 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMonarch: Efficient Video Diffusion Transformers with Structured Attention
Jan 29, 2026The quadratic complexity of the attention mechanism severely limits the context scalability of Video Diffusion Transformers (DiTs). We find that the highly sparse spatio-temporal attention patterns exhibited in Video DiTs can be naturally represented by the Monarch matrix. It is a class of structured matrices with flexible sparsity, enabling sub-quadratic attention via an alternating minimization algorithm. Accordingly, we propose VMonarch, a novel attention mechanism for Video DiTs that enables efficient computation over the dynamic sparse patterns with structured Monarch matrices. First, we adapt spatio-temporal Monarch factorization to explicitly capture the intra-frame and inter-frame correlations of the video data. Second, we introduce a recomputation strategy to mitigate artifacts arising from instabilities during alternating minimization of Monarch matrices. Third, we propose a novel online entropy algorithm fused into FlashAttention, enabling fast Monarch matrix updates for long sequences. Extensive experiments demonstrate that VMonarch achieves comparable or superior generation quality to full attention on VBench after minimal tuning. It overcomes the attention bottleneck in Video DiTs, reduces attention FLOPs by a factor of 17.5, and achieves a speedup of over 5x in attention computation for long videos, surpassing state-of-the-art sparse attention methods at 90% sparsity.
CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation
Jan 15, 2026Recent video generation models have revealed the emergence of Chain-of-Frame (CoF) reasoning, enabling frame-by-frame visual inference. With this capability, video models have been successfully applied to various visual tasks (e.g., maze solving, visual puzzles). However, their potential to enhance text-to-image (T2I) generation remains largely unexplored due to the absence of a clearly defined visual reasoning starting point and interpretable intermediate states in the T2I generation process. To bridge this gap, we propose CoF-T2I, a model that integrates CoF reasoning into T2I generation via progressive visual refinement, where intermediate frames act as explicit reasoning steps and the final frame is taken as output. To establish such an explicit generation process, we curate CoF-Evol-Instruct, a dataset of CoF trajectories that model the generation process from semantics to aesthetics. To further improve quality and avoid motion artifacts, we enable independent encoding operation for each frame. Experiments show that CoF-T2I significantly outperforms the base video model and achieves competitive performance on challenging benchmarks, reaching 0.86 on GenEval and 7.468 on Imagine-Bench. These results indicate the substantial promise of video models for advancing high-quality text-to-image generation.
SAM 2++: Tracking Anything at Any Granularity
Oct 22, 2025Video tracking aims at finding the specific target in subsequent frames given its initial state. Due to the varying granularity of target states across different tasks, most existing trackers are tailored to a single task and heavily rely on custom-designed modules within the individual task, which limits their generalization and leads to redundancy in both model design and parameters. To unify video tracking tasks, we present SAM 2++, a unified model towards tracking at any granularity, including masks, boxes, and points. First, to extend target granularity, we design task-specific prompts to encode various task inputs into general prompt embeddings, and a unified decoder to unify diverse task results into a unified form pre-output. Next, to satisfy memory matching, the core operation of tracking, we introduce a task-adaptive memory mechanism that unifies memory across different granularities. Finally, we introduce a customized data engine to support tracking training at any granularity, producing a large and diverse video tracking dataset with rich annotations at three granularities, termed Tracking-Any-Granularity, which represents a comprehensive resource for training and benchmarking on unified tracking. Comprehensive experiments on multiple benchmarks confirm that SAM 2++ sets a new state of the art across diverse tracking tasks at different granularities, establishing a unified and robust tracking framework.
LLM-Explorer: Towards Efficient and Affordable LLM-based Exploration for Mobile Apps
May 15, 2025Large language models (LLMs) have opened new opportunities for automated mobile app exploration, an important and challenging problem that used to suffer from the difficulty of generating meaningful UI interactions. However, existing LLM-based exploration approaches rely heavily on LLMs to generate actions in almost every step, leading to a huge cost of token fees and computational resources. We argue that such extensive usage of LLMs is neither necessary nor effective, since many actions during exploration do not require, or may even be biased by the abilities of LLMs. Further, based on the insight that a precise and compact knowledge plays the central role for effective exploration, we introduce LLM-Explorer, a new exploration agent designed for efficiency and affordability. LLM-Explorer uses LLMs primarily for maintaining the knowledge instead of generating actions, and knowledge is used to guide action generation in a LLM-less manner. Based on a comparison with 5 strong baselines on 20 typical apps, LLM-Explorer was able to achieve the fastest and highest coverage among all automated app explorers, with over 148x lower cost than the state-of-the-art LLM-based approach.
ChestX-Reasoner: Advancing Radiology Foundation Models with Reasoning through Step-by-Step Verification
Apr 29, 2025Recent advances in reasoning-enhanced large language models (LLMs) and multimodal LLMs (MLLMs) have significantly improved performance in complex tasks, yet medical AI models often overlook the structured reasoning processes inherent in clinical practice. In this work, we present ChestX-Reasoner, a radiology diagnosis MLLM designed to leverage process supervision mined directly from clinical reports, reflecting the step-by-step reasoning followed by radiologists. We construct a large dataset by extracting and refining reasoning chains from routine radiology reports. Our two-stage training framework combines supervised fine-tuning and reinforcement learning guided by process rewards to better align model reasoning with clinical standards. We introduce RadRBench-CXR, a comprehensive benchmark featuring 59K visual question answering samples with 301K clinically validated reasoning steps, and propose RadRScore, a metric evaluating reasoning factuality, completeness, and effectiveness. ChestX-Reasoner outperforms existing medical and general-domain MLLMs in both diagnostic accuracy and reasoning ability, achieving 16%, 5.9%, and 18% improvements in reasoning ability compared to the best medical MLLM, the best general MLLM, and its base model, respectively, as well as 3.3%, 24%, and 27% improvements in outcome accuracy. All resources are open-sourced to facilitate further research in medical reasoning MLLMs.
VideoMAP: Toward Scalable Mamba-based Video Autoregressive Pretraining
Mar 16, 2025Recent Mamba-based architectures for video understanding demonstrate promising computational efficiency and competitive performance, yet struggle with overfitting issues that hinder their scalability. To overcome this challenge, we introduce VideoMAP, a Hybrid Mamba-Transformer framework featuring a novel pre-training approach. VideoMAP uses a 4:1 Mamba-to-Transformer ratio, effectively balancing computational cost and model capacity. This architecture, combined with our proposed frame-wise masked autoregressive pre-training strategy, delivers significant performance gains when scaling to larger models. Additionally, VideoMAP exhibits impressive sample efficiency, significantly outperforming existing methods with less training data. Experiments show that VideoMAP outperforms existing models across various datasets, including Kinetics-400, Something-Something V2, Breakfast, and COIN. Furthermore, we demonstrate the potential of VideoMAP as a visual encoder for multimodal large language models, highlighting its ability to reduce memory usage and enable the processing of longer video sequences. The code is open-source at https://github.com/yunzeliu/MAP
Online Video Understanding: A Comprehensive Benchmark and Memory-Augmented Method
Dec 31, 2024



Multimodal Large Language Models (MLLMs) have shown significant progress in offline video understanding. However, applying these models to real-world scenarios, such as autonomous driving and human-computer interaction, presents unique challenges due to the need for real-time processing of continuous online video streams. To this end, this paper presents systematic efforts from three perspectives: evaluation benchmark, model architecture, and training strategy. First, we introduce OVBench, a comprehensive question-answering benchmark specifically designed to evaluate models' ability to perceive, memorize, and reason within online video contexts. It features six core task types across three temporal contexts-past, present, and future-forming 16 subtasks from diverse datasets. Second, we propose a new Pyramid Memory Bank (PMB) that effectively retains key spatiotemporal information in video streams. Third, we proposed an offline-to-online learning paradigm, designing an interleaved dialogue format for online video data and constructing an instruction-tuning dataset tailored for online video training. This framework led to the development of VideoChat-Online, a robust and efficient model for online video understanding. Despite the lower computational cost and higher efficiency, VideoChat-Online outperforms existing state-of-the-art offline and online models across popular offline video benchmarks and OVBench, demonstrating the effectiveness of our model architecture and training strategy.
Multi-Metric AutoRec for High Dimensional and Sparse User Behavior Data Prediction
Dec 20, 2022
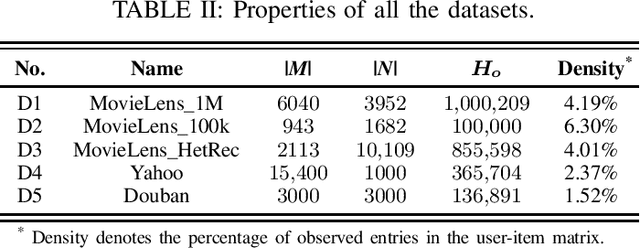

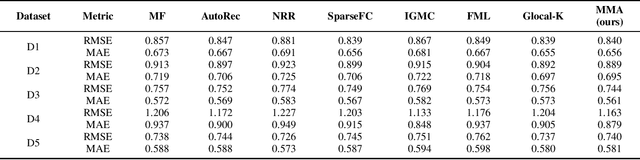
User behavior data produced during interaction with massive items in the significant data era are generally heterogeneous and sparse, leaving the recommender system (RS) a large diversity of underlying patterns to excavate. Deep neural network-based models have reached the state-of-the-art benchmark of the RS owing to their fitting capabilities. However, prior works mainly focus on designing an intricate architecture with fixed loss function and regulation. These single-metric models provide limited performance when facing heterogeneous and sparse user behavior data. Motivated by this finding, we propose a multi-metric AutoRec (MMA) based on the representative AutoRec. The idea of the proposed MMA is mainly two-fold: 1) apply different $L_p$-norm on loss function and regularization to form different variant models in different metric spaces, and 2) aggregate these variant models. Thus, the proposed MMA enjoys the multi-metric orientation from a set of dispersed metric spaces, achieving a comprehensive representation of user data. Theoretical studies proved that the proposed MMA could attain performance improvement. The extensive experiment on five real-world datasets proves that MMA can outperform seven other state-of-the-art models in predicting unobserved user behavior data.