 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Positive and Toxic Samples for Dual Safety Self-Alignment of LLMs with Minimal Human Interventions
Feb 08, 2025Recent AI agents, such as ChatGPT and LLaMA, primarily rely on instruction tuning and reinforcement learning to calibrate the output of large language models (LLMs) with human intentions, ensuring the outputs are harmless and helpful. Existing methods heavily depend on the manual annotation of high-quality positive samples, while contending with issues such as noisy labels and minimal distinctions between preferred and dispreferred response data. However, readily available toxic samples with clear safety distinctions are often filtered out, removing valuable negative references that could aid LLMs in safety alignment. In response, we propose PT-ALIGN, a novel safety self-alignment approach that minimizes human supervision by automatically refining positive and toxic samples and performing fine-grained dual instruction tuning. Positive samples are harmless responses, while toxic samples deliberately contain extremely harmful content, serving as a new supervisory signals. Specifically, we utilize LLM itself to iteratively generate and refine training instances by only exploring fewer than 50 human annotations. We then employ two losses, i.e., maximum likelihood estimation (MLE) and fine-grained unlikelihood training (UT), to jointly learn to enhance the LLM's safety. The MLE loss encourages an LLM to maximize the generation of harmless content based on positive samples. Conversely, the fine-grained UT loss guides the LLM to minimize the output of harmful words based on negative samples at the token-level, thereby guiding the model to decouple safety from effectiveness, directing it toward safer fine-tuning objectives, and increasing the likelihood of generating helpful and reliable content. Experiments on 9 popular open-source LLMs demonstrate the effectiveness of our PT-ALIGN for safety alignment, while maintaining comparable levels of helpfulness and usefulness.
Efficient Streaming Voice Steganalysis in Challenging Detection Scenarios
Nov 20, 2024In recent years, there has been an increasing number of information hiding techniques based on network streaming media, focusing on how to covertly and efficiently embed secret information into real-time transmitted network media signals to achieve concealed communication. The misuse of these techniques can lead to significant security risks, such as the spread of malicious code, commands, and viruses. Current steganalysis methods for network voice streams face two major challenges: efficient detection under low embedding rates and short duration conditions. These challenges arise because, with low embedding rates (e.g., as low as 10%) and short transmission durations (e.g., only 0.1 second), detection models struggle to acquire sufficiently rich sample features, making effective steganalysis difficult. To address these challenges, this paper introduces a Dual-View VoIP Steganalysis Framework (DVSF). The framework first randomly obfuscates parts of the native steganographic descriptors in VoIP stream segments, making the steganographic features of hard-to-detect samples more pronounced and easier to learn. It then captures fine-grained local features related to steganography, building on the global features of VoIP. Specially constructed VoIP segment triplets further adjust the feature distances within the model. Ultimately, this method effectively address the detection difficulty in VoIP. Extensive experiments demonstrate that our method significantly improves the accuracy of streaming voice steganalysis in these challenging detection scenarios, surpassing existing state-of-the-art methods and offering superior near-real-time performance.
ContextBLIP: Doubly Contextual Alignment for Contrastive Image Retrieval from Linguistically Complex Descriptions
May 29, 2024Image retrieval from contextual descriptions (IRCD) aims to identify an image within a set of minimally contrastive candidates based on linguistically complex text. Despite the success of VLMs, they still significantly lag behind human performance in IRCD. The main challenges lie in aligning key contextual cues in two modalities, where these subtle cues are concealed in tiny areas of multiple contrastive images and within the complex linguistics of textual descriptions. This motivates us to propose ContextBLIP, a simple yet effective method that relies on a doubly contextual alignment scheme for challenging IRCD. Specifically, 1) our model comprises a multi-scale adapter, a matching loss, and a text-guided masking loss. The adapter learns to capture fine-grained visual cues. The two losses enable iterative supervision for the adapter, gradually highlighting the focal patches of a single image to the key textual cues. We term such a way as intra-contextual alignment. 2) Then, ContextBLIP further employs an inter-context encoder to learn dependencies among candidates, facilitating alignment between the text to multiple images. We term this step as inter-contextual alignment. Consequently, the nuanced cues concealed in each modality can be effectively aligned. Experiments on two benchmarks show the superiority of our method. We observe that ContextBLIP can yield comparable results with GPT-4V, despite involving about 7,500 times fewer parameters.
GanFinger: GAN-Based Fingerprint Generation for Deep Neural Network Ownership Verification
Dec 25, 2023



Deep neural networks (DNNs) are extensively employed in a wide range of application scenarios. Generally, training a commercially viable neural network requires significant amounts of data and computing resources, and it is easy for unauthorized users to use the networks illegally. Therefore, network ownership verification has become one of the most crucial steps in safeguarding digital assets. To verify the ownership of networks, the existing network fingerprinting approaches perform poorly in the aspects of efficiency, stealthiness, and discriminability. To address these issues, we propose a network fingerprinting approach, named as GanFinger, to construct the network fingerprints based on the network behavior, which is characterized by network outputs of pairs of original examples and conferrable adversarial examples. Specifically, GanFinger leverages Generative Adversarial Networks (GANs) to effectively generate conferrable adversarial examples with imperceptible perturbations. These examples can exhibit identical outputs on copyrighted and pirated networks while producing different results on irrelevant networks. Moreover, to enhance the accuracy of fingerprint ownership verification, the network similarity is computed based on the accuracy-robustness distance of fingerprint examples'outputs. To evaluate the performance of GanFinger, we construct a comprehensive benchmark consisting of 186 networks with five network structures and four popular network post-processing techniques. The benchmark experiments demonstrate that GanFinger significantly outperforms the state-of-the-arts in efficiency, stealthiness, and discriminability. It achieves a remarkable 6.57 times faster in fingerprint generation and boosts the ARUC value by 0.175, resulting in a relative improvement of about 26%.
Traceable and Authenticable Image Tagging for Fake News Detection
Nov 20, 2022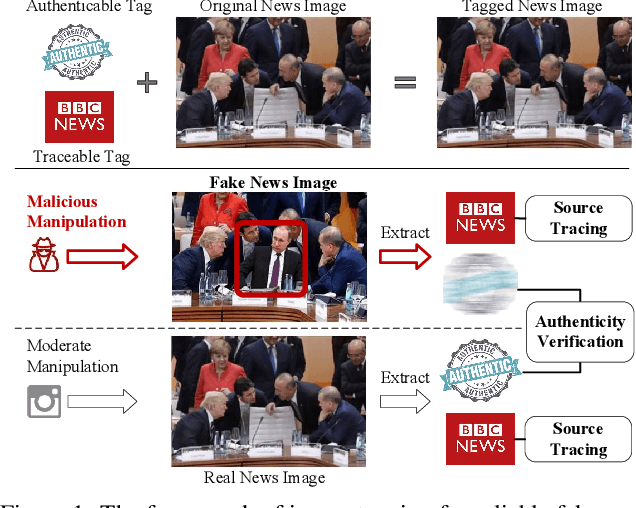

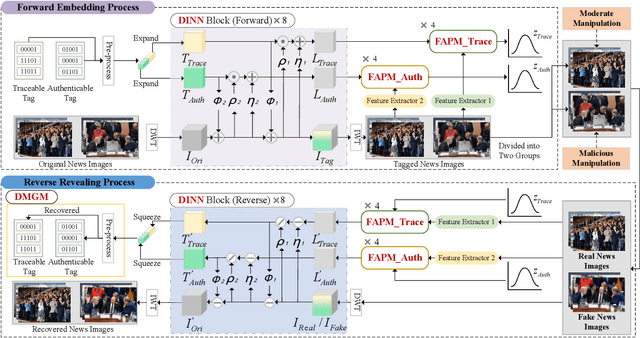
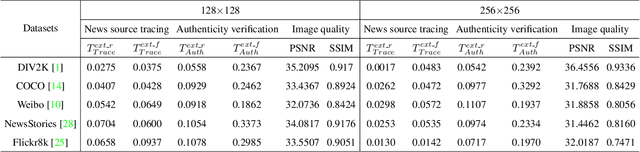
To prevent fake news images from misleading the public, it is desirable not only to verify the authenticity of news images but also to trace the source of fake news, so as to provide a complete forensic chain for reliable fake news detection. To simultaneously achieve the goals of authenticity verification and source tracing, we propose a traceable and authenticable image tagging approach that is based on a design of Decoupled Invertible Neural Network (DINN). The designed DINN can simultaneously embed the dual-tags, \textit{i.e.}, authenticable tag and traceable tag, into each news image before publishing, and then separately extract them for authenticity verification and source tracing. Moreover, to improve the accuracy of dual-tags extraction, we design a parallel Feature Aware Projection Model (FAPM) to help the DINN preserve essential tag information. In addition, we define a Distance Metric-Guided Module (DMGM) that learns asymmetric one-class representations to enable the dual-tags to achieve different robustness performances under malicious manipulations. Extensive experiments, on diverse datasets and unseen manipulations, demonstrate that the proposed tagging approach achieves excellent performance in the aspects of both authenticity verification and source tracing for reliable fake news detection and outperforms the prior works.
Auto-Focus Contrastive Learning for Image Manipulation Detection
Nov 20, 2022



Generally, current image manipulation detection models are simply built on manipulation traces. However, we argue that those models achieve sub-optimal detection performance as it tends to: 1) distinguish the manipulation traces from a lot of noisy information within the entire image, and 2) ignore the trace relations among the pixels of each manipulated region and its surroundings. To overcome these limitations, we propose an Auto-Focus Contrastive Learning (AF-CL) network for image manipulation detection. It contains two main ideas, i.e., multi-scale view generation (MSVG) and trace relation modeling (TRM). Specifically, MSVG aims to generate a pair of views, each of which contains the manipulated region and its surroundings at a different scale, while TRM plays a role in modeling the trace relations among the pixels of each manipulated region and its surroundings for learning the discriminative representation. After learning the AF-CL network by minimizing the distance between the representations of corresponding views, the learned network is able to automatically focus on the manipulated region and its surroundings and sufficiently explore their trace relations for accurate manipulation detection. Extensive experiments demonstrate that, compared to the state-of-the-arts, AF-CL provides significant performance improvements, i.e., up to 2.5%, 7.5%, and 0.8% F1 score, on CAISA, NIST, and Coverage datasets, respectively.
Real-World Image Super Resolution via Unsupervised Bi-directional Cycle Domain Transfer Learning based Generative Adversarial Network
Nov 19, 2022



Deep Convolutional Neural Networks (DCNNs) have exhibited impressive performance on image super-resolution tasks. However, these deep learning-based super-resolution methods perform poorly in real-world super-resolution tasks, where the paired high-resolution and low-resolution images are unavailable and the low-resolution images are degraded by complicated and unknown kernels. To break these limitations, we propose the Unsupervised Bi-directional Cycle Domain Transfer Learning-based Generative Adversarial Network (UBCDTL-GAN), which consists of an Unsupervised Bi-directional Cycle Domain Transfer Network (UBCDTN) and the Semantic Encoder guided Super Resolution Network (SESRN). First, the UBCDTN is able to produce an approximated real-like LR image through transferring the LR image from an artificially degraded domain to the real-world LR image domain. Second, the SESRN has the ability to super-resolve the approximated real-like LR image to a photo-realistic HR image. Extensive experiments on unpaired real-world image benchmark datasets demonstrate that the proposed method achieves superior performance compared to state-of-the-art methods.
Continual Learning for Steganalysis
Sep 03, 2022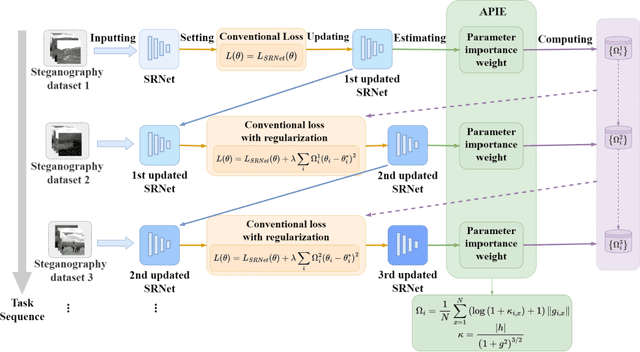
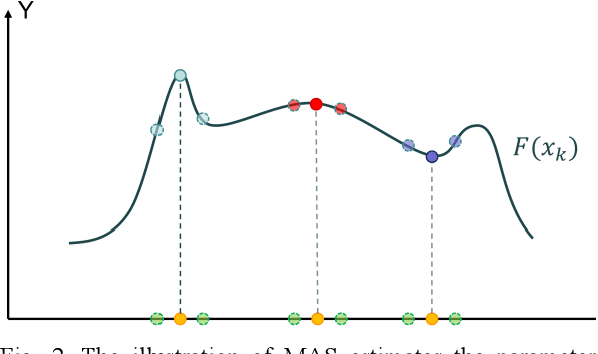
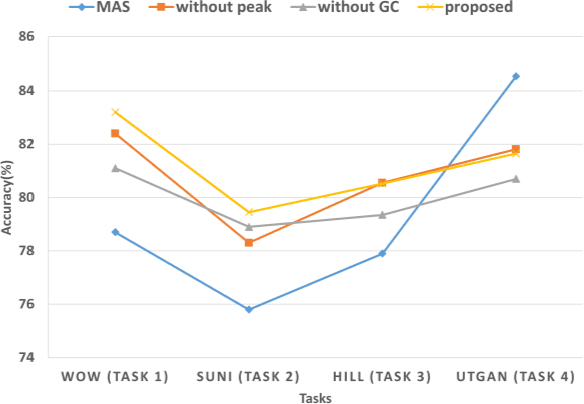
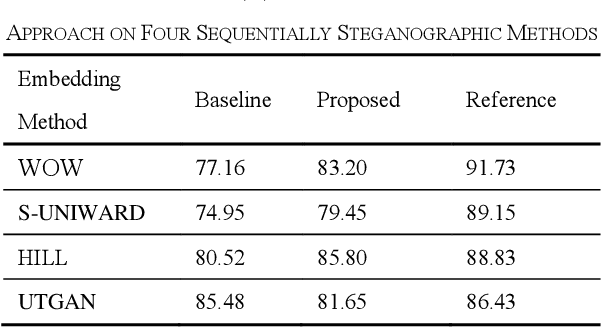
To detect the existing steganographic algorithms, recent steganalysis methods usually train a Convolutional Neural Network (CNN) model on the dataset consisting of corresponding paired cover/stego-images. However, it is inefficient and impractical for those steganalysis tools to completely retrain the CNN model to make it effective against both the existing steganographic algorithms and a new emerging steganographic algorithm. Thus, existing steganalysis models usually lack dynamic extensibility for new steganographic algorithms, which limits their application in real-world scenarios. To address this issue, we propose an accurate parameter importance estimation (APIE) based-continual learning scheme for steganalysis. In this scheme, when a steganalysis model is trained on the new image dataset generated by the new steganographic algorithm, its network parameters are effectively and efficiently updated with sufficient consideration of their importance evaluated in the previous training process. This approach can guide the steganalysis model to learn the patterns of the new steganographic algorithm without significantly degrading the detectability against the previous steganographic algorithms. Experimental results demonstrate the proposed scheme has promising extensibility for new emerging steganographic algorithms.
Learning Hierarchical Graph Representation for Image Manipulation Detection
Jan 15, 2022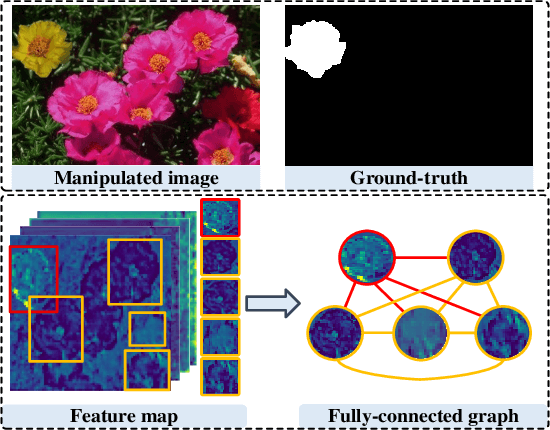
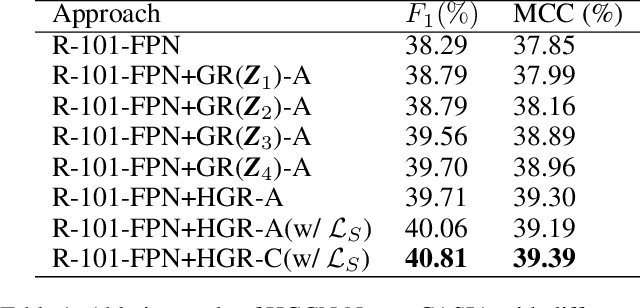
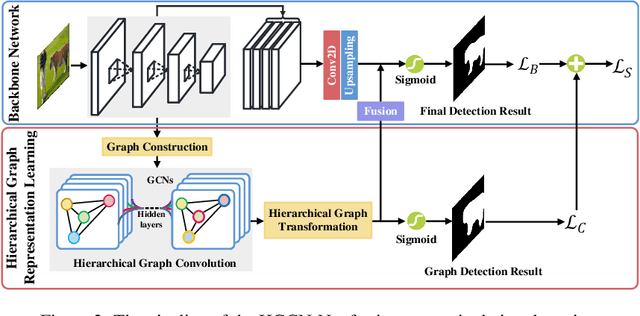
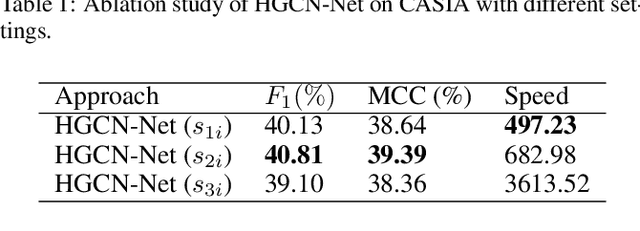
The objective of image manipulation detection is to identify and locate the manipulated regions in the images. Recent approaches mostly adopt the sophisticated Convolutional Neural Networks (CNNs) to capture the tampering artifacts left in the images to locate the manipulated regions. However, these approaches ignore the feature correlations, i.e., feature inconsistencies, between manipulated regions and non-manipulated regions, leading to inferior detection performance. To address this issue, we propose a hierarchical Graph Convolutional Network (HGCN-Net), which consists of two parallel branches: the backbone network branch and the hierarchical graph representation learning (HGRL) branch for image manipulation detection. Specifically, the feature maps of a given image are extracted by the backbone network branch, and then the feature correlations within the feature maps are modeled as a set of fully-connected graphs for learning the hierarchical graph representation by the HGRL branch. The learned hierarchical graph representation can sufficiently capture the feature correlations across different scales, and thus it provides high discriminability for distinguishing manipulated and non-manipulated regions. Extensive experiments on four public datasets demonstrate that the proposed HGCN-Net not only provides promising detection accuracy, but also achieves strong robustness under a variety of common image attacks in the task of image manipulation detection, compared to the state-of-the-arts.