 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoAesBench: Benchmarking the Video Aesthetics Perception Capabilities of Large Multimodal Models
Jan 29, 2026Large multimodal models (LMMs) have demonstrated outstanding capabilities in various visual perception tasks, which has in turn made the evaluation of LMMs significant. However, the capability of video aesthetic quality assessment, which is a fundamental ability for human, remains underexplored for LMMs. To address this, we introduce VideoAesBench, a comprehensive benchmark for evaluating LMMs' understanding of video aesthetic quality. VideoAesBench has several significant characteristics: (1) Diverse content including 1,804 videos from multiple video sources including user-generated (UGC), AI-generated (AIGC), compressed, robotic-generated (RGC), and game videos. (2) Multiple question formats containing traditional single-choice questions, multi-choice questions, True or False questions, and a novel open-ended questions for video aesthetics description. (3) Holistic video aesthetics dimensions including visual form related questions from 5 aspects, visual style related questions from 4 aspects, and visual affectiveness questions from 3 aspects. Based on VideoAesBench, we benchmark 23 open-source and commercial large multimodal models. Our findings show that current LMMs only contain basic video aesthetics perception ability, their performance remains incomplete and imprecise. We hope our VideoAesBench can be served as a strong testbed and offer insights for explainable video aesthetics assessment.
Q-Bench-Portrait: Benchmarking Multimodal Large Language Models on Portrait Image Quality Perception
Jan 26, 2026Recent advances in multimodal large language models (MLLMs) have demonstrated impressive performance on existing low-level vision benchmarks, which primarily focus on generic images. However, their capabilities to perceive and assess portrait images, a domain characterized by distinct structural and perceptual properties, remain largely underexplored. To this end, we introduce Q-Bench-Portrait, the first holistic benchmark specifically designed for portrait image quality perception, comprising 2,765 image-question-answer triplets and featuring (1) diverse portrait image sources, including natural, synthetic distortion, AI-generated, artistic, and computer graphics images; (2) comprehensive quality dimensions, covering technical distortions, AIGC-specific distortions, and aesthetics; and (3) a range of question formats, including single-choice, multiple-choice, true/false, and open-ended questions, at both global and local levels. Based on Q-Bench-Portrait, we evaluate 20 open-source and 5 closed-source MLLMs, revealing that although current models demonstrate some competence in portrait image perception, their performance remains limited and imprecise, with a clear gap relative to human judgments. We hope that the proposed benchmark will foster further research into enhancing the portrait image perception capabilities of both general-purpose and domain-specific MLLMs.
VTONQA: A Multi-Dimensional Quality Assessment Dataset for Virtual Try-on
Jan 06, 2026With the rapid development of e-commerce and digital fashion, image-based virtual try-on (VTON) has attracted increasing attention. However, existing VTON models often suffer from artifacts such as garment distortion and body inconsistency, highlighting the need for reliable quality evaluation of VTON-generated images. To this end, we construct VTONQA, the first multi-dimensional quality assessment dataset specifically designed for VTON, which contains 8,132 images generated by 11 representative VTON models, along with 24,396 mean opinion scores (MOSs) across three evaluation dimensions (i.e., clothing fit, body compatibility, and overall quality). Based on VTONQA, we benchmark both VTON models and a diverse set of image quality assessment (IQA) metrics, revealing the limitations of existing methods and highlighting the value of the proposed dataset. We believe that the VTONQA dataset and corresponding benchmarks will provide a solid foundation for perceptually aligned evaluation, benefiting both the development of quality assessment methods and the advancement of VTON models.
UniAct: Unified Motion Generation and Action Streaming for Humanoid Robots
Dec 30, 2025A long-standing objective in humanoid robotics is the realization of versatile agents capable of following diverse multimodal instructions with human-level flexibility. Despite advances in humanoid control, bridging high-level multimodal perception with whole-body execution remains a significant bottleneck. Existing methods often struggle to translate heterogeneous instructions -- such as language, music, and trajectories -- into stable, real-time actions. Here we show that UniAct, a two-stage framework integrating a fine-tuned MLLM with a causal streaming pipeline, enables humanoid robots to execute multimodal instructions with sub-500 ms latency. By unifying inputs through a shared discrete codebook via FSQ, UniAct ensures cross-modal alignment while constraining motions to a physically grounded manifold. This approach yields a 19% improvement in the success rate of zero-shot tracking of imperfect reference motions. We validate UniAct on UniMoCap, our 20-hour humanoid motion benchmark, demonstrating robust generalization across diverse real-world scenarios. Our results mark a critical step toward responsive, general-purpose humanoid assistants capable of seamless interaction through unified perception and control.
DiffVL: Diffusion-Based Visual Localization on 2D Maps via BEV-Conditioned GPS Denoising
Sep 18, 2025



Accurate visual localization is crucial for autonomous driving, yet existing methods face a fundamental dilemma: While high-definition (HD) maps provide high-precision localization references, their costly construction and maintenance hinder scalability, which drives research toward standard-definition (SD) maps like OpenStreetMap. Current SD-map-based approaches primarily focus on Bird's-Eye View (BEV) matching between images and maps, overlooking a ubiquitous signal-noisy GPS. Although GPS is readily available, it suffers from multipath errors in urban environments. We propose DiffVL, the first framework to reformulate visual localization as a GPS denoising task using diffusion models. Our key insight is that noisy GPS trajectory, when conditioned on visual BEV features and SD maps, implicitly encode the true pose distribution, which can be recovered through iterative diffusion refinement. DiffVL, unlike prior BEV-matching methods (e.g., OrienterNet) or transformer-based registration approaches, learns to reverse GPS noise perturbations by jointly modeling GPS, SD map, and visual signals, achieving sub-meter accuracy without relying on HD maps. Experiments on multiple datasets demonstrate that our method achieves state-of-the-art accuracy compared to BEV-matching baselines. Crucially, our work proves that diffusion models can enable scalable localization by treating noisy GPS as a generative prior-making a paradigm shift from traditional matching-based methods.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
AGHI-QA: A Subjective-Aligned Dataset and Metric for AI-Generated Human Images
Apr 30, 2025



The rapid development of text-to-image (T2I) generation approaches has attracted extensive interest in evaluating the quality of generated images, leading to the development of various quality assessment methods for general-purpose T2I outputs. However, existing image quality assessment (IQA) methods are limited to providing global quality scores, failing to deliver fine-grained perceptual evaluations for structurally complex subjects like humans, which is a critical challenge considering the frequent anatomical and textural distortions in AI-generated human images (AGHIs). To address this gap, we introduce AGHI-QA, the first large-scale benchmark specifically designed for quality assessment of AGHIs. The dataset comprises 4,000 images generated from 400 carefully crafted text prompts using 10 state of-the-art T2I models. We conduct a systematic subjective study to collect multidimensional annotations, including perceptual quality scores, text-image correspondence scores, visible and distorted body part labels. Based on AGHI-QA, we evaluate the strengths and weaknesses of current T2I methods in generating human images from multiple dimensions. Furthermore, we propose AGHI-Assessor, a novel quality metric that integrates the large multimodal model (LMM) with domain-specific human features for precise quality prediction and identification of visible and distorted body parts in AGHIs. Extensive experimental results demonstrate that AGHI-Assessor showcases state-of-the-art performance, significantly outperforming existing IQA methods in multidimensional quality assessment and surpassing leading LMMs in detecting structural distortions in AGHIs.
FVQ: A Large-Scale Dataset and A LMM-based Method for Face Video Quality Assessment
Apr 12, 2025



Face video quality assessment (FVQA) deserves to be explored in addition to general video quality assessment (VQA), as face videos are the primary content on social media platforms and human visual system (HVS) is particularly sensitive to human faces. However, FVQA is rarely explored due to the lack of large-scale FVQA datasets. To fill this gap, we present the first large-scale in-the-wild FVQA dataset, FVQ-20K, which contains 20,000 in-the-wild face videos together with corresponding mean opinion score (MOS) annotations. Along with the FVQ-20K dataset, we further propose a specialized FVQA method named FVQ-Rater to achieve human-like rating and scoring for face video, which is the first attempt to explore the potential of large multimodal models (LMMs) for the FVQA task. Concretely, we elaborately extract multi-dimensional features including spatial features, temporal features, and face-specific features (i.e., portrait features and face embeddings) to provide comprehensive visual information, and take advantage of the LoRA-based instruction tuning technique to achieve quality-specific fine-tuning, which shows superior performance on both FVQ-20K and CFVQA datasets. Extensive experiments and comprehensive analysis demonstrate the significant potential of the FVQ-20K dataset and FVQ-Rater method in promoting the development of FVQA.
Attention to Trajectory: Trajectory-Aware Open-Vocabulary Tracking
Mar 11, 2025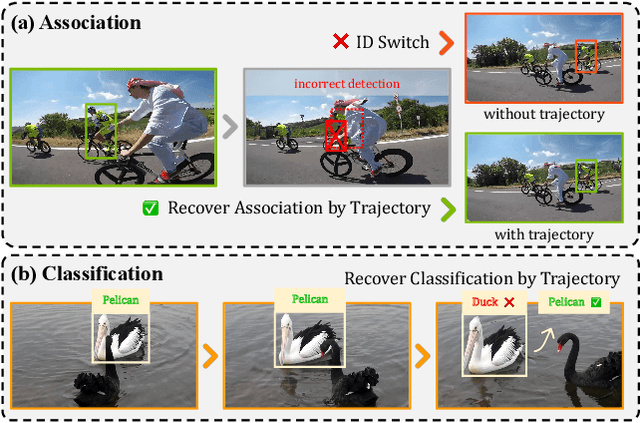


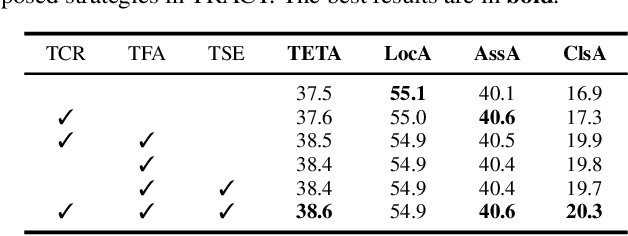
Open-Vocabulary Multi-Object Tracking (OV-MOT) aims to enable approaches to track objects without being limited to a predefined set of categories. Current OV-MOT methods typically rely primarily on instance-level detection and association, often overlooking trajectory information that is unique and essential for object tracking tasks. Utilizing trajectory information can enhance association stability and classification accuracy, especially in cases of occlusion and category ambiguity, thereby improving adaptability to novel classes. Thus motivated, in this paper we propose \textbf{TRACT}, an open-vocabulary tracker that leverages trajectory information to improve both object association and classification in OV-MOT. Specifically, we introduce a \textit{Trajectory Consistency Reinforcement} (\textbf{TCR}) strategy, that benefits tracking performance by improving target identity and category consistency. In addition, we present \textbf{TraCLIP}, a plug-and-play trajectory classification module. It integrates \textit{Trajectory Feature Aggregation} (\textbf{TFA}) and \textit{Trajectory Semantic Enrichment} (\textbf{TSE}) strategies to fully leverage trajectory information from visual and language perspectives for enhancing the classification results. Extensive experiments on OV-TAO show that our TRACT significantly improves tracking performance, highlighting trajectory information as a valuable asset for OV-MOT. Code will be released.
Learning Radiance Fields from a Single Snapshot Compressive Image
Dec 27, 2024In this paper, we explore the potential of Snapshot Compressive Imaging (SCI) technique for recovering the underlying 3D scene structure from a single temporal compressed image. SCI is a cost-effective method that enables the recording of high-dimensional data, such as hyperspectral or temporal information, into a single image using low-cost 2D imaging sensors. To achieve this, a series of specially designed 2D masks are usually employed, reducing storage and transmission requirements and offering potential privacy protection. Inspired by this, we take one step further to recover the encoded 3D scene information leveraging powerful 3D scene representation capabilities of neural radiance fields (NeRF). Specifically, we propose SCINeRF, in which we formulate the physical imaging process of SCI as part of the training of NeRF, allowing us to exploit its impressive performance in capturing complex scene structures. In addition, we further integrate the popular 3D Gaussian Splatting (3DGS) framework and propose SCISplat to improve 3D scene reconstruction quality and training/rendering speed by explicitly optimizing point clouds into 3D Gaussian representations. To assess the effectiveness of our method, we conduct extensive evaluations using both synthetic data and real data captured by our SCI system. Experimental results demonstrate that our proposed approach surpasses the state-of-the-art methods in terms of image reconstruction and novel view synthesis. Moreover, our method also exhibits the ability to render high frame-rate multi-view consistent images in real time by leveraging SCI and the rendering capabilities of 3DGS. Codes will be available at: https://github.com/WU- CVGL/SCISplat.