 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongVPO: From Anchored Cues to Self-Reasoning for Long-Form Video Preference Optimization
Feb 02, 2026We present LongVPO, a novel two-stage Direct Preference Optimization framework that enables short-context vision-language models to robustly understand ultra-long videos without any long-video annotations. In Stage 1, we synthesize preference triples by anchoring questions to individual short clips, interleaving them with distractors, and applying visual-similarity and question-specificity filtering to mitigate positional bias and ensure unambiguous supervision. We also approximate the reference model's scoring over long contexts by evaluating only the anchor clip, reducing computational overhead. In Stage 2, we employ a recursive captioning pipeline on long videos to generate scene-level metadata, then use a large language model to craft multi-segment reasoning queries and dispreferred responses, aligning the model's preferences through multi-segment reasoning tasks. With only 16K synthetic examples and no costly human labels, LongVPO outperforms the state-of-the-art open-source models on multiple long-video benchmarks, while maintaining strong short-video performance (e.g., on MVBench), offering a scalable paradigm for efficient long-form video understanding.
N3D-VLM: Native 3D Grounding Enables Accurate Spatial Reasoning in Vision-Language Models
Dec 18, 2025While current multimodal models can answer questions based on 2D images, they lack intrinsic 3D object perception, limiting their ability to comprehend spatial relationships and depth cues in 3D scenes. In this work, we propose N3D-VLM, a novel unified framework that seamlessly integrates native 3D object perception with 3D-aware visual reasoning, enabling both precise 3D grounding and interpretable spatial understanding. Unlike conventional end-to-end models that directly predict answers from RGB/RGB-D inputs, our approach equips the model with native 3D object perception capabilities, enabling it to directly localize objects in 3D space based on textual descriptions. Building upon accurate 3D object localization, the model further performs explicit reasoning in 3D, achieving more interpretable and structured spatial understanding. To support robust training for these capabilities, we develop a scalable data construction pipeline that leverages depth estimation to lift large-scale 2D annotations into 3D space, significantly increasing the diversity and coverage for 3D object grounding data, yielding over six times larger than the largest existing single-image 3D detection dataset. Moreover, the pipeline generates spatial question-answering datasets that target chain-of-thought (CoT) reasoning in 3D, facilitating joint training for both 3D object localization and 3D spatial reasoning. Experimental results demonstrate that our unified framework not only achieves state-of-the-art performance on 3D grounding tasks, but also consistently surpasses existing methods in 3D spatial reasoning in vision-language model.
Online Video Understanding: A Comprehensive Benchmark and Memory-Augmented Method
Dec 31, 2024



Multimodal Large Language Models (MLLMs) have shown significant progress in offline video understanding. However, applying these models to real-world scenarios, such as autonomous driving and human-computer interaction, presents unique challenges due to the need for real-time processing of continuous online video streams. To this end, this paper presents systematic efforts from three perspectives: evaluation benchmark, model architecture, and training strategy. First, we introduce OVBench, a comprehensive question-answering benchmark specifically designed to evaluate models' ability to perceive, memorize, and reason within online video contexts. It features six core task types across three temporal contexts-past, present, and future-forming 16 subtasks from diverse datasets. Second, we propose a new Pyramid Memory Bank (PMB) that effectively retains key spatiotemporal information in video streams. Third, we proposed an offline-to-online learning paradigm, designing an interleaved dialogue format for online video data and constructing an instruction-tuning dataset tailored for online video training. This framework led to the development of VideoChat-Online, a robust and efficient model for online video understanding. Despite the lower computational cost and higher efficiency, VideoChat-Online outperforms existing state-of-the-art offline and online models across popular offline video benchmarks and OVBench, demonstrating the effectiveness of our model architecture and training strategy.
p-MoD: Building Mixture-of-Depths MLLMs via Progressive Ratio Decay
Dec 05, 2024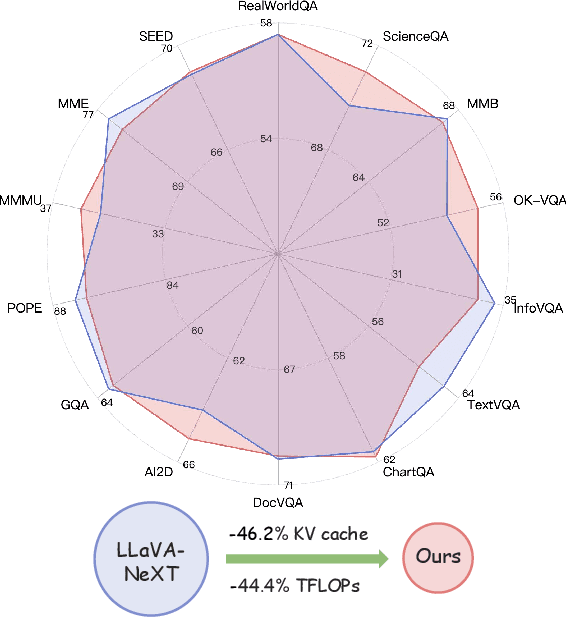



Despite the remarkable performance of multimodal large language models (MLLMs) across diverse tasks, the substantial training and inference costs impede their advancement. The majority of computation stems from the overwhelming volume of vision tokens processed by the transformer decoder. In this paper, we propose to build efficient MLLMs by leveraging the Mixture-of-Depths (MoD) mechanism, where each transformer decoder layer selects essential vision tokens to process while skipping redundant ones. However, integrating MoD into MLLMs is non-trivial. To address the challenges of training and inference stability as well as limited training data, we adapt the MoD module with two novel designs: tanh-gated weight normalization (TanhNorm) and symmetric token reweighting (STRing). Moreover, we observe that vision tokens exhibit higher redundancy in deeper layer and thus design a progressive ratio decay (PRD) strategy, which gradually reduces the token retention ratio layer by layer, employing a shifted cosine schedule. This crucial design fully unleashes the potential of MoD, significantly boosting the efficiency and performance of our models. To validate the effectiveness of our approach, we conduct extensive experiments with two baseline models across 14 benchmarks. Our model, p-MoD, matches or even surpasses the performance of the baseline models, with only 55.6% TFLOPs and 53.8% KV cache storage during inference, and 77.7% GPU hours during training.
VideoEval: Comprehensive Benchmark Suite for Low-Cost Evaluation of Video Foundation Model
Jul 09, 2024With the growth of high-quality data and advancement in visual pre-training paradigms, Video Foundation Models (VFMs) have made significant progress recently, demonstrating their remarkable performance on traditional video understanding benchmarks. However, the existing benchmarks (e.g. Kinetics) and their evaluation protocols are often limited by relatively poor diversity, high evaluation costs, and saturated performance metrics. In this paper, we build a comprehensive benchmark suite to address these issues, namely VideoEval. Specifically, we establish the Video Task Adaption Benchmark (VidTAB) and the Video Embedding Benchmark (VidEB) from two perspectives: evaluating the task adaptability of VFMs under few-shot conditions and assessing their representation power by directly applying to downstream tasks. With VideoEval, we conduct a large-scale study on 20 popular open-source vision foundation models. Our study reveals some insightful findings on VFMs: 1) overall, current VFMs exhibit weak generalization across diverse tasks, 2) increasing video data, whether labeled or weakly-labeled video-text pairs, does not necessarily improve task performance, 3) the effectiveness of some pre-training paradigms may not be fully validated in previous benchmarks, and 4) combining different pre-training paradigms can help improve the generalization capabilities. We believe this study serves as an important complement to the current evaluation for VFMs and offers valuable insights for the future research.
Data-efficient Event Camera Pre-training via Disentangled Masked Modeling
Mar 01, 2024In this paper, we present a new data-efficient voxel-based self-supervised learning method for event cameras. Our pre-training overcomes the limitations of previous methods, which either sacrifice temporal information by converting event sequences into 2D images for utilizing pre-trained image models or directly employ paired image data for knowledge distillation to enhance the learning of event streams. In order to make our pre-training data-efficient, we first design a semantic-uniform masking method to address the learning imbalance caused by the varying reconstruction difficulties of different regions in non-uniform data when using random masking. In addition, we ease the traditional hybrid masked modeling process by explicitly decomposing it into two branches, namely local spatio-temporal reconstruction and global semantic reconstruction to encourage the encoder to capture local correlations and global semantics, respectively. This decomposition allows our selfsupervised learning method to converge faster with minimal pre-training data. Compared to previous approaches, our self-supervised learning method does not rely on paired RGB images, yet enables simultaneous exploration of spatial and temporal cues in multiple scales. It exhibits excellent generalization performance and demonstrates significant improvements across various tasks with fewer parameters and lower computational costs.