 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Lunch for Unified Multimodal Models: Enhancing Generation via Reflective Rectification with Inherent Understanding
Apr 15, 2026Unified Multimodal Models (UMMs) aim to integrate visual understanding and generation within a single structure. However, these models exhibit a notable capability mismatch, where their understanding capability significantly outperforms their generation. This mismatch indicates that the model's rich internal knowledge, while effective for understanding tasks, remains underactivated during generation. To address this, we draw inspiration from the human ``Thinking-While-Drawing'' paradigm, where humans continuously reflect to activate their knowledge and rectify intermediate results. In this paper, we propose UniRect-CoT, a training-free unified rectification chain-of-thought framework. Our approach unlocks the ``free lunch'' hidden in the UMM's powerful inherent understanding to continuously reflect, activating its internal knowledge and rectifying intermediate results during generation.We regard the diffusion denoising process in UMMs as an intrinsic visual reasoning process and align the intermediate results with the target instruction understood by the model, serving as a self-supervisory signal to rectify UMM generation.Extensive experiments demonstrate that UniRect-CoT can be easily integrated into existing UMMs, significantly enhancing generation quality across diverse complex tasks.
The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
System Design for Maintaining Internal State Consistency in Long-Horizon Robotic Tabletop Games
Mar 26, 2026Long-horizon tabletop games pose a distinct systems challenge for robotics: small perceptual or execution errors can invalidate accumulated task state, propagate across decision-making modules, and ultimately derail interaction. This paper studies how to maintain internal state consistency in turn-based, multi-human robotic tabletop games through deliberate system design rather than isolated component improvement. Using Mahjong as a representative long-horizon setting, we present an integrated architecture that explicitly maintains perceptual, execution, and interaction state, partitions high-level semantic reasoning from time-critical perception and control, and incorporates verified action primitives with tactile-triggered recovery to prevent premature state corruption. We further introduce interaction-level monitoring mechanisms to detect turn violations and hidden-information breaches that threaten execution assumptions. Beyond demonstrating complete-game operation, we provide an empirical characterization of failure modes, recovery effectiveness, cross-module error propagation, and hardware-algorithm trade-offs observed during deployment. Our results show that explicit partitioning, monitored state transitions, and recovery mechanisms are critical for sustaining executable consistency over extended play, whereas monolithic or unverified pipelines lead to measurable degradation in end-to-end reliability. The proposed system serves as an empirical platform for studying system-level design principles in long-horizon, turn-based interaction.
MVPBench: A Multi-Video Perception Evaluation Benchmark for Multi-Modal Video Understanding
Mar 24, 2026The rapid progress of Large Language Models (LLMs) has spurred growing interest in Multi-modal LLMs (MLLMs) and motivated the development of benchmarks to evaluate their perceptual and comprehension abilities. Existing benchmarks, however, are limited to static images or single videos, overlooking the complex interactions across multiple videos. To address this gap, we introduce the Multi-Video Perception Evaluation Benchmark (MVPBench), a new benchmark featuring 14 subtasks across diverse visual domains designed to evaluate models on extracting relevant information from video sequences to make informed decisions. MVPBench includes 5K question-answering tests involving 2.7K video clips sourced from existing datasets and manually annotated clips. Extensive evaluations reveal that current models struggle to process multi-video inputs effectively, underscoring substantial limitations in their multi-video comprehension. We anticipate MVPBench will drive advancements in multi-video perception.
SinGeo: Unlock Single Model's Potential for Robust Cross-View Geo-Localization
Mar 10, 2026Robust cross-view geo-localization (CVGL) remains challenging despite the surge in recent progress. Existing methods still rely on field-of-view (FoV)-specific training paradigms, where models are optimized under a fixed FoV but collapse when tested on unseen FoVs and unknown orientations. This limitation necessitates deploying multiple models to cover diverse variations. Although studies have explored dynamic FoV training by simply randomizing FoVs, they failed to achieve robustness across diverse conditions -- implicitly assuming all FoVs are equally difficult. To address this gap, we present SinGeo, a simple yet powerful framework that enables a single model to realize robust cross-view geo-localization without additional modules or explicit transformations. SinGeo employs a dual discriminative learning architecture that enhances intra-view discriminability within both ground and satellite branches, and is the first to introduce a curriculum learning strategy to achieve robust CVGL. Extensive evaluations on four benchmark datasets reveal that SinGeo sets state-of-the-art (SOTA) results under diverse conditions, and notably outperforms methods specifically trained for extreme FoVs. Beyond superior performance, SinGeo also exhibits cross-architecture transferability. Furthermore, we propose a consistency evaluation method to quantitatively assess model stability under varying views, providing an explainable perspective for understanding and advancing robustness in future CVGL research. Codes will be available upon acceptance.
GeodesicNVS: Probability Density Geodesic Flow Matching for Novel View Synthesis
Mar 01, 2026Recent advances in generative modeling have substantially enhanced novel view synthesis, yet maintaining consistency across viewpoints remains challenging. Diffusion-based models rely on stochastic noise-to-data transitions, which obscure deterministic structures and yield inconsistent view predictions. We propose a Data-to-Data Flow Matching framework that learns deterministic transformations directly between paired views, enhancing view-consistent synthesis through explicit data coupling. To further enhance geometric coherence, we introduce Probability Density Geodesic Flow Matching (PDG-FM), which constrains flow trajectories using geodesic interpolants derived from probability density metrics of pretrained diffusion models. Such alignment with high-density regions of the data manifold promotes more realistic interpolants between samples. Empirically, our method surpasses diffusion-based NVS baselines, demonstrating improved structural coherence and smoother transitions across views. These results highlight the advantages of incorporating data-dependent geometric regularization into deterministic flow matching for consistent novel view generation.
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
Spatially Generalizable Mobile Manipulation via Adaptive Experience Selection and Dynamic Imagination
Jan 21, 2026Mobile Manipulation (MM) involves long-horizon decision-making over multi-stage compositions of heterogeneous skills, such as navigation and picking up objects. Despite recent progress, existing MM methods still face two key limitations: (i) low sample efficiency, due to ineffective use of redundant data generated during long-term MM interactions; and (ii) poor spatial generalization, as policies trained on specific tasks struggle to transfer to new spatial layouts without additional training. In this paper, we address these challenges through Adaptive Experience Selection (AES) and model-based dynamic imagination. In particular, AES makes MM agents pay more attention to critical experience fragments in long trajectories that affect task success, improving skill chain learning and mitigating skill forgetting. Based on AES, a Recurrent State-Space Model (RSSM) is introduced for Model-Predictive Forward Planning (MPFP) by capturing the coupled dynamics between the mobile base and the manipulator and imagining the dynamics of future manipulations. RSSM-based MPFP can reinforce MM skill learning on the current task while enabling effective generalization to new spatial layouts. Comparative studies across different experimental configurations demonstrate that our method significantly outperforms existing MM policies. Real-world experiments further validate the feasibility and practicality of our method.
RoLID-11K: A Dashcam Dataset for Small-Object Roadside Litter Detection
Jan 01, 2026Roadside litter poses environmental, safety and economic challenges, yet current monitoring relies on labour-intensive surveys and public reporting, providing limited spatial coverage. Existing vision datasets for litter detection focus on street-level still images, aerial scenes or aquatic environments, and do not reflect the unique characteristics of dashcam footage, where litter appears extremely small, sparse and embedded in cluttered road-verge backgrounds. We introduce RoLID-11K, the first large-scale dataset for roadside litter detection from dashcams, comprising over 11k annotated images spanning diverse UK driving conditions and exhibiting pronounced long-tail and small-object distributions. We benchmark a broad spectrum of modern detectors, from accuracy-oriented transformer architectures to real-time YOLO models, and analyse their strengths and limitations on this challenging task. Our results show that while CO-DETR and related transformers achieve the best localisation accuracy, real-time models remain constrained by coarse feature hierarchies. RoLID-11K establishes a challenging benchmark for extreme small-object detection in dynamic driving scenes and aims to support the development of scalable, low-cost systems for roadside-litter monitoring. The dataset is available at https://github.com/xq141839/RoLID-11K.
Seeing the Whole Picture: Distribution-Guided Data-Free Distillation for Semantic Segmentation
Dec 15, 2025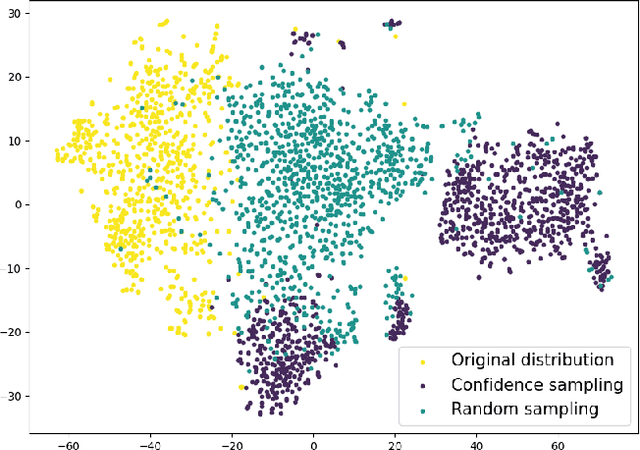
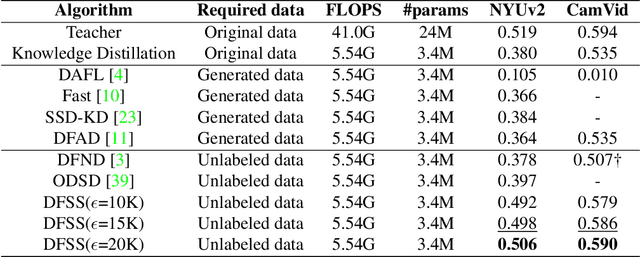

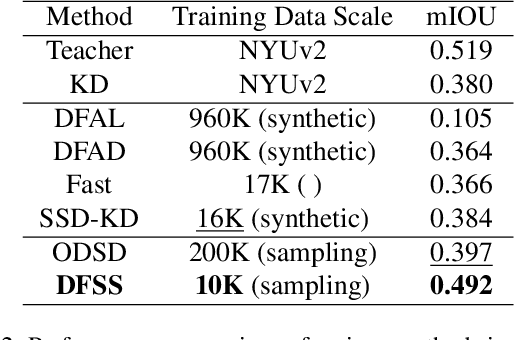
Semantic segmentation requires a holistic understanding of the physical world, as it assigns semantic labels to spatially continuous and structurally coherent objects rather than to isolated pixels. However, existing data-free knowledge distillation (DFKD) methods-primarily designed for classification-often disregard this continuity, resulting in significant performance degradation when applied directly to segmentation tasks. In this paper, we introduce DFSS, a novel data-free distillation framework tailored for semantic segmentation. Unlike prior approaches that treat pixels independently, DFSS respects the structural and contextual continuity of real-world scenes. Our key insight is to leverage Batch Normalization (BN) statistics from a teacher model to guide Approximate Distribution Sampling (ADS), enabling the selection of data that better reflects the original training distribution-without relying on potentially misleading teacher predictions. Additionally, we propose Weighted Distribution Progressive Distillation (WDPD), which dynamically prioritizes reliable samples that are more closely aligned with the original data distribution early in training and gradually incorporates more challenging cases, mirroring the natural progression of learning in human perception. Extensive experiments on standard benchmarks demonstrate that DFSS consistently outperforms existing data-free distillation methods for semantic segmentation, achieving state-of-the-art results with significantly reduced reliance on auxiliary data.