 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Global Solvers for 3D Vision
Feb 16, 2026Global solvers have emerged as a powerful paradigm for 3D vision, offering certifiable solutions to nonconvex geometric optimization problems traditionally addressed by local or heuristic methods. This survey presents the first systematic review of global solvers in geometric vision, unifying the field through a comprehensive taxonomy of three core paradigms: Branch-and-Bound (BnB), Convex Relaxation (CR), and Graduated Non-Convexity (GNC). We present their theoretical foundations, algorithmic designs, and practical enhancements for robustness and scalability, examining how each addresses the fundamental nonconvexity of geometric estimation problems. Our analysis spans ten core vision tasks, from Wahba problem to bundle adjustment, revealing the optimality-robustness-scalability trade-offs that govern solver selection. We identify critical future directions: scaling algorithms while maintaining guarantees, integrating data-driven priors with certifiable optimization, establishing standardized benchmarks, and addressing societal implications for safety-critical deployment. By consolidating theoretical foundations, practical advances, and broader impacts, this survey provides a unified perspective and roadmap toward certifiable, trustworthy perception for real-world applications. A continuously-updated literature summary and companion code tutorials are available at https://github.com/ericzzj1989/Awesome-Global-Solvers-for-3D-Vision.
FlowHOI: Flow-based Semantics-Grounded Generation of Hand-Object Interactions for Dexterous Robot Manipulation
Feb 13, 2026Recent vision-language-action (VLA) models can generate plausible end-effector motions, yet they often fail in long-horizon, contact-rich tasks because the underlying hand-object interaction (HOI) structure is not explicitly represented. An embodiment-agnostic interaction representation that captures this structure would make manipulation behaviors easier to validate and transfer across robots. We propose FlowHOI, a two-stage flow-matching framework that generates semantically grounded, temporally coherent HOI sequences, comprising hand poses, object poses, and hand-object contact states, conditioned on an egocentric observation, a language instruction, and a 3D Gaussian splatting (3DGS) scene reconstruction. We decouple geometry-centric grasping from semantics-centric manipulation, conditioning the latter on compact 3D scene tokens and employing a motion-text alignment loss to semantically ground the generated interactions in both the physical scene layout and the language instruction. To address the scarcity of high-fidelity HOI supervision, we introduce a reconstruction pipeline that recovers aligned hand-object trajectories and meshes from large-scale egocentric videos, yielding an HOI prior for robust generation. Across the GRAB and HOT3D benchmarks, FlowHOI achieves the highest action recognition accuracy and a 1.7$\times$ higher physics simulation success rate than the strongest diffusion-based baseline, while delivering a 40$\times$ inference speedup. We further demonstrate real-robot execution on four dexterous manipulation tasks, illustrating the feasibility of retargeting generated HOI representations to real-robot execution pipelines.
Neural Predictor-Corrector: Solving Homotopy Problems with Reinforcement Learning
Feb 03, 2026The Homotopy paradigm, a general principle for solving challenging problems, appears across diverse domains such as robust optimization, global optimization, polynomial root-finding, and sampling. Practical solvers for these problems typically follow a predictor-corrector (PC) structure, but rely on hand-crafted heuristics for step sizes and iteration termination, which are often suboptimal and task-specific. To address this, we unify these problems under a single framework, which enables the design of a general neural solver. Building on this unified view, we propose Neural Predictor-Corrector (NPC), which replaces hand-crafted heuristics with automatically learned policies. NPC formulates policy selection as a sequential decision-making problem and leverages reinforcement learning to automatically discover efficient strategies. To further enhance generalization, we introduce an amortized training mechanism, enabling one-time offline training for a class of problems and efficient online inference on new instances. Experiments on four representative homotopy problems demonstrate that our method generalizes effectively to unseen instances. It consistently outperforms classical and specialized baselines in efficiency while demonstrating superior stability across tasks, highlighting the value of unifying homotopy methods into a single neural framework.
DynaWeb: Model-Based Reinforcement Learning of Web Agents
Jan 29, 2026The development of autonomous web agents, powered by Large Language Models (LLMs) and reinforcement learning (RL), represents a significant step towards general-purpose AI assistants. However, training these agents is severely hampered by the challenges of interacting with the live internet, which is inefficient, costly, and fraught with risks. Model-based reinforcement learning (MBRL) offers a promising solution by learning a world model of the environment to enable simulated interaction. This paper introduces DynaWeb, a novel MBRL framework that trains web agents through interacting with a web world model trained to predict naturalistic web page representations given agent actions. This model serves as a synthetic web environment where an agent policy can dream by generating vast quantities of rollout action trajectories for efficient online reinforcement learning. Beyond free policy rollouts, DynaWeb incorporates real expert trajectories from training data, which are randomly interleaved with on-policy rollouts during training to improve stability and sample efficiency. Experiments conducted on the challenging WebArena and WebVoyager benchmarks demonstrate that DynaWeb consistently and significantly improves the performance of state-of-the-art open-source web agent models. Our findings establish the viability of training web agents through imagination, offering a scalable and efficient way to scale up online agentic RL.
MoCA: Mixture-of-Components Attention for Scalable Compositional 3D Generation
Dec 08, 2025Compositionality is critical for 3D object and scene generation, but existing part-aware 3D generation methods suffer from poor scalability due to quadratic global attention costs when increasing the number of components. In this work, we present MoCA, a compositional 3D generative model with two key designs: (1) importance-based component routing that selects top-k relevant components for sparse global attention, and (2) unimportant components compression that preserve contextual priors of unselected components while reducing computational complexity of global attention. With these designs, MoCA enables efficient, fine-grained compositional 3D asset creation with scalable number of components. Extensive experiments show MoCA outperforms baselines on both compositional object and scene generation tasks. Project page: https://lizhiqi49.github.io/MoCA
E-MoFlow: Learning Egomotion and Optical Flow from Event Data via Implicit Regularization
Oct 14, 2025



The estimation of optical flow and 6-DoF ego-motion, two fundamental tasks in 3D vision, has typically been addressed independently. For neuromorphic vision (e.g., event cameras), however, the lack of robust data association makes solving the two problems separately an ill-posed challenge, especially in the absence of supervision via ground truth. Existing works mitigate this ill-posedness by either enforcing the smoothness of the flow field via an explicit variational regularizer or leveraging explicit structure-and-motion priors in the parametrization to improve event alignment. The former notably introduces bias in results and computational overhead, while the latter, which parametrizes the optical flow in terms of the scene depth and the camera motion, often converges to suboptimal local minima. To address these issues, we propose an unsupervised framework that jointly optimizes egomotion and optical flow via implicit spatial-temporal and geometric regularization. First, by modeling camera's egomotion as a continuous spline and optical flow as an implicit neural representation, our method inherently embeds spatial-temporal coherence through inductive biases. Second, we incorporate structure-and-motion priors through differential geometric constraints, bypassing explicit depth estimation while maintaining rigorous geometric consistency. As a result, our framework (called E-MoFlow) unifies egomotion and optical flow estimation via implicit regularization under a fully unsupervised paradigm. Experiments demonstrate its versatility to general 6-DoF motion scenarios, achieving state-of-the-art performance among unsupervised methods and competitive even with supervised approaches.
Learning to Decide with Just Enough: Information-Theoretic Context Summarization for CDMPs
Oct 02, 2025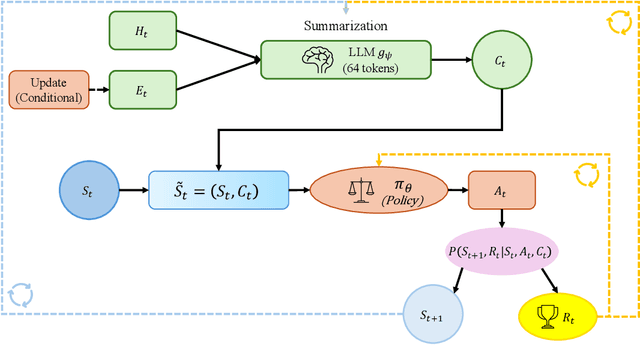

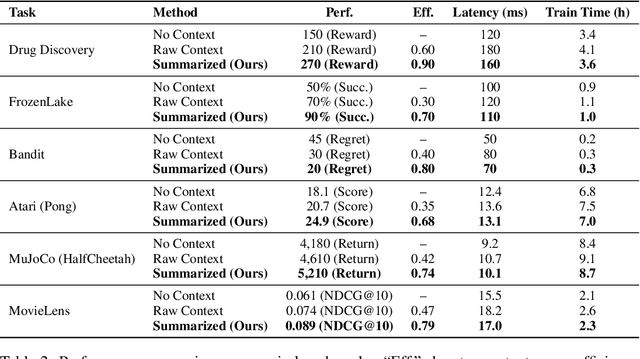
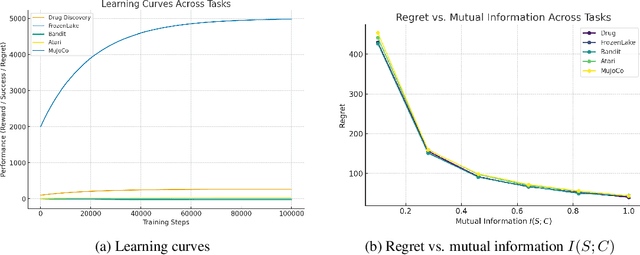
Contextual Markov Decision Processes (CMDPs) offer a framework for sequential decision-making under external signals, but existing methods often fail to generalize in high-dimensional or unstructured contexts, resulting in excessive computation and unstable performance. We propose an information-theoretic summarization approach that uses large language models (LLMs) to compress contextual inputs into low-dimensional, semantically rich summaries. These summaries augment states by preserving decision-critical cues while reducing redundancy. Building on the notion of approximate context sufficiency, we provide, to our knowledge, the first regret bounds and a latency-entropy trade-off characterization for CMDPs. Our analysis clarifies how informativeness impacts computational cost. Experiments across discrete, continuous, visual, and recommendation benchmarks show that our method outperforms raw-context and non-context baselines, improving reward, success rate, and sample efficiency, while reducing latency and memory usage. These findings demonstrate that LLM-based summarization offers a scalable and interpretable solution for efficient decision-making in context-rich, resource-constrained environments.
SIU3R: Simultaneous Scene Understanding and 3D Reconstruction Beyond Feature Alignment
Jul 03, 2025Simultaneous understanding and 3D reconstruction plays an important role in developing end-to-end embodied intelligent systems. To achieve this, recent approaches resort to 2D-to-3D feature alignment paradigm, which leads to limited 3D understanding capability and potential semantic information loss. In light of this, we propose SIU3R, the first alignment-free framework for generalizable simultaneous understanding and 3D reconstruction from unposed images. Specifically, SIU3R bridges reconstruction and understanding tasks via pixel-aligned 3D representation, and unifies multiple understanding tasks into a set of unified learnable queries, enabling native 3D understanding without the need of alignment with 2D models. To encourage collaboration between the two tasks with shared representation, we further conduct in-depth analyses of their mutual benefits, and propose two lightweight modules to facilitate their interaction. Extensive experiments demonstrate that our method achieves state-of-the-art performance not only on the individual tasks of 3D reconstruction and understanding, but also on the task of simultaneous understanding and 3D reconstruction, highlighting the advantages of our alignment-free framework and the effectiveness of the mutual benefit designs.
EvDetMAV: Generalized MAV Detection from Moving Event Cameras
Jun 24, 2025



Existing micro aerial vehicle (MAV) detection methods mainly rely on the target's appearance features in RGB images, whose diversity makes it difficult to achieve generalized MAV detection. We notice that different types of MAVs share the same distinctive features in event streams due to their high-speed rotating propellers, which are hard to see in RGB images. This paper studies how to detect different types of MAVs from an event camera by fully exploiting the features of propellers in the original event stream. The proposed method consists of three modules to extract the salient and spatio-temporal features of the propellers while filtering out noise from background objects and camera motion. Since there are no existing event-based MAV datasets, we introduce a novel MAV dataset for the community. This is the first event-based MAV dataset comprising multiple scenarios and different types of MAVs. Without training, our method significantly outperforms state-of-the-art methods and can deal with challenging scenarios, achieving a precision rate of 83.0\% (+30.3\%) and a recall rate of 81.5\% (+36.4\%) on the proposed testing dataset. The dataset and code are available at: https://github.com/WindyLab/EvDetMAV.
Styl3R: Instant 3D Stylized Reconstruction for Arbitrary Scenes and Styles
May 27, 2025Stylizing 3D scenes instantly while maintaining multi-view consistency and faithfully resembling a style image remains a significant challenge. Current state-of-the-art 3D stylization methods typically involve computationally intensive test-time optimization to transfer artistic features into a pretrained 3D representation, often requiring dense posed input images. In contrast, leveraging recent advances in feed-forward reconstruction models, we demonstrate a novel approach to achieve direct 3D stylization in less than a second using unposed sparse-view scene images and an arbitrary style image. To address the inherent decoupling between reconstruction and stylization, we introduce a branched architecture that separates structure modeling and appearance shading, effectively preventing stylistic transfer from distorting the underlying 3D scene structure. Furthermore, we adapt an identity loss to facilitate pre-training our stylization model through the novel view synthesis task. This strategy also allows our model to retain its original reconstruction capabilities while being fine-tuned for stylization. Comprehensive evaluations, using both in-domain and out-of-domain datasets, demonstrate that our approach produces high-quality stylized 3D content that achieve a superior blend of style and scene appearance, while also outperforming existing methods in terms of multi-view consistency and efficiency.