 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Scaling with Reflective Generative Model
Jul 02, 2025We introduce our first reflective generative model MetaStone-S1, which obtains OpenAI o3's performance via the self-supervised process reward model (SPRM). Through sharing the backbone network and using task-specific heads for next token prediction and process scoring respectively, SPRM successfully integrates the policy model and process reward model(PRM) into a unified interface without extra process annotation, reducing over 99% PRM parameters for efficient reasoning. Equipped with SPRM, MetaStone-S1 is naturally suitable for test time scaling (TTS), and we provide three reasoning effort modes (low, medium, and high), based on the controllable thinking length. Moreover, we empirically establish a scaling law that reveals the relationship between total thinking computation and TTS performance. Experiments demonstrate that our MetaStone-S1 achieves comparable performance to OpenAI-o3-mini's series with only 32B parameter size. To support the research community, we have open-sourced MetaStone-S1 at https://github.com/MetaStone-AI/MetaStone-S1.
Rebalancing Multi-Label Class-Incremental Learning
Aug 22, 2024Multi-label class-incremental learning (MLCIL) is essential for real-world multi-label applications, allowing models to learn new labels while retaining previously learned knowledge continuously. However, recent MLCIL approaches can only achieve suboptimal performance due to the oversight of the positive-negative imbalance problem, which manifests at both the label and loss levels because of the task-level partial label issue. The imbalance at the label level arises from the substantial absence of negative labels, while the imbalance at the loss level stems from the asymmetric contributions of the positive and negative loss parts to the optimization. To address the issue above, we propose a Rebalance framework for both the Loss and Label levels (RebLL), which integrates two key modules: asymmetric knowledge distillation (AKD) and online relabeling (OR). AKD is proposed to rebalance at the loss level by emphasizing the negative label learning in classification loss and down-weighting the contribution of overconfident predictions in distillation loss. OR is designed for label rebalance, which restores the original class distribution in memory by online relabeling the missing classes. Our comprehensive experiments on the PASCAL VOC and MS-COCO datasets demonstrate that this rebalancing strategy significantly improves performance, achieving new state-of-the-art results even with a vanilla CNN backbone.
Towards stable training of parallel continual learning
Jul 11, 2024



Parallel Continual Learning (PCL) tasks investigate the training methods for continual learning with multi-source input, where data from different tasks are learned as they arrive. PCL offers high training efficiency and is well-suited for complex multi-source data systems, such as autonomous vehicles equipped with multiple sensors. However, at any time, multiple tasks need to be trained simultaneously, leading to severe training instability in PCL. This instability manifests during both forward and backward propagation, where features are entangled and gradients are conflict. This paper introduces Stable Parallel Continual Learning (SPCL), a novel approach that enhances the training stability of PCL for both forward and backward propagation. For the forward propagation, we apply Doubly-block Toeplit (DBT) Matrix based orthogonality constraints to network parameters to ensure stable and consistent propagation. For the backward propagation, we employ orthogonal decomposition for gradient management stabilizes backpropagation and mitigates gradient conflicts across tasks. By optimizing gradients by ensuring orthogonality and minimizing the condition number, SPCL effectively stabilizing the gradient descent in complex optimization tasks. Experimental results demonstrate that SPCL outperforms state-of-the-art methjods and achieve better training stability.
Confidence Self-Calibration for Multi-Label Class-Incremental Learning
Mar 19, 2024



The partial label challenge in Multi-Label Class-Incremental Learning (MLCIL) arises when only the new classes are labeled during training, while past and future labels remain unavailable. This issue leads to a proliferation of false-positive errors due to erroneously high confidence multi-label predictions, exacerbating catastrophic forgetting within the disjoint label space. In this paper, we aim to refine multi-label confidence calibration in MLCIL and propose a Confidence Self-Calibration (CSC) approach. Firstly, for label relationship calibration, we introduce a class-incremental graph convolutional network that bridges the isolated label spaces by constructing learnable, dynamically extended label relationship graph. Then, for confidence calibration, we present a max-entropy regularization for each multi-label increment, facilitating confidence self-calibration through the penalization of over-confident output distributions. Our approach attains new state-of-the-art results in MLCIL tasks on both MS-COCO and PASCAL VOC datasets, with the calibration of label confidences confirmed through our methodology.
Variational Continual Test-Time Adaptation
Feb 13, 2024



The prior drift is crucial in Continual Test-Time Adaptation (CTTA) methods that only use unlabeled test data, as it can cause significant error propagation. In this paper, we introduce VCoTTA, a variational Bayesian approach to measure uncertainties in CTTA. At the source stage, we transform a pre-trained deterministic model into a Bayesian Neural Network (BNN) via a variational warm-up strategy, injecting uncertainties into the model. During the testing time, we employ a mean-teacher update strategy using variational inference for the student model and exponential moving average for the teacher model. Our novel approach updates the student model by combining priors from both the source and teacher models. The evidence lower bound is formulated as the cross-entropy between the student and teacher models, along with the Kullback-Leibler (KL) divergence of the prior mixture. Experimental results on three datasets demonstrate the method's effectiveness in mitigating prior drift within the CTTA framework.
Auto-Focus Contrastive Learning for Image Manipulation Detection
Nov 20, 2022



Generally, current image manipulation detection models are simply built on manipulation traces. However, we argue that those models achieve sub-optimal detection performance as it tends to: 1) distinguish the manipulation traces from a lot of noisy information within the entire image, and 2) ignore the trace relations among the pixels of each manipulated region and its surroundings. To overcome these limitations, we propose an Auto-Focus Contrastive Learning (AF-CL) network for image manipulation detection. It contains two main ideas, i.e., multi-scale view generation (MSVG) and trace relation modeling (TRM). Specifically, MSVG aims to generate a pair of views, each of which contains the manipulated region and its surroundings at a different scale, while TRM plays a role in modeling the trace relations among the pixels of each manipulated region and its surroundings for learning the discriminative representation. After learning the AF-CL network by minimizing the distance between the representations of corresponding views, the learned network is able to automatically focus on the manipulated region and its surroundings and sufficiently explore their trace relations for accurate manipulation detection. Extensive experiments demonstrate that, compared to the state-of-the-arts, AF-CL provides significant performance improvements, i.e., up to 2.5%, 7.5%, and 0.8% F1 score, on CAISA, NIST, and Coverage datasets, respectively.
Optimization Induced Equilibrium Networks
Jun 07, 2021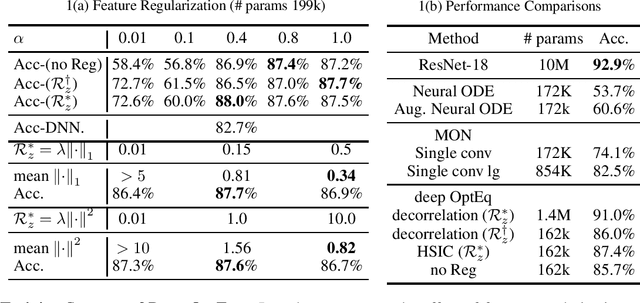


Implicit equilibrium models, i.e., deep neural networks (DNNs) defined by implicit equations, have been becoming more and more attractive recently. In this paper, we investigate an emerging question: can an implicit equilibrium model's equilibrium point be regarded as the solution of an optimization problem? To this end, we first decompose DNNs into a new class of unit layer that is the proximal operator of an implicit convex function while keeping its output unchanged. Then, the equilibrium model of the unit layer can be derived, named Optimization Induced Equilibrium Networks (OptEq), which can be easily extended to deep layers. The equilibrium point of OptEq can be theoretically connected to the solution of its corresponding convex optimization problem with explicit objectives. Based on this, we can flexibly introduce prior properties to the equilibrium points: 1) modifying the underlying convex problems explicitly so as to change the architectures of OptEq; and 2) merging the information into the fixed point iteration, which guarantees to choose the desired equilibrium point when the fixed point set is non-singleton. We show that deep OptEq outperforms previous implicit models even with fewer parameters. This work establishes the first step towards the optimization-guided design of deep models.
Time Series Forecasting via Learning Convolutionally Low-Rank Models
Apr 23, 2021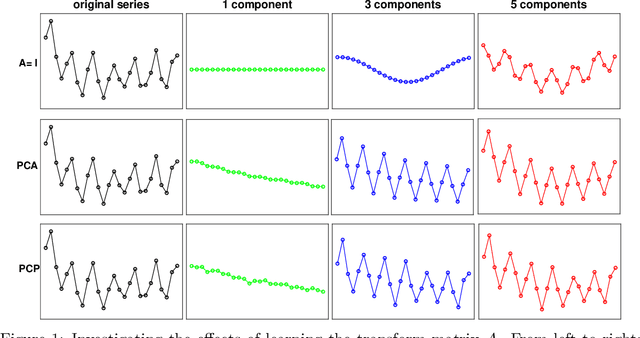



Recently,~\citet{liu:arxiv:2019} studied the rather challenging problem of time series forecasting from the perspective of compressed sensing. They proposed a no-learning method, named Convolution Nuclear Norm Minimization (CNNM), and proved that CNNM can exactly recover the future part of a series from its observed part, provided that the series is convolutionally low-rank. While impressive, the convolutional low-rankness condition may not be satisfied whenever the series is far from being seasonal, and is in fact brittle to the presence of trends and dynamics. This paper tries to approach the issues by integrating a learnable, orthonormal transformation into CNNM, with the purpose for converting the series of involute structures into regular signals of convolutionally low-rank. We prove that the resulted model, termed Learning-Based CNNM (LbCNNM), strictly succeeds in identifying the future part of a series, as long as the transform of the series is convolutionally low-rank. To learn proper transformations that may meet the required success conditions, we devise an interpretable method based on Principal Component Purist (PCP). Equipped with this learning method and some elaborate data argumentation skills, LbCNNM not only can handle well the major components of time series (including trends, seasonality and dynamics), but also can make use of the forecasts provided by some other forecasting methods; this means LbCNNM can be used as a general tool for model combination. Extensive experiments on 100,452 real-world time series from TSDL and M4 demonstrate the superior performance of LbCNNM.
Maximum-and-Concatenation Networks
Jul 09, 2020



While successful in many fields, deep neural networks (DNNs) still suffer from some open problems such as bad local minima and unsatisfactory generalization performance. In this work, we propose a novel architecture called Maximum-and-Concatenation Networks (MCN) to try eliminating bad local minima and improving generalization ability as well. Remarkably, we prove that MCN has a very nice property; that is, \emph{every local minimum of an $(l+1)$-layer MCN can be better than, at least as good as, the global minima of the network consisting of its first $l$ layers}. In other words, by increasing the network depth, MCN can autonomously improve its local minima's goodness, what is more, \emph{it is easy to plug MCN into an existing deep model to make it also have this property}. Finally, under mild conditions, we show that MCN can approximate certain continuous functions arbitrarily well with \emph{high efficiency}; that is, the covering number of MCN is much smaller than most existing DNNs such as deep ReLU. Based on this, we further provide a tight generalization bound to guarantee the inference ability of MCN when dealing with testing samples.
Multilayer Collaborative Low-Rank Coding Network for Robust Deep Subspace Discovery
Jan 15, 2020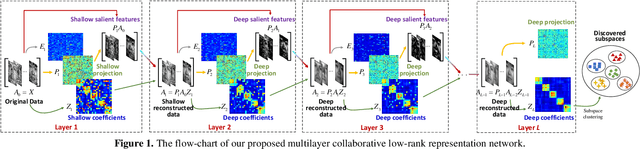
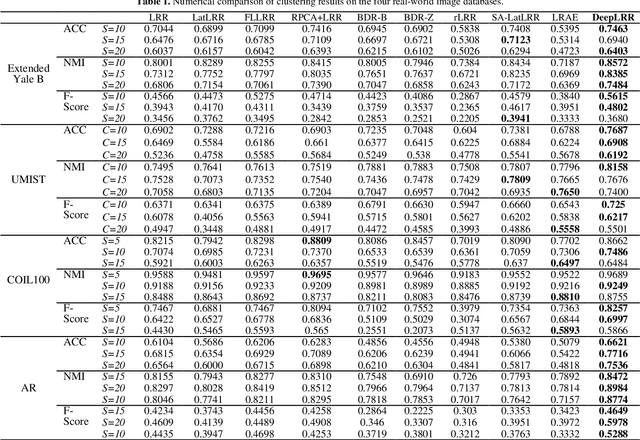


For subspace recovery, most existing low-rank representation (LRR) models performs in the original space in single-layer mode. As such, the deep hierarchical information cannot be learned, which may result in inaccurate recoveries for complex real data. In this paper, we explore the deep multi-subspace recovery problem by designing a multilayer architecture for latent LRR. Technically, we propose a new Multilayer Collabora-tive Low-Rank Representation Network model termed DeepLRR to discover deep features and deep subspaces. In each layer (>2), DeepLRR bilinearly reconstructs the data matrix by the collabo-rative representation with low-rank coefficients and projection matrices in the previous layer. The bilinear low-rank reconstruc-tion of previous layer is directly fed into the next layer as the input and low-rank dictionary for representation learning, and is further decomposed into a deep principal feature part, a deep salient feature part and a deep sparse error. As such, the coher-ence issue can be also resolved due to the low-rank dictionary, and the robustness against noise can also be enhanced in the feature subspace. To recover the sparse errors in layers accurately, a dynamic growing strategy is used, as the noise level will be-come smaller for the increase of layers. Besides, a neighborhood reconstruction error is also included to encode the locality of deep salient features by deep coefficients adaptively in each layer. Extensive results on public databases show that our DeepLRR outperforms other related models for subspace discovery and clustering.