 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDFP: Data-dependent Frequency Prompt for Source Free Domain Adaptation of Medical Image Segmentation
May 15, 2025Domain adaptation addresses the challenge of model performance degradation caused by domain gaps. In the typical setup for unsupervised domain adaptation, labeled data from a source domain and unlabeled data from a target domain are used to train a target model. However, access to labeled source domain data, particularly in medical datasets, can be restricted due to privacy policies. As a result, research has increasingly shifted to source-free domain adaptation (SFDA), which requires only a pretrained model from the source domain and unlabeled data from the target domain data for adaptation. Existing SFDA methods often rely on domain-specific image style translation and self-supervision techniques to bridge the domain gap and train the target domain model. However, the quality of domain-specific style-translated images and pseudo-labels produced by these methods still leaves room for improvement. Moreover, training the entire model during adaptation can be inefficient under limited supervision. In this paper, we propose a novel SFDA framework to address these challenges. Specifically, to effectively mitigate the impact of domain gap in the initial training phase, we introduce preadaptation to generate a preadapted model, which serves as an initialization of target model and allows for the generation of high-quality enhanced pseudo-labels without introducing extra parameters. Additionally, we propose a data-dependent frequency prompt to more effectively translate target domain images into a source-like style. To further enhance adaptation, we employ a style-related layer fine-tuning strategy, specifically designed for SFDA, to train the target model using the prompted target domain images and pseudo-labels. Extensive experiments on cross-modality abdominal and cardiac SFDA segmentation tasks demonstrate that our proposed method outperforms existing state-of-the-art methods.
Weakly Semi-supervised Whole Slide Image Classification by Two-level Cross Consistency Supervision
Apr 16, 2025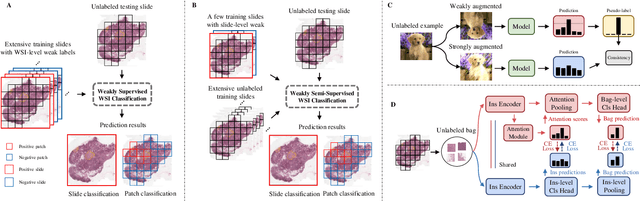
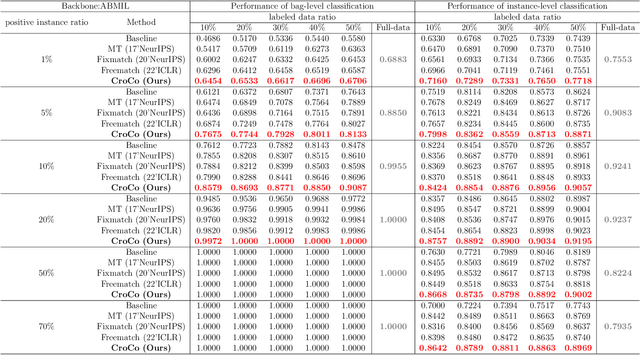
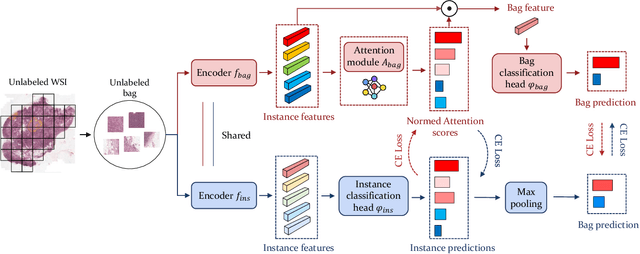
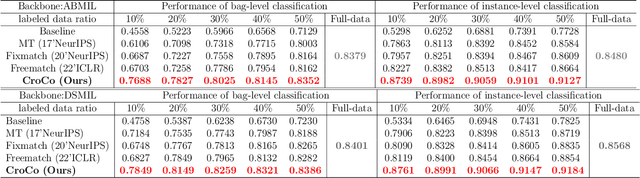
Computer-aided Whole Slide Image (WSI) classification has the potential to enhance the accuracy and efficiency of clinical pathological diagnosis. It is commonly formulated as a Multiple Instance Learning (MIL) problem, where each WSI is treated as a bag and the small patches extracted from the WSI are considered instances within that bag. However, obtaining labels for a large number of bags is a costly and time-consuming process, particularly when utilizing existing WSIs for new classification tasks. This limitation renders most existing WSI classification methods ineffective. To address this issue, we propose a novel WSI classification problem setting, more aligned with clinical practice, termed Weakly Semi-supervised Whole slide image Classification (WSWC). In WSWC, a small number of bags are labeled, while a significant number of bags remain unlabeled. The MIL nature of the WSWC problem, coupled with the absence of patch labels, distinguishes it from typical semi-supervised image classification problems, making existing algorithms for natural images unsuitable for directly solving the WSWC problem. In this paper, we present a concise and efficient framework, named CroCo, to tackle the WSWC problem through two-level Cross Consistency supervision. CroCo comprises two heterogeneous classifier branches capable of performing both instance classification and bag classification. The fundamental idea is to establish cross-consistency supervision at both the bag-level and instance-level between the two branches during training. Extensive experiments conducted on four datasets demonstrate that CroCo achieves superior bag classification and instance classification performance compared to other comparative methods when limited WSIs with bag labels are available. To the best of our knowledge, this paper presents for the first time the WSWC problem and gives a successful resolution.
Local Implicit Wavelet Transformer for Arbitrary-Scale Super-Resolution
Nov 10, 2024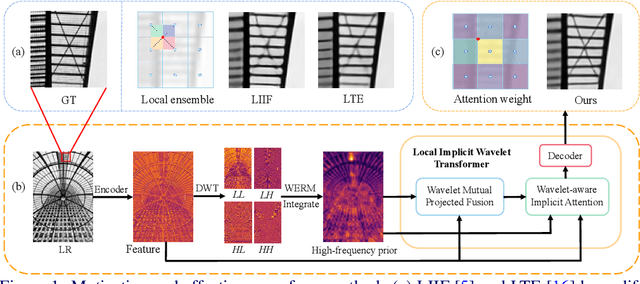
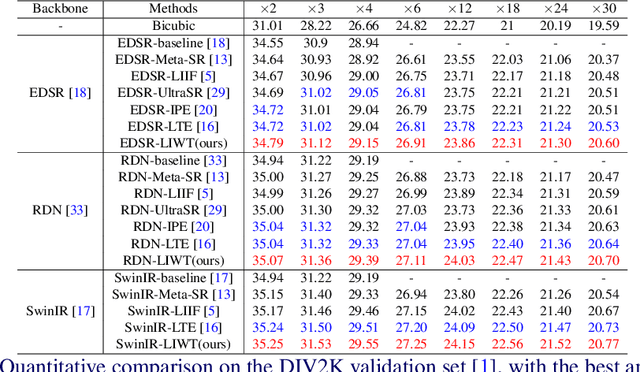


Implicit neural representations have recently demonstrated promising potential in arbitrary-scale Super-Resolution (SR) of images. Most existing methods predict the pixel in the SR image based on the queried coordinate and ensemble nearby features, overlooking the importance of incorporating high-frequency prior information in images, which results in limited performance in reconstructing high-frequency texture details in images. To address this issue, we propose the Local Implicit Wavelet Transformer (LIWT) to enhance the restoration of high-frequency texture details. Specifically, we decompose the features extracted by an encoder into four sub-bands containing different frequency information using Discrete Wavelet Transform (DWT). We then introduce the Wavelet Enhanced Residual Module (WERM) to transform these four sub-bands into high-frequency priors, followed by utilizing the Wavelet Mutual Projected Fusion (WMPF) and the Wavelet-aware Implicit Attention (WIA) to fully exploit the high-frequency prior information for recovering high-frequency details in images. We conducted extensive experiments on benchmark datasets to validate the effectiveness of LIWT. Both qualitative and quantitative results demonstrate that LIWT achieves promising performance in arbitrary-scale SR tasks, outperforming other state-of-the-art methods. The code is available at https://github.com/dmhdmhdmh/LIWT.
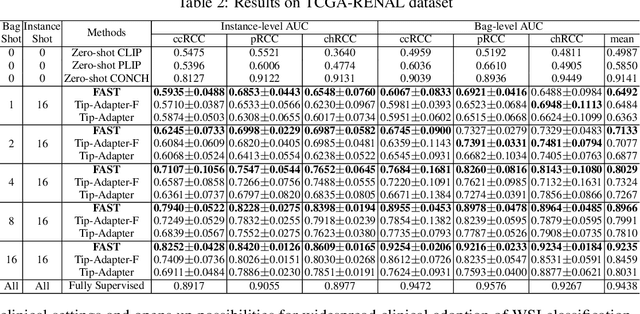
FAST: A Dual-tier Few-Shot Learning Paradigm for Whole Slide Image Classification
Sep 29, 2024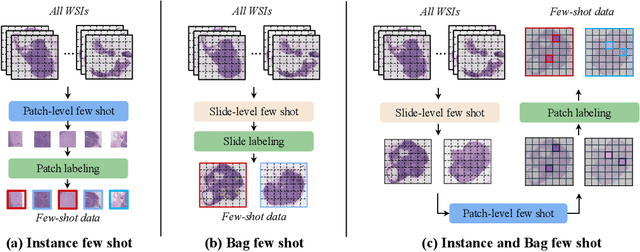
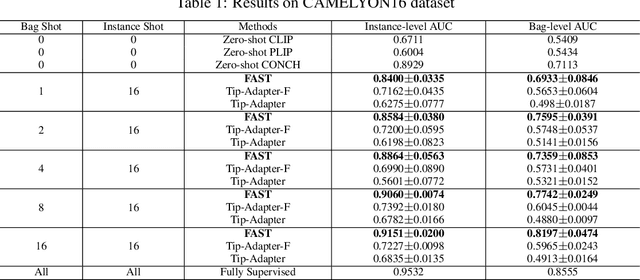
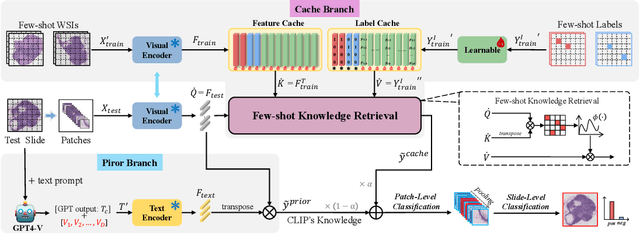
The expensive fine-grained annotation and data scarcity have become the primary obstacles for the widespread adoption of deep learning-based Whole Slide Images (WSI) classification algorithms in clinical practice. Unlike few-shot learning methods in natural images that can leverage the labels of each image, existing few-shot WSI classification methods only utilize a small number of fine-grained labels or weakly supervised slide labels for training in order to avoid expensive fine-grained annotation. They lack sufficient mining of available WSIs, severely limiting WSI classification performance. To address the above issues, we propose a novel and efficient dual-tier few-shot learning paradigm for WSI classification, named FAST. FAST consists of a dual-level annotation strategy and a dual-branch classification framework. Firstly, to avoid expensive fine-grained annotation, we collect a very small number of WSIs at the slide level, and annotate an extremely small number of patches. Then, to fully mining the available WSIs, we use all the patches and available patch labels to build a cache branch, which utilizes the labeled patches to learn the labels of unlabeled patches and through knowledge retrieval for patch classification. In addition to the cache branch, we also construct a prior branch that includes learnable prompt vectors, using the text encoder of visual-language models for patch classification. Finally, we integrate the results from both branches to achieve WSI classification. Extensive experiments on binary and multi-class datasets demonstrate that our proposed method significantly surpasses existing few-shot classification methods and approaches the accuracy of fully supervised methods with only 0.22$\%$ annotation costs. All codes and models will be publicly available on https://github.com/fukexue/FAST.
Rethinking Multiple Instance Learning: Developing an Instance-Level Classifier via Weakly-Supervised Self-Training
Aug 09, 2024Multiple instance learning (MIL) problem is currently solved from either bag-classification or instance-classification perspective, both of which ignore important information contained in some instances and result in limited performance. For example, existing methods often face difficulty in learning hard positive instances. In this paper, we formulate MIL as a semi-supervised instance classification problem, so that all the labeled and unlabeled instances can be fully utilized to train a better classifier. The difficulty in this formulation is that all the labeled instances are negative in MIL, and traditional self-training techniques used in semi-supervised learning tend to degenerate in generating pseudo labels for the unlabeled instances in this scenario. To resolve this problem, we propose a weakly-supervised self-training method, in which we utilize the positive bag labels to construct a global constraint and a local constraint on the pseudo labels to prevent them from degenerating and force the classifier to learn hard positive instances. It is worth noting that easy positive instances are instances are far from the decision boundary in the classification process, while hard positive instances are those close to the decision boundary. Through iterative optimization, the pseudo labels can gradually approach the true labels. Extensive experiments on two MNIST synthetic datasets, five traditional MIL benchmark datasets and two histopathology whole slide image datasets show that our method achieved new SOTA performance on all of them. The code will be publicly available.
Towards Arbitrary-Scale Histopathology Image Super-resolution: An Efficient Dual-branch Framework via Implicit Self-texture Enhancement
Jan 28, 2024High-quality whole-slide scanners are expensive, complex, and time-consuming, thus limiting the acquisition and utilization of high-resolution pathology whole-slide images in daily clinical work. Deep learning-based single-image super-resolution techniques are an effective way to solve this problem by synthesizing high-resolution images from low-resolution ones. However, the existing super-resolution models applied in pathology images can only work in fixed integer magnifications, significantly decreasing their applicability. Though methods based on implicit neural representation have shown promising results in arbitrary-scale super-resolution of natural images, applying them directly to pathology images is inadequate because they have unique fine-grained image textures different from natural images. Thus, we propose an Implicit Self-Texture Enhancement-based dual-branch framework (ISTE) for arbitrary-scale super-resolution of pathology images to address this challenge. ISTE contains a pixel learning branch and a texture learning branch, which first learn pixel features and texture features, respectively. Then, we design a two-stage texture enhancement strategy to fuse the features from the two branches to obtain the super-resolution results, where the first stage is feature-based texture enhancement, and the second stage is spatial-domain-based texture enhancement. Extensive experiments on three public datasets show that ISTE outperforms existing fixed-scale and arbitrary-scale algorithms at multiple magnifications and helps to improve downstream task performance. To the best of our knowledge, this is the first work to achieve arbitrary-scale super-resolution in pathology images. Codes will be available.
A comprehensive survey on deep active learning and its applications in medical image analysis
Oct 24, 2023
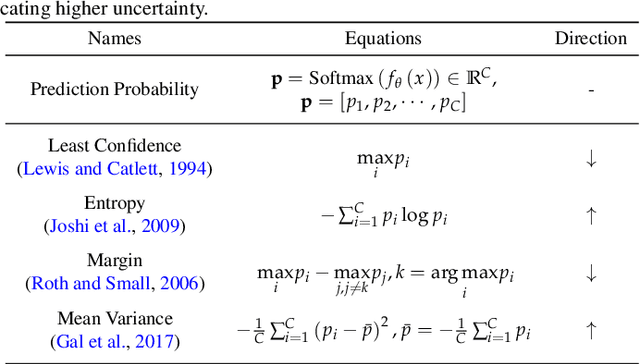
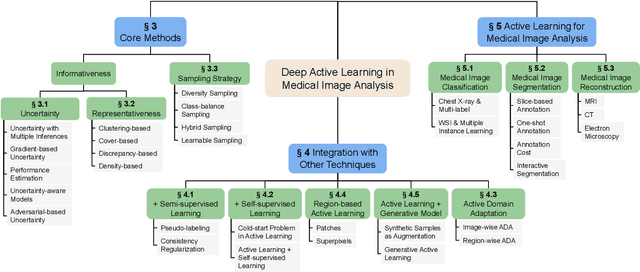
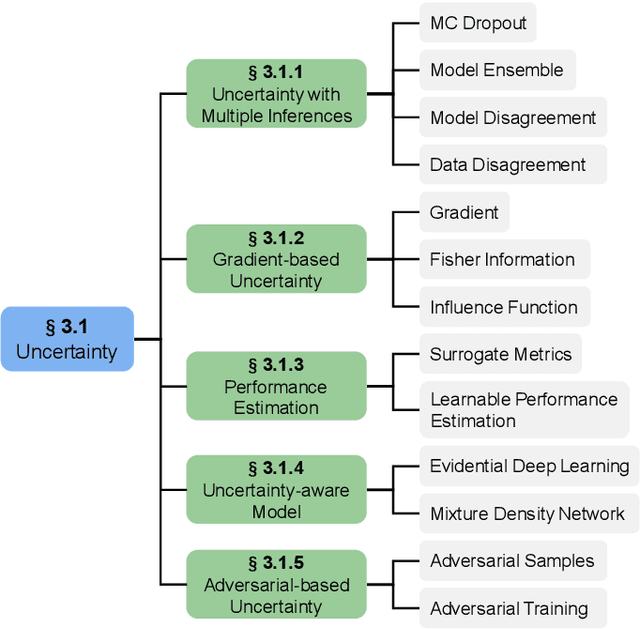
Deep learning has achieved widespread success in medical image analysis, leading to an increasing demand for large-scale expert-annotated medical image datasets. Yet, the high cost of annotating medical images severely hampers the development of deep learning in this field. To reduce annotation costs, active learning aims to select the most informative samples for annotation and train high-performance models with as few labeled samples as possible. In this survey, we review the core methods of active learning, including the evaluation of informativeness and sampling strategy. For the first time, we provide a detailed summary of the integration of active learning with other label-efficient techniques, such as semi-supervised, self-supervised learning, and so on. Additionally, we also highlight active learning works that are specifically tailored to medical image analysis. In the end, we offer our perspectives on the future trends and challenges of active learning and its applications in medical image analysis.
Knowledge Extraction and Distillation from Large-Scale Image-Text Colonoscopy Records Leveraging Large Language and Vision Models
Oct 17, 2023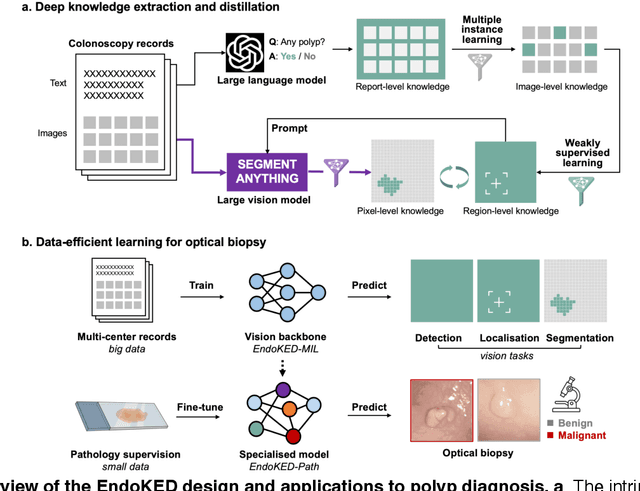
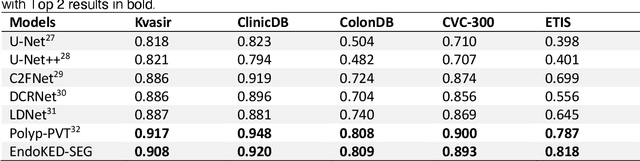
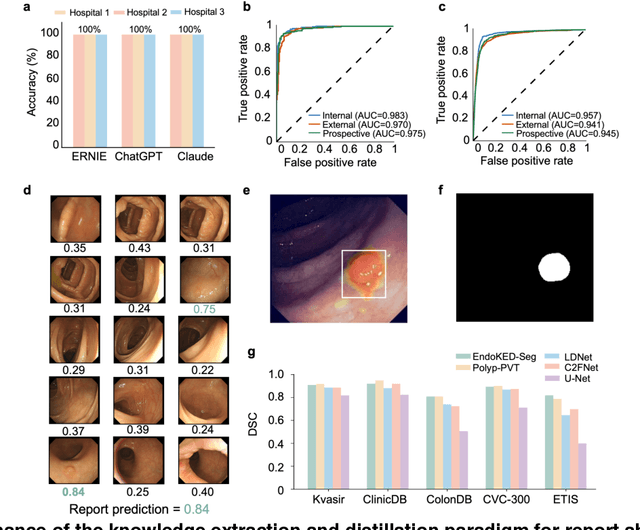
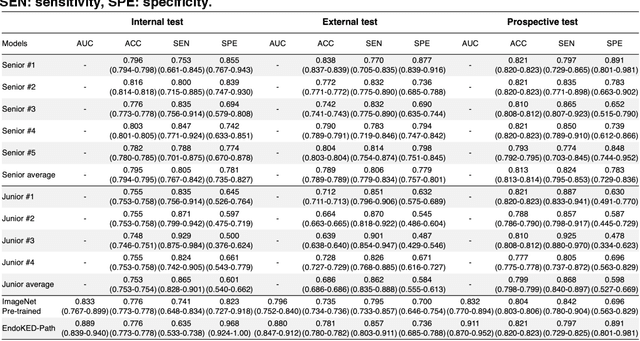
The development of artificial intelligence systems for colonoscopy analysis often necessitates expert-annotated image datasets. However, limitations in dataset size and diversity impede model performance and generalisation. Image-text colonoscopy records from routine clinical practice, comprising millions of images and text reports, serve as a valuable data source, though annotating them is labour-intensive. Here we leverage recent advancements in large language and vision models and propose EndoKED, a data mining paradigm for deep knowledge extraction and distillation. EndoKED automates the transformation of raw colonoscopy records into image datasets with pixel-level annotation. We validate EndoKED using multi-centre datasets of raw colonoscopy records (~1 million images), demonstrating its superior performance in training polyp detection and segmentation models. Furthermore, the EndoKED pre-trained vision backbone enables data-efficient and generalisable learning for optical biopsy, achieving expert-level performance in both retrospective and prospective validation.
PointMBF: A Multi-scale Bidirectional Fusion Network for Unsupervised RGB-D Point Cloud Registration
Aug 09, 2023Point cloud registration is a task to estimate the rigid transformation between two unaligned scans, which plays an important role in many computer vision applications. Previous learning-based works commonly focus on supervised registration, which have limitations in practice. Recently, with the advance of inexpensive RGB-D sensors, several learning-based works utilize RGB-D data to achieve unsupervised registration. However, most of existing unsupervised methods follow a cascaded design or fuse RGB-D data in a unidirectional manner, which do not fully exploit the complementary information in the RGB-D data. To leverage the complementary information more effectively, we propose a network implementing multi-scale bidirectional fusion between RGB images and point clouds generated from depth images. By bidirectionally fusing visual and geometric features in multi-scales, more distinctive deep features for correspondence estimation can be obtained, making our registration more accurate. Extensive experiments on ScanNet and 3DMatch demonstrate that our method achieves new state-of-the-art performance. Code will be released at https://github.com/phdymz/PointMBF
OpenAL: An Efficient Deep Active Learning Framework for Open-Set Pathology Image Classification
Jul 11, 2023Active learning (AL) is an effective approach to select the most informative samples to label so as to reduce the annotation cost. Existing AL methods typically work under the closed-set assumption, i.e., all classes existing in the unlabeled sample pool need to be classified by the target model. However, in some practical clinical tasks, the unlabeled pool may contain not only the target classes that need to be fine-grainedly classified, but also non-target classes that are irrelevant to the clinical tasks. Existing AL methods cannot work well in this scenario because they tend to select a large number of non-target samples. In this paper, we formulate this scenario as an open-set AL problem and propose an efficient framework, OpenAL, to address the challenge of querying samples from an unlabeled pool with both target class and non-target class samples. Experiments on fine-grained classification of pathology images show that OpenAL can significantly improve the query quality of target class samples and achieve higher performance than current state-of-the-art AL methods. Code is available at https://github.com/miccaiif/OpenAL.