 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 Challenge on Real-World All-in-One Image Restoration: Methods and Results
Apr 21, 2026This paper presents a review for the LoViF Challenge on Real-World All-in-One Image Restoration. The challenge aimed to advance research on real-world all-in-one image restoration under diverse real-world degradation conditions, including blur, low-light, haze, rain, and snow. It provided a unified benchmark to evaluate the robustness and generalization ability of restoration models across multiple degradation categories within a common framework. The competition attracted 124 registered participants and received 9 valid final submissions with corresponding fact sheets, significantly contributing to the progress of real-world all-in-one image restoration. This report provides a detailed analysis of the submitted methods and corresponding results, emphasizing recent progress in unified real-world image restoration. The analysis highlights effective approaches and establishes a benchmark for future research in real-world low-level vision.
LoViF 2026 The First Challenge on Weather Removal in Videos
Apr 14, 2026This paper presents a review of the LoViF 2026 Challenge on Weather Removal in Videos. The challenge encourages the development of methods for restoring clean videos from inputs degraded by adverse weather conditions such as rain and snow, with an emphasis on achieving visually plausible and temporally consistent results while preserving scene structure and motion dynamics. To support this task, we introduce a new short-form WRV dataset tailored for video weather removal. It consists of 18 videos 1,216 synthesized frames paired with 1,216 real-world ground-truth frames at a resolution of 832 x 480, and is split into training, validation, and test sets with a ratio of 1:1:1. The goal of this challenge is to advance robust and realistic video restoration under real-world weather conditions, with evaluation protocols that jointly consider fidelity and perceptual quality. The challenge attracted 37 participants and received 5 valid final submissions with corresponding fact sheets, contributing to progress in weather removal for videos. The project is publicly available at https://www.codabench.org/competitions/13462/.
NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
NTIRE 2026 Challenge on Bitstream-Corrupted Video Restoration: Methods and Results
Apr 09, 2026This paper reports on the NTIRE 2026 Challenge on Bitstream-Corrupted Video Restoration (BSCVR). The challenge aims to advance research on recovering visually coherent videos from corrupted bitstreams, whose decoding often produces severe spatial-temporal artifacts and content distortion. Built upon recent progress in bitstream-corrupted video recovery, the challenge provides a common benchmark for evaluating restoration methods under realistic corruption settings. We describe the dataset, evaluation protocol, and participating methods, and summarize the final results and main technical trends. The challenge highlights the difficulty of this emerging task and provides useful insights for future research on robust video restoration under practical bitstream corruption.
Composer 2 Technical Report
Mar 25, 2026Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
Advancing Automated Algorithm Design via Evolutionary Stagewise Design with LLMs
Mar 09, 2026With the rapid advancement of human science and technology, problems in industrial scenarios are becoming increasingly challenging, bringing significant challenges to traditional algorithm design. Automated algorithm design with LLMs emerges as a promising solution, but the currently adopted black-box modeling deprives LLMs of any awareness of the intrinsic mechanism of the target problem, leading to hallucinated designs. In this paper, we introduce Evolutionary Stagewise Algorithm Design (EvoStage), a novel evolutionary paradigm that bridges the gap between the rigorous demands of industrial-scale algorithm design and the LLM-based algorithm design methods. Drawing inspiration from CoT, EvoStage decomposes the algorithm design process into sequential, manageable stages and integrates real-time intermediate feedback to iteratively refine algorithm design directions. To further reduce the algorithm design space and avoid falling into local optima, we introduce a multi-agent system and a "global-local perspective" mechanism. We apply EvoStage to the design of two types of common optimizers: designing parameter configuration schedules of the Adam optimizer for chip placement, and designing acquisition functions of Bayesian optimization for black-box optimization. Experimental results across open-source benchmarks demonstrate that EvoStage outperforms human-expert designs and existing LLM-based methods within only a couple of evolution steps, even achieving the historically state-of-the-art half-perimeter wire-length results on every tested chip case. Furthermore, when deployed on a commercial-grade 3D chip placement tool, EvoStage significantly surpasses the original performance metrics, achieving record-breaking efficiency. We hope EvoStage can significantly advance automated algorithm design in the real world, helping elevate human productivity.
Pre-Trained Large Language Model Based Remaining Useful Life Transfer Prediction of Bearing
Jan 13, 2025



Accurately predicting the remaining useful life (RUL) of rotating machinery, such as bearings, is essential for ensuring equipment reliability and minimizing unexpected industrial failures. Traditional data-driven deep learning methods face challenges in practical settings due to inconsistent training and testing data distributions and limited generalization for long-term predictions.
LLM-R: A Framework for Domain-Adaptive Maintenance Scheme Generation Combining Hierarchical Agents and RAG
Nov 07, 2024



The increasing use of smart devices has emphasized the critical role of maintenance in production activities. Interactive Electronic Technical Manuals (IETMs) are vital tools that support the maintenance of smart equipment. However, traditional IETMs face challenges such as transitioning from Graphical User Interfaces (GUIs) to natural Language User Interfaces (LUIs) and managing complex logical relationships. Additionally, they must meet the current demands for higher intelligence. This paper proposes a Maintenance Scheme Generation Method based on Large Language Models (LLM-R). The proposed method includes several key innovations: We propose the Low Rank Adaptation-Knowledge Retention (LORA-KR) loss technology to proportionally adjust mixed maintenance data for fine-tuning the LLM. This method prevents knowledge conflicts caused by mixed data, improving the model's adaptability and reasoning ability in specific maintenance domains, Besides, Hierarchical Task-Based Agent and Instruction-level Retrieval-Augmented Generation (RAG) technologies are adopted to optimize the generation steps and mitigate the phenomenon of hallucination caused by the model's Inability to access contextual information. This enhancement improves the model's flexibility and accuracy in handling known or unknown maintenance objects and maintenance scheme scenarios. To validate the proposed method's effectiveness in maintenance tasks, a maintenance scheme dataset was constructed using objects from different fields. The experimental results show that the accuracy of the maintenance schemes generated by the proposed method reached 91.59%, indicating which improvement enhances the intelligence of maintenance schemes and introduces novel technical approaches for equipment maintenance.
LLM-based Framework for Bearing Fault Diagnosis
Nov 05, 2024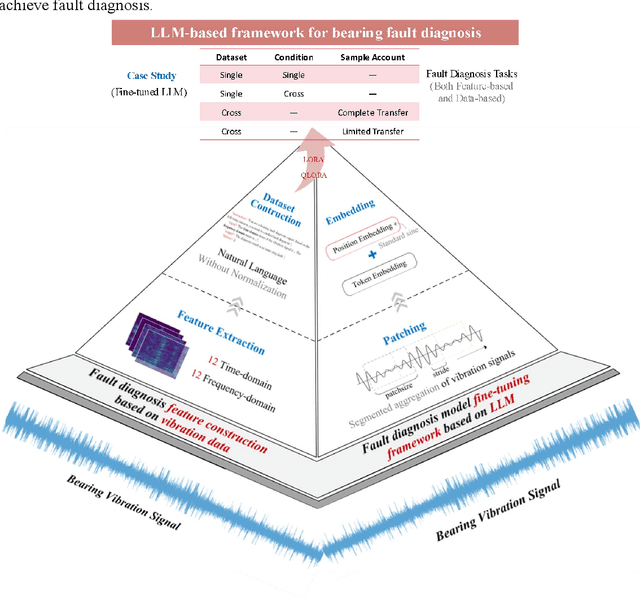



Accurately diagnosing bearing faults is crucial for maintaining the efficient operation of rotating machinery. However, traditional diagnosis methods face challenges due to the diversification of application environments, including cross-condition adaptability, small-sample learning difficulties, and cross-dataset generalization. These challenges have hindered the effectiveness and limited the application of existing approaches. Large language models (LLMs) offer new possibilities for improving the generalization of diagnosis models. However, the integration of LLMs with traditional diagnosis techniques for optimal generalization remains underexplored. This paper proposed an LLM-based bearing fault diagnosis framework to tackle these challenges. First, a signal feature quantification method was put forward to address the issue of extracting semantic information from vibration data, which integrated time and frequency domain feature extraction based on a statistical analysis framework. This method textualized time-series data, aiming to efficiently learn cross-condition and small-sample common features through concise feature selection. Fine-tuning methods based on LoRA and QLoRA were employed to enhance the generalization capability of LLMs in analyzing vibration data features. In addition, the two innovations (textualizing vibration features and fine-tuning pre-trained models) were validated by single-dataset cross-condition and cross-dataset transfer experiment with complete and limited data. The results demonstrated the ability of the proposed framework to perform three types of generalization tasks simultaneously. Trained cross-dataset models got approximately a 10% improvement in accuracy, proving the adaptability of LLMs to input patterns. Ultimately, the results effectively enhance the generalization capability and fill the research gap in using LLMs for bearing fault diagnosis.
RSL-BA: Rolling Shutter Line Bundle Adjustment
Aug 10, 2024
The line is a prevalent element in man-made environments, inherently encoding spatial structural information, thus making it a more robust choice for feature representation in practical applications. Despite its apparent advantages, previous rolling shutter bundle adjustment (RSBA) methods have only supported sparse feature points, which lack robustness, particularly in degenerate environments. In this paper, we introduce the first rolling shutter line-based bundle adjustment solution, RSL-BA. Specifically, we initially establish the rolling shutter camera line projection theory utilizing Pl\"ucker line parameterization. Subsequently, we derive a series of reprojection error formulations which are stable and efficient. Finally, we theoretically and experimentally demonstrate that our method can prevent three common degeneracies, one of which is first discovered in this paper. Extensive synthetic and real data experiments demonstrate that our method achieves efficiency and accuracy comparable to existing point-based rolling shutter bundle adjustment solutions.