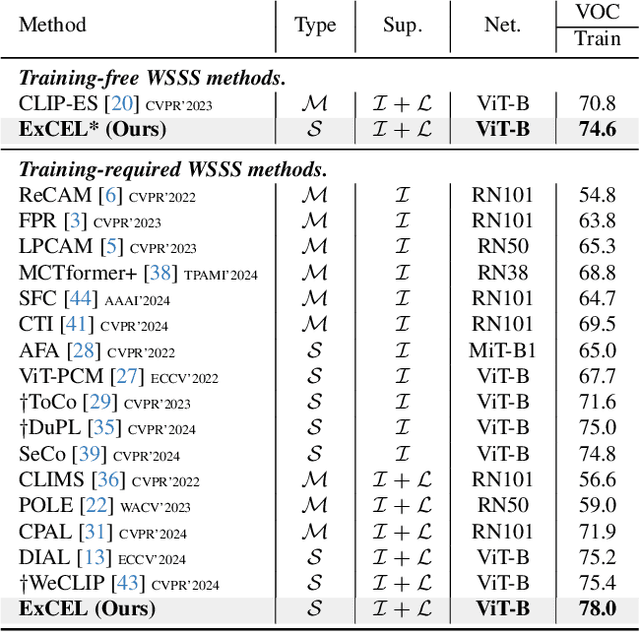
Weakly Supervised Semantic Segmentation (WSSS) with image-level labels aims to achieve pixel-level predictions using Class Activation Maps (CAMs). Recently, Contrastive Language-Image Pre-training (CLIP) has been introduced in WSSS. However, recent methods primarily focus on image-text alignment for CAM generation, while CLIP's potential in patch-text alignment remains unexplored. In this work, we propose ExCEL to explore CLIP's dense knowledge via a novel patch-text alignment paradigm for WSSS. Specifically, we propose Text Semantic Enrichment (TSE) and Visual Calibration (VC) modules to improve the dense alignment across both text and vision modalities. To make text embeddings semantically informative, our TSE module applies Large Language Models (LLMs) to build a dataset-wide knowledge base and enriches the text representations with an implicit attribute-hunting process. To mine fine-grained knowledge from visual features, our VC module first proposes Static Visual Calibration (SVC) to propagate fine-grained knowledge in a non-parametric manner. Then Learnable Visual Calibration (LVC) is further proposed to dynamically shift the frozen features towards distributions with diverse semantics. With these enhancements, ExCEL not only retains CLIP's training-free advantages but also significantly outperforms other state-of-the-art methods with much less training cost on PASCAL VOC and MS COCO.
DM-Mamba: Dual-domain Multi-scale Mamba for MRI reconstruction
Jan 14, 2025The accelerated MRI reconstruction poses a challenging ill-posed inverse problem due to the significant undersampling in k-space. Deep neural networks, such as CNNs and ViT, have shown substantial performance improvements for this task while encountering the dilemma between global receptive fields and efficient computation. To this end, this paper pioneers exploring Mamba, a new paradigm for long-range dependency modeling with linear complexity, for efficient and effective MRI reconstruction. However, directly applying Mamba to MRI reconstruction faces three significant issues: (1) Mamba's row-wise and column-wise scanning disrupts k-space's unique spectrum, leaving its potential in k-space learning unexplored. (2) Existing Mamba methods unfold feature maps with multiple lengthy scanning paths, leading to long-range forgetting and high computational burden. (3) Mamba struggles with spatially-varying contents, resulting in limited diversity of local representations. To address these, we propose a dual-domain multi-scale Mamba for MRI reconstruction from the following perspectives: (1) We pioneer vision Mamba in k-space learning. A circular scanning is customized for spectrum unfolding, benefiting the global modeling of k-space. (2) We propose a multi-scale Mamba with an efficient scanning strategy in both image and k-space domains. It mitigates long-range forgetting and achieves a better trade-off between efficiency and performance. (3) We develop a local diversity enhancement module to improve the spatially-varying representation of Mamba. Extensive experiments are conducted on three public datasets for MRI reconstruction under various undersampling patterns. Comprehensive results demonstrate that our method significantly outperforms state-of-the-art methods with lower computational cost. Implementation code will be available at https://github.com/XiaoMengLiLiLi/DM-Mamba.
MoRe: Class Patch Attention Needs Regularization for Weakly Supervised Semantic Segmentation
Dec 15, 2024



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels typically uses Class Activation Maps (CAM) to achieve dense predictions. Recently, Vision Transformer (ViT) has provided an alternative to generate localization maps from class-patch attention. However, due to insufficient constraints on modeling such attention, we observe that the Localization Attention Maps (LAM) often struggle with the artifact issue, i.e., patch regions with minimal semantic relevance are falsely activated by class tokens. In this work, we propose MoRe to address this issue and further explore the potential of LAM. Our findings suggest that imposing additional regularization on class-patch attention is necessary. To this end, we first view the attention as a novel directed graph and propose the Graph Category Representation module to implicitly regularize the interaction among class-patch entities. It ensures that class tokens dynamically condense the related patch information and suppress unrelated artifacts at a graph level. Second, motivated by the observation that CAM from classification weights maintains smooth localization of objects, we devise the Localization-informed Regularization module to explicitly regularize the class-patch attention. It directly mines the token relations from CAM and further supervises the consistency between class and patch tokens in a learnable manner. Extensive experiments are conducted on PASCAL VOC and MS COCO, validating that MoRe effectively addresses the artifact issue and achieves state-of-the-art performance, surpassing recent single-stage and even multi-stage methods. Code is available at https://github.com/zwyang6/MoRe.
Boosting ViT-based MRI Reconstruction from the Perspectives of Frequency Modulation, Spatial Purification, and Scale Diversification
Dec 14, 2024The accelerated MRI reconstruction process presents a challenging ill-posed inverse problem due to the extensive under-sampling in k-space. Recently, Vision Transformers (ViTs) have become the mainstream for this task, demonstrating substantial performance improvements. However, there are still three significant issues remain unaddressed: (1) ViTs struggle to capture high-frequency components of images, limiting their ability to detect local textures and edge information, thereby impeding MRI restoration; (2) Previous methods calculate multi-head self-attention (MSA) among both related and unrelated tokens in content, introducing noise and significantly increasing computational burden; (3) The naive feed-forward network in ViTs cannot model the multi-scale information that is important for image restoration. In this paper, we propose FPS-Former, a powerful ViT-based framework, to address these issues from the perspectives of frequency modulation, spatial purification, and scale diversification. Specifically, for issue (1), we introduce a frequency modulation attention module to enhance the self-attention map by adaptively re-calibrating the frequency information in a Laplacian pyramid. For issue (2), we customize a spatial purification attention module to capture interactions among closely related tokens, thereby reducing redundant or irrelevant feature representations. For issue (3), we propose an efficient feed-forward network based on a hybrid-scale fusion strategy. Comprehensive experiments conducted on three public datasets show that our FPS-Former outperforms state-of-the-art methods while requiring lower computational costs.
Continuous K-space Recovery Network with Image Guidance for Fast MRI Reconstruction
Nov 18, 2024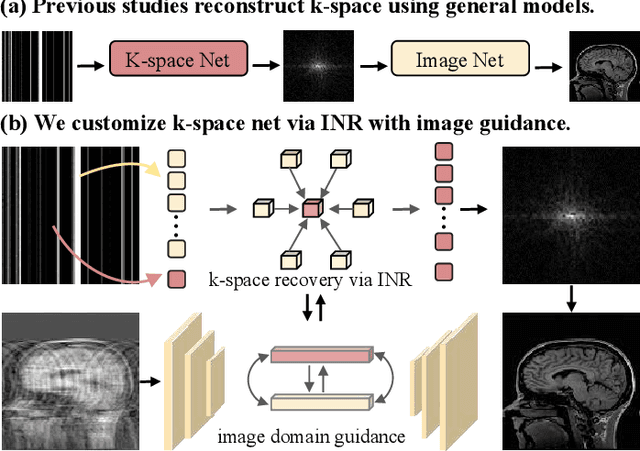
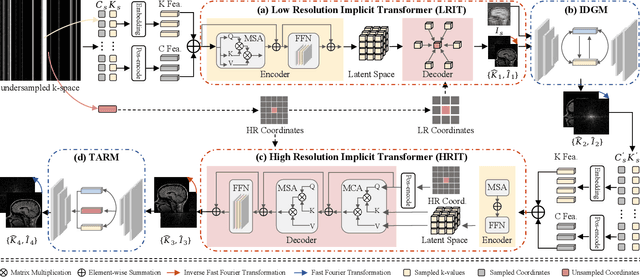
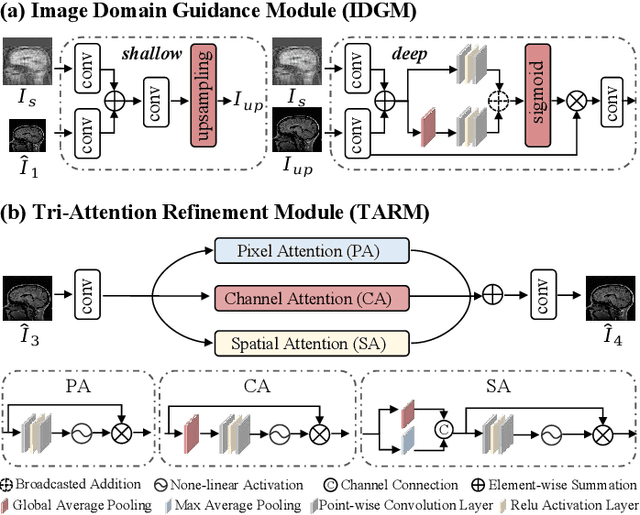
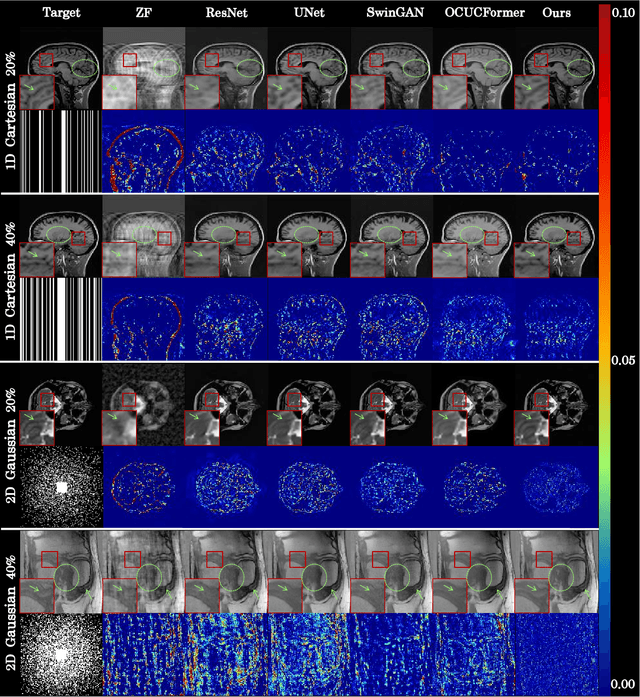
Magnetic resonance imaging (MRI) is a crucial tool for clinical diagnosis while facing the challenge of long scanning time. To reduce the acquisition time, fast MRI reconstruction aims to restore high-quality images from the undersampled k-space. Existing methods typically train deep learning models to map the undersampled data to artifact-free MRI images. However, these studies often overlook the unique properties of k-space and directly apply general networks designed for image processing to k-space recovery, leaving the precise learning of k-space largely underexplored. In this work, we propose a continuous k-space recovery network from a new perspective of implicit neural representation with image domain guidance, which boosts the performance of MRI reconstruction. Specifically, (1) an implicit neural representation based encoder-decoder structure is customized to continuously query unsampled k-values. (2) an image guidance module is designed to mine the semantic information from the low-quality MRI images to further guide the k-space recovery. (3) a multi-stage training strategy is proposed to recover dense k-space progressively. Extensive experiments conducted on CC359, fastMRI, and IXI datasets demonstrate the effectiveness of our method and its superiority over other competitors.
SP${ }^3$ : Superpixel-propagated pseudo-label learning for weakly semi-supervised medical image segmentation
Nov 18, 2024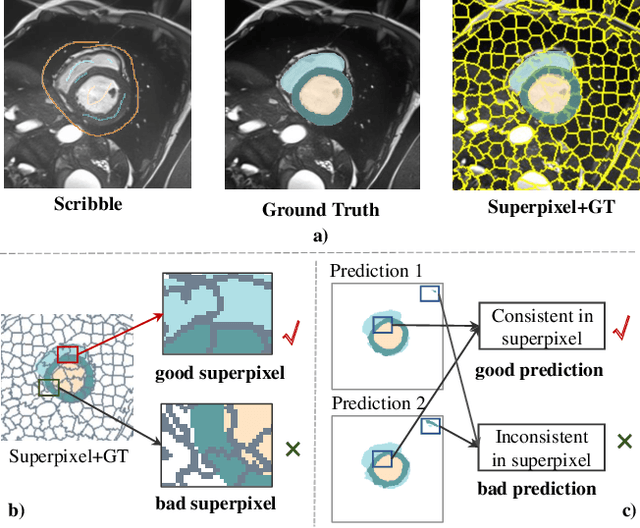



Deep learning-based medical image segmentation helps assist diagnosis and accelerate the treatment process while the model training usually requires large-scale dense annotation datasets. Weakly semi-supervised medical image segmentation is an essential application because it only requires a small amount of scribbles and a large number of unlabeled data to train the model, which greatly reduces the clinician's effort to fully annotate images. To handle the inadequate supervisory information challenge in weakly semi-supervised segmentation (WSSS), a SuperPixel-Propagated Pseudo-label (SP${}^3$) learning method is proposed, using the structural information contained in superpixel for supplemental information. Specifically, the annotation of scribbles is propagated to superpixels and thus obtains a dense annotation for supervised training. Since the quality of pseudo-labels is limited by the low-quality annotation, the beneficial superpixels selected by dynamic thresholding are used to refine pseudo-labels. Furthermore, aiming to alleviate the negative impact of noise in pseudo-label, superpixel-level uncertainty is incorporated to guide the pseudo-label supervision for stable learning. Our method achieves state-of-the-art performance on both tumor and organ segmentation datasets under the WSSS setting, using only 3\% of the annotation workload compared to fully supervised methods and attaining approximately 80\% Dice score. Additionally, our method outperforms eight weakly and semi-supervised methods under both weakly supervised and semi-supervised settings. Results of extensive experiments validate the effectiveness and annotation efficiency of our weakly semi-supervised segmentation, which can assist clinicians in achieving automated segmentation for organs or tumors quickly and ultimately benefit patients.
Deep Mutual Learning among Partially Labeled Datasets for Multi-Organ Segmentation
Jul 17, 2024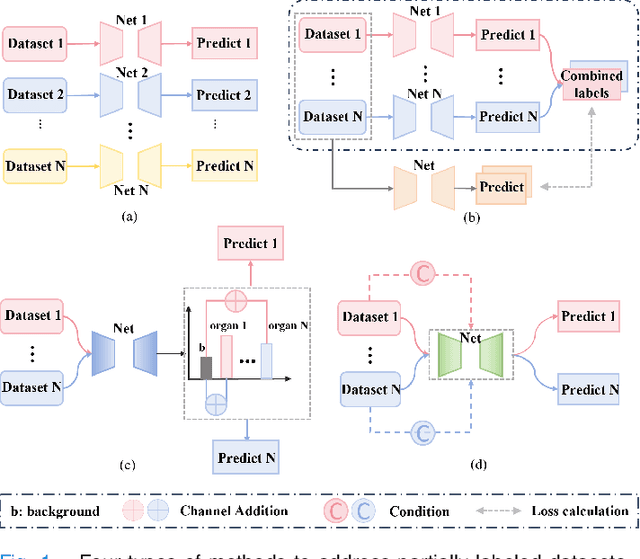
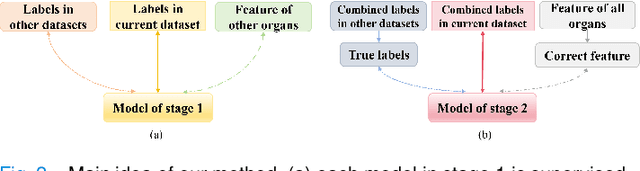
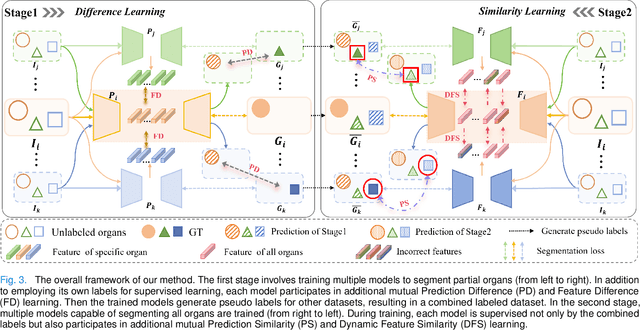
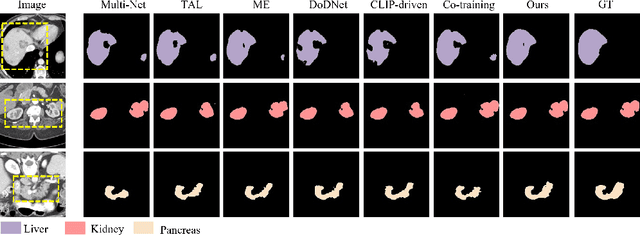
The task of labeling multiple organs for segmentation is a complex and time-consuming process, resulting in a scarcity of comprehensively labeled multi-organ datasets while the emergence of numerous partially labeled datasets. Current methods are inadequate in effectively utilizing the supervised information available from these datasets, thereby impeding the progress in improving the segmentation accuracy. This paper proposes a two-stage multi-organ segmentation method based on mutual learning, aiming to improve multi-organ segmentation performance by complementing information among partially labeled datasets. In the first stage, each partial-organ segmentation model utilizes the non-overlapping organ labels from different datasets and the distinct organ features extracted by different models, introducing additional mutual difference learning to generate higher quality pseudo labels for unlabeled organs. In the second stage, each full-organ segmentation model is supervised by fully labeled datasets with pseudo labels and leverages true labels from other datasets, while dynamically sharing accurate features across different models, introducing additional mutual similarity learning to enhance multi-organ segmentation performance. Extensive experiments were conducted on nine datasets that included the head and neck, chest, abdomen, and pelvis. The results indicate that our method has achieved SOTA performance in segmentation tasks that rely on partial labels, and the ablation studies have thoroughly confirmed the efficacy of the mutual learning mechanism.
Tackling Ambiguity from Perspective of Uncertainty Inference and Affinity Diversification for Weakly Supervised Semantic Segmentation
Apr 12, 2024Weakly supervised semantic segmentation (WSSS) with image-level labels intends to achieve dense tasks without laborious annotations. However, due to the ambiguous contexts and fuzzy regions, the performance of WSSS, especially the stages of generating Class Activation Maps (CAMs) and refining pseudo masks, widely suffers from ambiguity while being barely noticed by previous literature. In this work, we propose UniA, a unified single-staged WSSS framework, to efficiently tackle this issue from the perspective of uncertainty inference and affinity diversification, respectively. When activating class objects, we argue that the false activation stems from the bias to the ambiguous regions during the feature extraction. Therefore, we design a more robust feature representation with a probabilistic Gaussian distribution and introduce the uncertainty estimation to avoid the bias. A distribution loss is particularly proposed to supervise the process, which effectively captures the ambiguity and models the complex dependencies among features. When refining pseudo labels, we observe that the affinity from the prevailing refinement methods intends to be similar among ambiguities. To this end, an affinity diversification module is proposed to promote diversity among semantics. A mutual complementing refinement is proposed to initially rectify the ambiguous affinity with multiple inferred pseudo labels. More importantly, a contrastive affinity loss is further designed to diversify the relations among unrelated semantics, which reliably propagates the diversity into the whole feature representations and helps generate better pseudo masks. Extensive experiments are conducted on PASCAL VOC, MS COCO, and medical ACDC datasets, which validate the efficiency of UniA tackling ambiguity and the superiority over recent single-staged or even most multi-staged competitors.