 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion Matters: Efficient and Reliable Region-Aware Visual Place Recognition
Apr 24, 2026Visual Place Recognition (VPR) determines a query image's geographic location by matching it against geotagged databases. However, existing methods struggle with perceptual aliasing caused by irrelevant regions and inefficient re-ranking due to rigid candidate scheduling. To address these issues, we introduce FoL++, a method combining robust discriminative region modeling with adaptive re-ranking. Specifically, we propose a Reliability Estimation Branch to generate spatial reliability maps that explicitly model occlusion resistance. This representation is further optimized by two spatial alignment losses (SAL and SCEL) to effectively align features and highlight salient regions. For weakly supervised learning without manual annotations, a pseudo-correspondence strategy generates dense local feature supervision directly from aggregation clusters. Our Adaptive Candidate Scheduler dynamically resizes candidate pools based on global similarity. By weighting local matches by reliability and adaptively fusing global and local evidence, FoL++ surpasses traditional independent matching systems. Extensive experiments across seven benchmarks demonstrate that FoL++ achieves state-of-the-art performance with a lightweight memory footprint, improving inference speed by 40% over FoL. Code and models will be released (and merged with FoL) at https://github.com/chenshunpeng/FoL.
Adaptive Visual Autoregressive Acceleration via Dual-Linkage Entropy Analysis
Feb 01, 2026Visual AutoRegressive modeling (VAR) suffers from substantial computational cost due to the massive token count involved. Failing to account for the continuous evolution of modeling dynamics, existing VAR token reduction methods face three key limitations: heuristic stage partition, non-adaptive schedules, and limited acceleration scope, thereby leaving significant acceleration potential untapped. Since entropy variation intrinsically reflects the transition of predictive uncertainty, it offers a principled measure to capture modeling dynamics evolution. Therefore, we propose NOVA, a training-free token reduction acceleration framework for VAR models via entropy analysis. NOVA adaptively determines the acceleration activation scale during inference by online identifying the inflection point of scale entropy growth. Through scale-linkage and layer-linkage ratio adjustment, NOVA dynamically computes distinct token reduction ratios for each scale and layer, pruning low-entropy tokens while reusing the cache derived from the residuals at the prior scale to accelerate inference and maintain generation quality. Extensive experiments and analyses validate NOVA as a simple yet effective training-free acceleration framework.
Vision Also You Need: Navigating Out-of-Distribution Detection with Multimodal Large Language Model
Jan 20, 2026Out-of-Distribution (OOD) detection is a critical task that has garnered significant attention. The emergence of CLIP has spurred extensive research into zero-shot OOD detection, often employing a training-free approach. Current methods leverage expert knowledge from large language models (LLMs) to identify potential outliers. However, these approaches tend to over-rely on knowledge in the text space, neglecting the inherent challenges involved in detecting out-of-distribution samples in the image space. In this paper, we propose a novel pipeline, MM-OOD, which leverages the multimodal reasoning capabilities of MLLMs and their ability to conduct multi-round conversations for enhanced outlier detection. Our method is designed to improve performance in both near OOD and far OOD tasks. Specifically, (1) for near OOD tasks, we directly feed ID images and corresponding text prompts into MLLMs to identify potential outliers; and (2) for far OOD tasks, we introduce the sketch-generate-elaborate framework: first, we sketch outlier exposure using text prompts, then generate corresponding visual OOD samples, and finally elaborate by using multimodal prompts. Experiments demonstrate that our method achieves significant improvements on widely used multimodal datasets such as Food-101, while also validating its scalability on ImageNet-1K.
CurriFlow: Curriculum-Guided Depth Fusion with Optical Flow-Based Temporal Alignment for 3D Semantic Scene Completion
Oct 14, 2025Semantic Scene Completion (SSC) aims to infer complete 3D geometry and semantics from monocular images, serving as a crucial capability for camera-based perception in autonomous driving. However, existing SSC methods relying on temporal stacking or depth projection often lack explicit motion reasoning and struggle with occlusions and noisy depth supervision. We propose CurriFlow, a novel semantic occupancy prediction framework that integrates optical flow-based temporal alignment with curriculum-guided depth fusion. CurriFlow employs a multi-level fusion strategy to align segmentation, visual, and depth features across frames using pre-trained optical flow, thereby improving temporal consistency and dynamic object understanding. To enhance geometric robustness, a curriculum learning mechanism progressively transitions from sparse yet accurate LiDAR depth to dense but noisy stereo depth during training, ensuring stable optimization and seamless adaptation to real-world deployment. Furthermore, semantic priors from the Segment Anything Model (SAM) provide category-agnostic supervision, strengthening voxel-level semantic learning and spatial consistency. Experiments on the SemanticKITTI benchmark demonstrate that CurriFlow achieves state-of-the-art performance with a mean IoU of 16.9, validating the effectiveness of our motion-guided and curriculum-aware design for camera-based 3D semantic scene completion.
A Constructed Response: Designing and Choreographing Robot Arm Movements in Collaborative Dance Improvisation
May 29, 2025Dancers often prototype movements themselves or with each other during improvisation and choreography. How are these interactions altered when physically manipulable technologies are introduced into the creative process? To understand how dancers design and improvise movements while working with instruments capable of non-humanoid movements, we engaged dancers in workshops to co-create movements with a robot arm in one-human-to-one-robot and three-human-to-one-robot settings. We found that dancers produced more fluid movements in one-to-one scenarios, experiencing a stronger sense of connection and presence with the robot as a co-dancer. In three-to-one scenarios, the dancers divided their attention between the human dancers and the robot, resulting in increased perceived use of space and more stop-and-go movements, perceiving the robot as part of the stage background. This work highlights how technologies can drive creativity in movement artists adapting to new ways of working with physical instruments, contributing design insights supporting artistic collaborations with non-humanoid agents.
LEAM: A Prompt-only Large Language Model-enabled Antenna Modeling Method
Apr 25, 2025Antenna modeling is a time-consuming and complex process, decreasing the speed of antenna analysis and design. In this paper, a large language model (LLM)- enabled antenna modeling method, called LEAM, is presented to address this challenge. LEAM enables automatic antenna model generation based on language descriptions via prompt input, images, descriptions from academic papers, patents, and technical reports (either one or multiple). The effectiveness of LEAM is demonstrated by three examples: a Vivaldi antenna generated from a complete user description, a slotted patch antenna generated from an incomplete user description and the operating frequency, and a monopole slotted antenna generated from images and descriptions scanned from the literature. For all the examples, correct antenna models are generated in a few minutes. The code can be accessed via https://github.com/TaoWu974/LEAM.
Focus on Local: Finding Reliable Discriminative Regions for Visual Place Recognition
Apr 14, 2025Visual Place Recognition (VPR) is aimed at predicting the location of a query image by referencing a database of geotagged images. For VPR task, often fewer discriminative local regions in an image produce important effects while mundane background regions do not contribute or even cause perceptual aliasing because of easy overlap. However, existing methods lack precisely modeling and full exploitation of these discriminative regions. In this paper, we propose the Focus on Local (FoL) approach to stimulate the performance of image retrieval and re-ranking in VPR simultaneously by mining and exploiting reliable discriminative local regions in images and introducing pseudo-correlation supervision. First, we design two losses, Extraction-Aggregation Spatial Alignment Loss (SAL) and Foreground-Background Contrast Enhancement Loss (CEL), to explicitly model reliable discriminative local regions and use them to guide the generation of global representations and efficient re-ranking. Second, we introduce a weakly-supervised local feature training strategy based on pseudo-correspondences obtained from aggregating global features to alleviate the lack of local correspondences ground truth for the VPR task. Third, we suggest an efficient re-ranking pipeline that is efficiently and precisely based on discriminative region guidance. Finally, experimental results show that our FoL achieves the state-of-the-art on multiple VPR benchmarks in both image retrieval and re-ranking stages and also significantly outperforms existing two-stage VPR methods in terms of computational efficiency. Code and models are available at https://github.com/chenshunpeng/FoL
Exploring CLIP's Dense Knowledge for Weakly Supervised Semantic Segmentation
Mar 26, 2025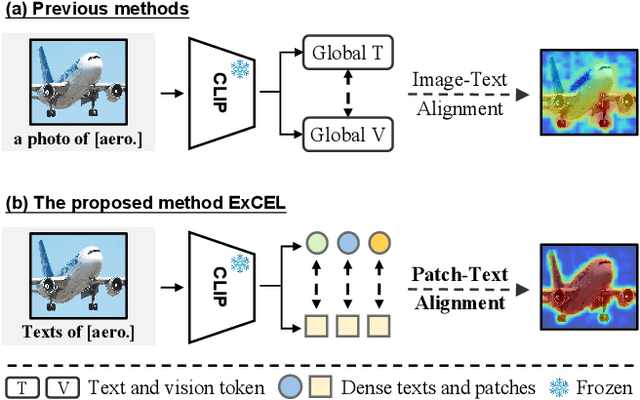


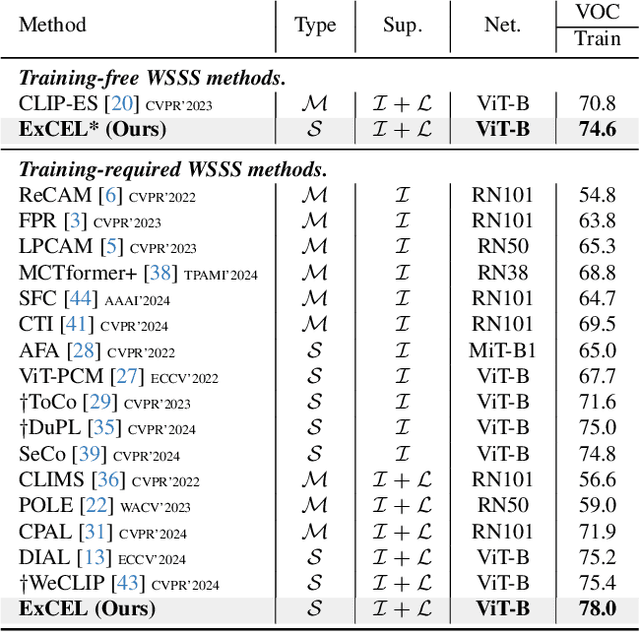
Weakly Supervised Semantic Segmentation (WSSS) with image-level labels aims to achieve pixel-level predictions using Class Activation Maps (CAMs). Recently, Contrastive Language-Image Pre-training (CLIP) has been introduced in WSSS. However, recent methods primarily focus on image-text alignment for CAM generation, while CLIP's potential in patch-text alignment remains unexplored. In this work, we propose ExCEL to explore CLIP's dense knowledge via a novel patch-text alignment paradigm for WSSS. Specifically, we propose Text Semantic Enrichment (TSE) and Visual Calibration (VC) modules to improve the dense alignment across both text and vision modalities. To make text embeddings semantically informative, our TSE module applies Large Language Models (LLMs) to build a dataset-wide knowledge base and enriches the text representations with an implicit attribute-hunting process. To mine fine-grained knowledge from visual features, our VC module first proposes Static Visual Calibration (SVC) to propagate fine-grained knowledge in a non-parametric manner. Then Learnable Visual Calibration (LVC) is further proposed to dynamically shift the frozen features towards distributions with diverse semantics. With these enhancements, ExCEL not only retains CLIP's training-free advantages but also significantly outperforms other state-of-the-art methods with much less training cost on PASCAL VOC and MS COCO.
MoRe: Class Patch Attention Needs Regularization for Weakly Supervised Semantic Segmentation
Dec 15, 2024



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels typically uses Class Activation Maps (CAM) to achieve dense predictions. Recently, Vision Transformer (ViT) has provided an alternative to generate localization maps from class-patch attention. However, due to insufficient constraints on modeling such attention, we observe that the Localization Attention Maps (LAM) often struggle with the artifact issue, i.e., patch regions with minimal semantic relevance are falsely activated by class tokens. In this work, we propose MoRe to address this issue and further explore the potential of LAM. Our findings suggest that imposing additional regularization on class-patch attention is necessary. To this end, we first view the attention as a novel directed graph and propose the Graph Category Representation module to implicitly regularize the interaction among class-patch entities. It ensures that class tokens dynamically condense the related patch information and suppress unrelated artifacts at a graph level. Second, motivated by the observation that CAM from classification weights maintains smooth localization of objects, we devise the Localization-informed Regularization module to explicitly regularize the class-patch attention. It directly mines the token relations from CAM and further supervises the consistency between class and patch tokens in a learnable manner. Extensive experiments are conducted on PASCAL VOC and MS COCO, validating that MoRe effectively addresses the artifact issue and achieves state-of-the-art performance, surpassing recent single-stage and even multi-stage methods. Code is available at https://github.com/zwyang6/MoRe.
FAST: A Dual-tier Few-Shot Learning Paradigm for Whole Slide Image Classification
Sep 29, 2024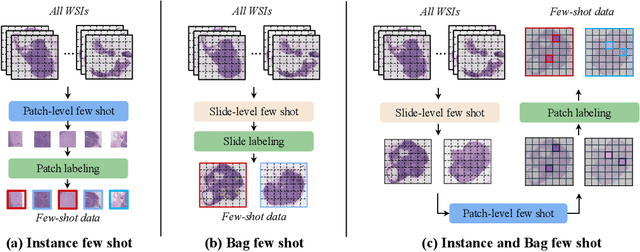
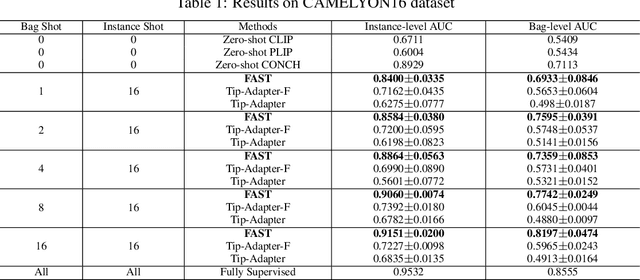
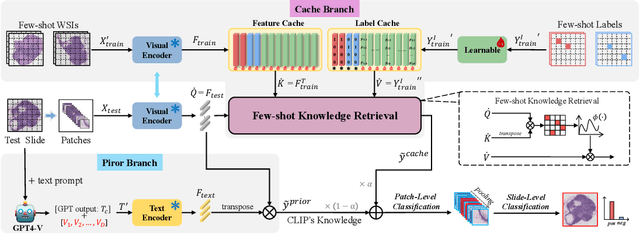
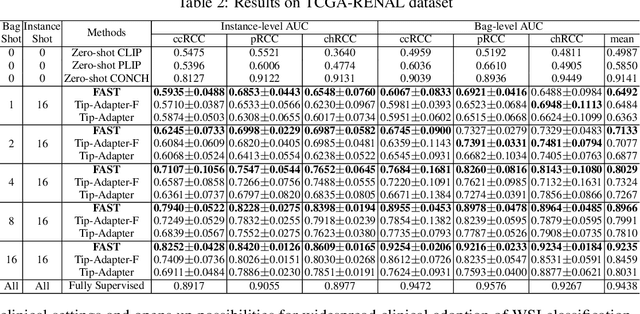
The expensive fine-grained annotation and data scarcity have become the primary obstacles for the widespread adoption of deep learning-based Whole Slide Images (WSI) classification algorithms in clinical practice. Unlike few-shot learning methods in natural images that can leverage the labels of each image, existing few-shot WSI classification methods only utilize a small number of fine-grained labels or weakly supervised slide labels for training in order to avoid expensive fine-grained annotation. They lack sufficient mining of available WSIs, severely limiting WSI classification performance. To address the above issues, we propose a novel and efficient dual-tier few-shot learning paradigm for WSI classification, named FAST. FAST consists of a dual-level annotation strategy and a dual-branch classification framework. Firstly, to avoid expensive fine-grained annotation, we collect a very small number of WSIs at the slide level, and annotate an extremely small number of patches. Then, to fully mining the available WSIs, we use all the patches and available patch labels to build a cache branch, which utilizes the labeled patches to learn the labels of unlabeled patches and through knowledge retrieval for patch classification. In addition to the cache branch, we also construct a prior branch that includes learnable prompt vectors, using the text encoder of visual-language models for patch classification. Finally, we integrate the results from both branches to achieve WSI classification. Extensive experiments on binary and multi-class datasets demonstrate that our proposed method significantly surpasses existing few-shot classification methods and approaches the accuracy of fully supervised methods with only 0.22$\%$ annotation costs. All codes and models will be publicly available on https://github.com/fukexue/FAST.