 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Native Generative De-identification: Inversion-Free Flow for Privacy-Preserving Federated Skin Image Analysis
Jan 31, 2026The deployment of Federated Learning (FL) for clinical dermatology is hindered by the competing requirements of protecting patient privacy and preserving diagnostic features. Traditional de-identification methods often degrade pathological fidelity, while standard generative editing techniques rely on computationally intensive inversion processes unsuitable for resource-constrained edge devices. We propose a framework for identity-agnostic pathology preservation that serves as a client-side privacy-preserving utility. By leveraging inversion-free Rectified Flow Transformers (FlowEdit), the system performs high-fidelity identity transformation in near real-time (less than 20s), facilitating local deployment on clinical nodes. We introduce a "Segment-by-Synthesis" mechanism that generates counterfactual healthy and pathological twin pairs locally. This enables the extraction of differential erythema masks that are decoupled from biometric markers and semantic artifacts (e.g. jewelry). Pilot validation on high-resolution clinical samples demonstrates an Intersection over Union (IoU) stability greater than 0.67 across synthetic identities. By generating privacy-compliant synthetic surrogates at the edge, this framework mitigates the risk of gradient leakage at the source, providing a secure pathway for high-precision skin image analysis in federated environments.
FAST: A Dual-tier Few-Shot Learning Paradigm for Whole Slide Image Classification
Sep 29, 2024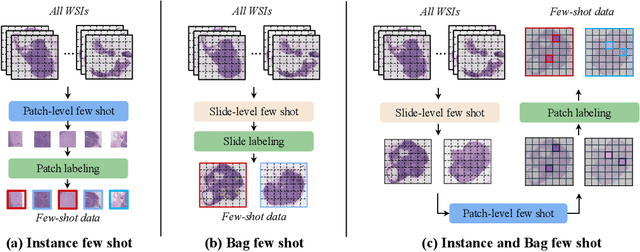
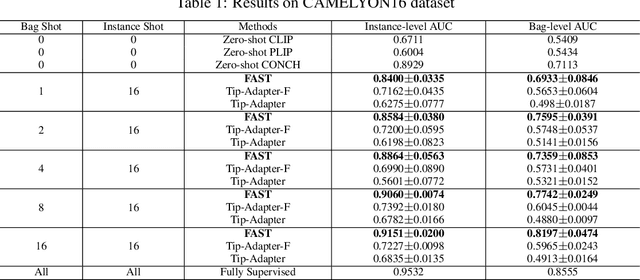
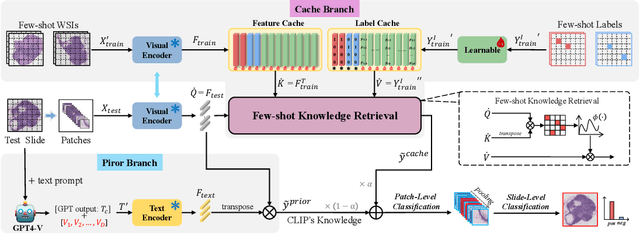
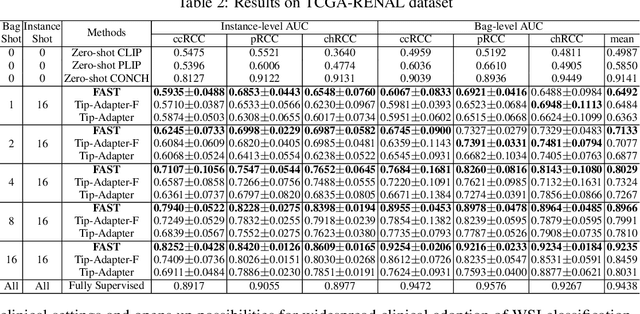
The expensive fine-grained annotation and data scarcity have become the primary obstacles for the widespread adoption of deep learning-based Whole Slide Images (WSI) classification algorithms in clinical practice. Unlike few-shot learning methods in natural images that can leverage the labels of each image, existing few-shot WSI classification methods only utilize a small number of fine-grained labels or weakly supervised slide labels for training in order to avoid expensive fine-grained annotation. They lack sufficient mining of available WSIs, severely limiting WSI classification performance. To address the above issues, we propose a novel and efficient dual-tier few-shot learning paradigm for WSI classification, named FAST. FAST consists of a dual-level annotation strategy and a dual-branch classification framework. Firstly, to avoid expensive fine-grained annotation, we collect a very small number of WSIs at the slide level, and annotate an extremely small number of patches. Then, to fully mining the available WSIs, we use all the patches and available patch labels to build a cache branch, which utilizes the labeled patches to learn the labels of unlabeled patches and through knowledge retrieval for patch classification. In addition to the cache branch, we also construct a prior branch that includes learnable prompt vectors, using the text encoder of visual-language models for patch classification. Finally, we integrate the results from both branches to achieve WSI classification. Extensive experiments on binary and multi-class datasets demonstrate that our proposed method significantly surpasses existing few-shot classification methods and approaches the accuracy of fully supervised methods with only 0.22$\%$ annotation costs. All codes and models will be publicly available on https://github.com/fukexue/FAST.
Setting a Baseline for long-shot real-time Player and Ball detection in Soccer Videos
Nov 12, 2023



Players and ball detection are among the first required steps on a football analytics platform. Until recently, the existing open datasets on which the evaluations of most models were based, were not sufficient. In this work, we point out their weaknesses, and with the advent of the SoccerNet v3, we propose and deliver to the community an edited part of its dataset, in YOLO normalized annotation format for training and evaluation. The code of the methods and metrics are provided so that they can be used as a benchmark in future comparisons. The recent YOLO8n model proves better than FootAndBall in long-shot real-time detection of the ball and players on football fields.
$H$-RANSAC, an algorithmic variant for Homography image transform from featureless point sets: application to video-based football analytics
Oct 07, 2023Estimating homography matrix between two images has various applications like image stitching or image mosaicing and spatial information retrieval from multiple camera views, but has been proved to be a complicated problem, especially in cases of radically different camera poses and zoom factors. Many relevant approaches have been proposed, utilizing direct feature based, or deep learning methodologies. In this paper, we propose a generalized RANSAC algorithm, H-RANSAC, to retrieve homography image transformations from sets of points without descriptive local feature vectors and point pairing. We allow the points to be optionally labelled in two classes. We propose a robust criterion that rejects implausible point selection before each iteration of RANSAC, based on the type of the quadrilaterals formed by random point pair selection (convex or concave and (non)-self-intersecting). A similar post-hoc criterion rejects implausible homography transformations is included at the end of each iteration. The expected maximum iterations of $H$-RANSAC are derived for different probabilities of success, according to the number of points per image and per class, and the percentage of outliers. The proposed methodology is tested on a large dataset of images acquired by 12 cameras during real football matches, where radically different views at each timestamp are to be matched. Comparisons with state-of-the-art implementations of RANSAC combined with classic and deep learning image salient point detection indicates the superiority of the proposed $H$-RANSAC, in terms of average reprojection error and number of successfully processed pairs of frames, rendering it the method of choice in cases of image homography alignment with few tens of points, while local features are not available, or not descriptive enough. The implementation of $H$-RANSAC is available in https://github.com/gnousias/H-RANSAC