 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIU3R: Simultaneous Scene Understanding and 3D Reconstruction Beyond Feature Alignment
Jul 03, 2025Simultaneous understanding and 3D reconstruction plays an important role in developing end-to-end embodied intelligent systems. To achieve this, recent approaches resort to 2D-to-3D feature alignment paradigm, which leads to limited 3D understanding capability and potential semantic information loss. In light of this, we propose SIU3R, the first alignment-free framework for generalizable simultaneous understanding and 3D reconstruction from unposed images. Specifically, SIU3R bridges reconstruction and understanding tasks via pixel-aligned 3D representation, and unifies multiple understanding tasks into a set of unified learnable queries, enabling native 3D understanding without the need of alignment with 2D models. To encourage collaboration between the two tasks with shared representation, we further conduct in-depth analyses of their mutual benefits, and propose two lightweight modules to facilitate their interaction. Extensive experiments demonstrate that our method achieves state-of-the-art performance not only on the individual tasks of 3D reconstruction and understanding, but also on the task of simultaneous understanding and 3D reconstruction, highlighting the advantages of our alignment-free framework and the effectiveness of the mutual benefit designs.
CasualHDRSplat: Robust High Dynamic Range 3D Gaussian Splatting from Casually Captured Videos
Apr 24, 2025



Recently, photo-realistic novel view synthesis from multi-view images, such as neural radiance field (NeRF) and 3D Gaussian Splatting (3DGS), have garnered widespread attention due to their superior performance. However, most works rely on low dynamic range (LDR) images, which limits the capturing of richer scene details. Some prior works have focused on high dynamic range (HDR) scene reconstruction, typically require capturing of multi-view sharp images with different exposure times at fixed camera positions during exposure times, which is time-consuming and challenging in practice. For a more flexible data acquisition, we propose a one-stage method: \textbf{CasualHDRSplat} to easily and robustly reconstruct the 3D HDR scene from casually captured videos with auto-exposure enabled, even in the presence of severe motion blur and varying unknown exposure time. \textbf{CasualHDRSplat} contains a unified differentiable physical imaging model which first applies continuous-time trajectory constraint to imaging process so that we can jointly optimize exposure time, camera response function (CRF), camera poses, and sharp 3D HDR scene. Extensive experiments demonstrate that our approach outperforms existing methods in terms of robustness and rendering quality. Our source code will be available at https://github.com/WU-CVGL/CasualHDRSplat
MBA-SLAM: Motion Blur Aware Dense Visual SLAM with Radiance Fields Representation
Nov 13, 2024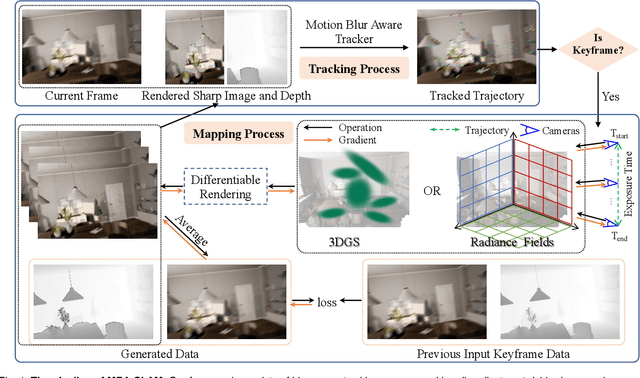
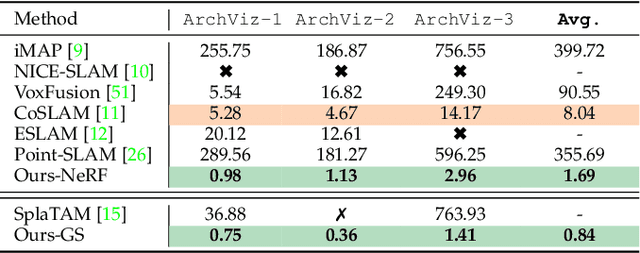

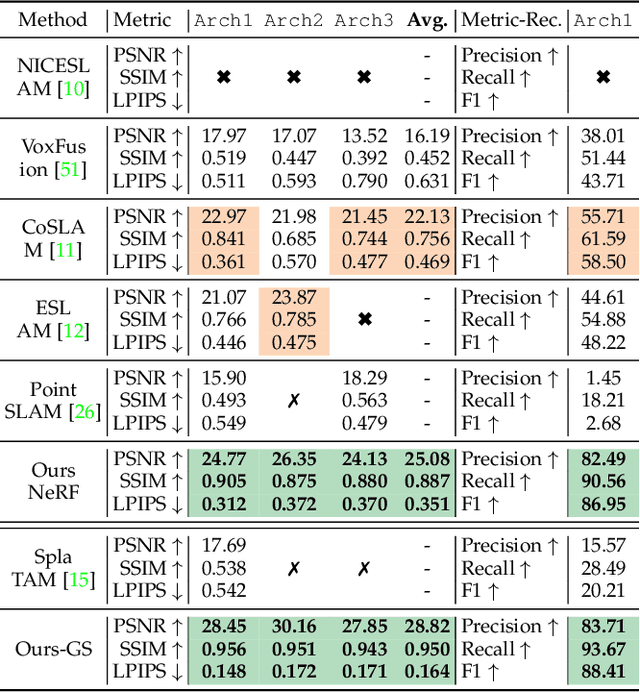
Emerging 3D scene representations, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have demonstrated their effectiveness in Simultaneous Localization and Mapping (SLAM) for photo-realistic rendering, particularly when using high-quality video sequences as input. However, existing methods struggle with motion-blurred frames, which are common in real-world scenarios like low-light or long-exposure conditions. This often results in a significant reduction in both camera localization accuracy and map reconstruction quality. To address this challenge, we propose a dense visual SLAM pipeline (i.e. MBA-SLAM) to handle severe motion-blurred inputs. Our approach integrates an efficient motion blur-aware tracker with either neural radiance fields or Gaussian Splatting based mapper. By accurately modeling the physical image formation process of motion-blurred images, our method simultaneously learns 3D scene representation and estimates the cameras' local trajectory during exposure time, enabling proactive compensation for motion blur caused by camera movement. In our experiments, we demonstrate that MBA-SLAM surpasses previous state-of-the-art methods in both camera localization and map reconstruction, showcasing superior performance across a range of datasets, including synthetic and real datasets featuring sharp images as well as those affected by motion blur, highlighting the versatility and robustness of our approach. Code is available at https://github.com/WU-CVGL/MBA-SLAM.
DerainNeRF: 3D Scene Estimation with Adhesive Waterdrop Removal
Mar 29, 2024When capturing images through the glass during rainy or snowy weather conditions, the resulting images often contain waterdrops adhered on the glass surface, and these waterdrops significantly degrade the image quality and performance of many computer vision algorithms. To tackle these limitations, we propose a method to reconstruct the clear 3D scene implicitly from multi-view images degraded by waterdrops. Our method exploits an attention network to predict the location of waterdrops and then train a Neural Radiance Fields to recover the 3D scene implicitly. By leveraging the strong scene representation capabilities of NeRF, our method can render high-quality novel-view images with waterdrops removed. Extensive experimental results on both synthetic and real datasets show that our method is able to generate clear 3D scenes and outperforms existing state-of-the-art (SOTA) image adhesive waterdrop removal methods.
BAD-Gaussians: Bundle Adjusted Deblur Gaussian Splatting
Mar 19, 2024While neural rendering has demonstrated impressive capabilities in 3D scene reconstruction and novel view synthesis, it heavily relies on high-quality sharp images and accurate camera poses. Numerous approaches have been proposed to train Neural Radiance Fields (NeRF) with motion-blurred images, commonly encountered in real-world scenarios such as low-light or long-exposure conditions. However, the implicit representation of NeRF struggles to accurately recover intricate details from severely motion-blurred images and cannot achieve real-time rendering. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction and real-time rendering by explicitly optimizing point clouds as Gaussian spheres. In this paper, we introduce a novel approach, named BAD-Gaussians (Bundle Adjusted Deblur Gaussian Splatting), which leverages explicit Gaussian representation and handles severe motion-blurred images with inaccurate camera poses to achieve high-quality scene reconstruction. Our method models the physical image formation process of motion-blurred images and jointly learns the parameters of Gaussians while recovering camera motion trajectories during exposure time. In our experiments, we demonstrate that BAD-Gaussians not only achieves superior rendering quality compared to previous state-of-the-art deblur neural rendering methods on both synthetic and real datasets but also enables real-time rendering capabilities. Our project page and source code is available at https://lingzhezhao.github.io/BAD-Gaussians/
Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
Mar 19, 2024While text-to-3D and image-to-3D generation tasks have received considerable attention, one important but under-explored field between them is controllable text-to-3D generation, which we mainly focus on in this work. To address this task, 1) we introduce Multi-view ControlNet (MVControl), a novel neural network architecture designed to enhance existing pre-trained multi-view diffusion models by integrating additional input conditions, such as edge, depth, normal, and scribble maps. Our innovation lies in the introduction of a conditioning module that controls the base diffusion model using both local and global embeddings, which are computed from the input condition images and camera poses. Once trained, MVControl is able to offer 3D diffusion guidance for optimization-based 3D generation. And, 2) we propose an efficient multi-stage 3D generation pipeline that leverages the benefits of recent large reconstruction models and score distillation algorithm. Building upon our MVControl architecture, we employ a unique hybrid diffusion guidance method to direct the optimization process. In pursuit of efficiency, we adopt 3D Gaussians as our representation instead of the commonly used implicit representations. We also pioneer the use of SuGaR, a hybrid representation that binds Gaussians to mesh triangle faces. This approach alleviates the issue of poor geometry in 3D Gaussians and enables the direct sculpting of fine-grained geometry on the mesh. Extensive experiments demonstrate that our method achieves robust generalization and enables the controllable generation of high-quality 3D content.
MVControl: Adding Conditional Control to Multi-view Diffusion for Controllable Text-to-3D Generation
Nov 27, 2023We introduce MVControl, a novel neural network architecture that enhances existing pre-trained multi-view 2D diffusion models by incorporating additional input conditions, e.g. edge maps. Our approach enables the generation of controllable multi-view images and view-consistent 3D content. To achieve controllable multi-view image generation, we leverage MVDream as our base model, and train a new neural network module as additional plugin for end-to-end task-specific condition learning. To precisely control the shapes and views of generated images, we innovatively propose a new conditioning mechanism that predicts an embedding encapsulating the input spatial and view conditions, which is then injected to the network globally. Once MVControl is trained, score-distillation (SDS) loss based optimization can be performed to generate 3D content, in which process we propose to use a hybrid diffusion prior. The hybrid prior relies on a pre-trained Stable-Diffusion network and our trained MVControl for additional guidance. Extensive experiments demonstrate that our method achieves robust generalization and enables the controllable generation of high-quality 3D content. Code available at https://github.com/WU-CVGL/MVControl/.
USB-NeRF: Unrolling Shutter Bundle Adjusted Neural Radiance Fields
Oct 05, 2023


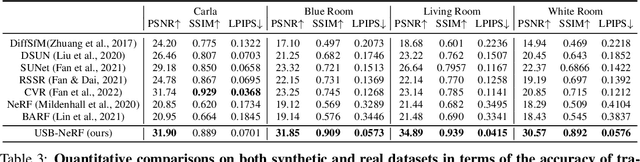
Neural Radiance Fields (NeRF) has received much attention recently due to its impressive capability to represent 3D scene and synthesize novel view images. Existing works usually assume that the input images are captured by a global shutter camera. Thus, rolling shutter (RS) images cannot be trivially applied to an off-the-shelf NeRF algorithm for novel view synthesis. Rolling shutter effect would also affect the accuracy of the camera pose estimation (e.g. via COLMAP), which further prevents the success of NeRF algorithm with RS images. In this paper, we propose Unrolling Shutter Bundle Adjusted Neural Radiance Fields (USB-NeRF). USB-NeRF is able to correct rolling shutter distortions and recover accurate camera motion trajectory simultaneously under the framework of NeRF, by modeling the physical image formation process of a RS camera. Experimental results demonstrate that USB-NeRF achieves better performance compared to prior works, in terms of RS effect removal, novel view image synthesis as well as camera motion estimation. Furthermore, our algorithm can also be used to recover high-fidelity high frame-rate global shutter video from a sequence of RS images.
BAD-NeRF: Bundle Adjusted Deblur Neural Radiance Fields
Nov 23, 2022
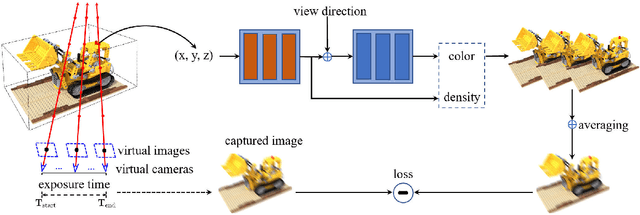


Neural Radiance Fields (NeRF) have received considerable attention recently, due to its impressive capability in photo-realistic 3D reconstruction and novel view synthesis, given a set of posed camera images. Earlier work usually assumes the input images are in good quality. However, image degradation (e.g. image motion blur in low-light conditions) can easily happen in real-world scenarios, which would further affect the rendering quality of NeRF. In this paper, we present a novel bundle adjusted deblur Neural Radiance Fields (BAD-NeRF), which can be robust to severe motion blurred images and inaccurate camera poses. Our approach models the physical image formation process of a motion blurred image, and jointly learns the parameters of NeRF and recovers the camera motion trajectories during exposure time. In experiments, we show that by directly modeling the real physical image formation process, BAD-NeRF achieves superior performance over prior works on both synthetic and real datasets.
Automated Essay Scoring based on Two-Stage Learning
Jan 23, 2019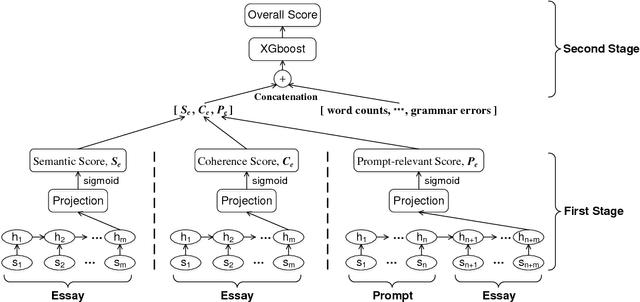
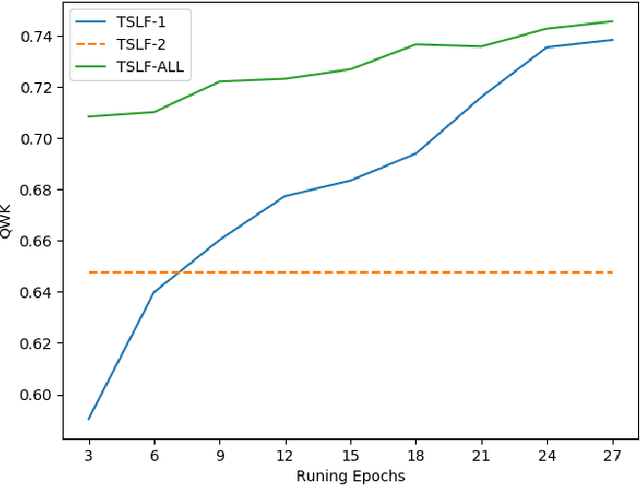
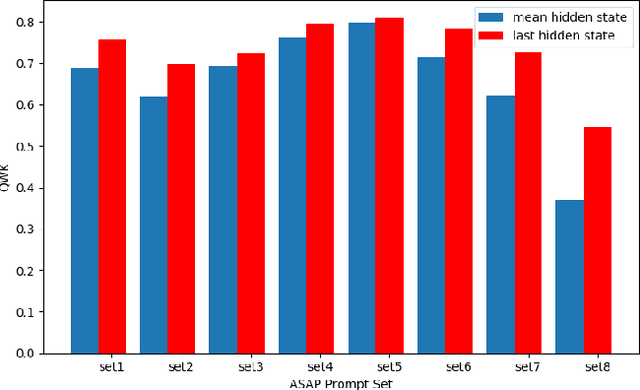
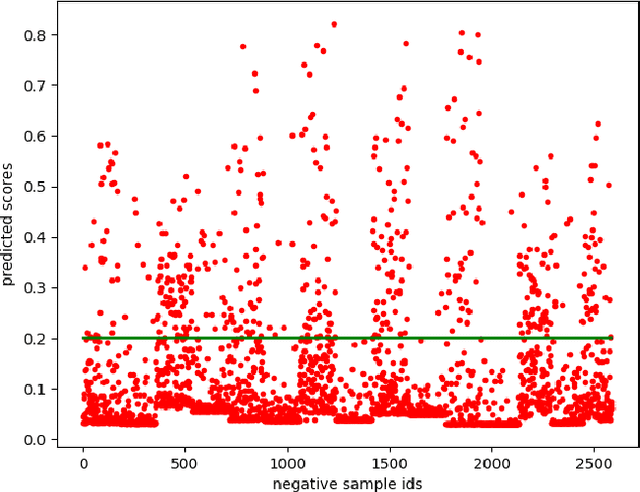
Current state-of-art feature-engineered and end-to-end Automated Essay Score (AES) methods are proven to be unable to detect adversarial samples, e.g. the essays composed of permuted sentences and the prompt-irrelevant essays. Focusing on the problem, we develop a Two-Stage Learning Framework (TSLF) which integrates the advantages of both feature-engineered and end-to-end AES models. In experiments, we compare TSLF against a number of strong baselines, and the results demonstrate the effectiveness and robustness of our models. TSLF surpasses all the baselines on five-eighths of prompts and achieves new state-of-the-art average performance when without negative samples. After adding some adversarial essays to the original datasets, TSLF outperforms the feature-engineered and end-to-end baselines to a great extent, and shows great robustness.