 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Snapshot is All You Need: A Generalized Method for mmWave Signal Generation
Mar 27, 2025Wireless sensing systems, particularly those using mmWave technology, offer distinct advantages over traditional vision-based approaches, such as enhanced privacy and effectiveness in poor lighting conditions. These systems, leveraging FMCW signals, have shown success in human-centric applications like localization, gesture recognition, and so on. However, comprehensive mmWave datasets for diverse applications are scarce, often constrained by pre-processed signatures (e.g., point clouds or RA heatmaps) and inconsistent annotation formats. To overcome these limitations, we propose mmGen, a novel and generalized framework tailored for full-scene mmWave signal generation. By constructing physical signal transmission models, mmGen synthesizes human-reflected and environment-reflected mmWave signals from the constructed 3D meshes. Additionally, we incorporate methods to account for material properties, antenna gains, and multipath reflections, enhancing the realism of the synthesized signals. We conduct extensive experiments using a prototype system with commercial mmWave devices and Kinect sensors. The results show that the average similarity of Range-Angle and micro-Doppler signatures between the synthesized and real-captured signals across three different environments exceeds 0.91 and 0.89, respectively, demonstrating the effectiveness and practical applicability of mmGen.
Learning Decisions Offline from Censored Observations with ε-insensitive Operational Costs
Aug 14, 2024



Many important managerial decisions are made based on censored observations. Making decisions without adequately handling the censoring leads to inferior outcomes. We investigate the data-driven decision-making problem with an offline dataset containing the feature data and the censored historical data of the variable of interest without the censoring indicators. Without assuming the underlying distribution, we design and leverage {\epsilon}-insensitive operational costs to deal with the unobserved censoring in an offline data-driven fashion. We demonstrate the customization of the {\epsilon}-insensitive operational costs for a newsvendor problem and use such costs to train two representative ML models, including linear regression (LR) models and neural networks (NNs). We derive tight generalization bounds for the custom LR model without regularization (LR-{\epsilon}NVC) and with regularization (LR-{\epsilon}NVC-R), and a high-probability generalization bound for the custom NN (NN-{\epsilon}NVC) trained by stochastic gradient descent. The theoretical results reveal the stability and learnability of LR-{\epsilon}NVC, LR-{\epsilon}NVC-R and NN-{\epsilon}NVC. We conduct extensive numerical experiments to compare LR-{\epsilon}NVC-R and NN-{\epsilon}NVC with two existing approaches, estimate-as-solution (EAS) and integrated estimation and optimization (IEO). The results show that LR-{\epsilon}NVC-R and NN-{\epsilon}NVC outperform both EAS and IEO, with maximum cost savings up to 14.40% and 12.21% compared to the lowest cost generated by the two existing approaches. In addition, LR-{\epsilon}NVC-R's and NN-{\epsilon}NVC's order quantities are statistically significantly closer to the optimal solutions should the underlying distribution be known.
Multi-Metric AutoRec for High Dimensional and Sparse User Behavior Data Prediction
Dec 20, 2022
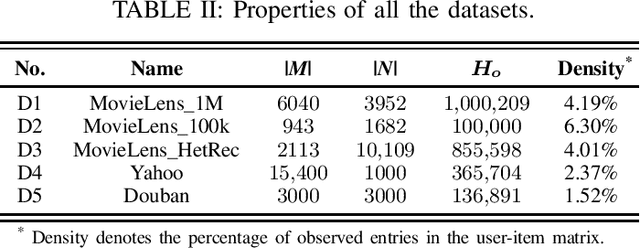

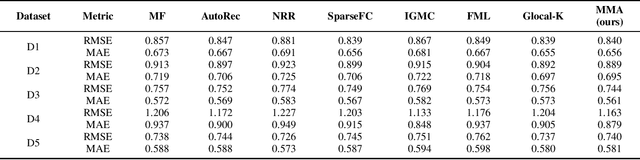
User behavior data produced during interaction with massive items in the significant data era are generally heterogeneous and sparse, leaving the recommender system (RS) a large diversity of underlying patterns to excavate. Deep neural network-based models have reached the state-of-the-art benchmark of the RS owing to their fitting capabilities. However, prior works mainly focus on designing an intricate architecture with fixed loss function and regulation. These single-metric models provide limited performance when facing heterogeneous and sparse user behavior data. Motivated by this finding, we propose a multi-metric AutoRec (MMA) based on the representative AutoRec. The idea of the proposed MMA is mainly two-fold: 1) apply different $L_p$-norm on loss function and regularization to form different variant models in different metric spaces, and 2) aggregate these variant models. Thus, the proposed MMA enjoys the multi-metric orientation from a set of dispersed metric spaces, achieving a comprehensive representation of user data. Theoretical studies proved that the proposed MMA could attain performance improvement. The extensive experiment on five real-world datasets proves that MMA can outperform seven other state-of-the-art models in predicting unobserved user behavior data.
Auto-Focus Contrastive Learning for Image Manipulation Detection
Nov 20, 2022



Generally, current image manipulation detection models are simply built on manipulation traces. However, we argue that those models achieve sub-optimal detection performance as it tends to: 1) distinguish the manipulation traces from a lot of noisy information within the entire image, and 2) ignore the trace relations among the pixels of each manipulated region and its surroundings. To overcome these limitations, we propose an Auto-Focus Contrastive Learning (AF-CL) network for image manipulation detection. It contains two main ideas, i.e., multi-scale view generation (MSVG) and trace relation modeling (TRM). Specifically, MSVG aims to generate a pair of views, each of which contains the manipulated region and its surroundings at a different scale, while TRM plays a role in modeling the trace relations among the pixels of each manipulated region and its surroundings for learning the discriminative representation. After learning the AF-CL network by minimizing the distance between the representations of corresponding views, the learned network is able to automatically focus on the manipulated region and its surroundings and sufficiently explore their trace relations for accurate manipulation detection. Extensive experiments demonstrate that, compared to the state-of-the-arts, AF-CL provides significant performance improvements, i.e., up to 2.5%, 7.5%, and 0.8% F1 score, on CAISA, NIST, and Coverage datasets, respectively.
JANOS: An Integrated Predictive and Prescriptive Modeling Framework
Nov 21, 2019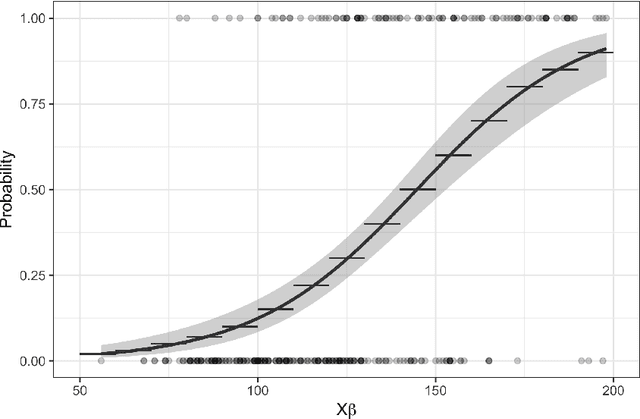
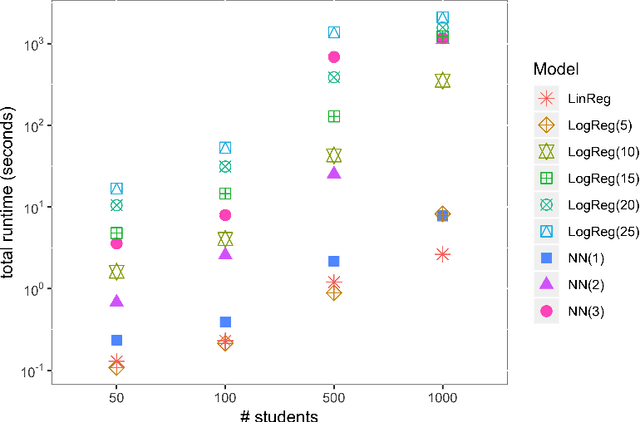
Business research practice is witnessing a surge in the integration of predictive modeling and prescriptive analysis. We describe a modeling framework JANOS that seamlessly integrates the two streams of analytics, for the first time allowing researchers and practitioners to embed machine learning models in an optimization framework. JANOS allows for specifying a prescriptive model using standard optimization modeling elements such as constraints and variables. The key novelty lies in providing modeling constructs that allow for the specification of commonly used predictive models and their features as constraints and variables in the optimization model. The framework considers two sets of decision variables; regular and predicted. The relationship between the regular and the predicted variables are specified by the user as pre-trained predictive models. JANOS currently supports linear regression, logistic regression, and neural network with rectified linear activation functions, but we plan to expand on this set in the future. In this paper, we demonstrate the flexibility of the framework through an example on scholarship allocation in a student enrollment problem and provide a numeric performance evaluation.