 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Agent: Optimizing Planning Capability for Multimodal Retrieval Augmented Generation
Aug 12, 2025Multimodal Retrieval-Augmented Generation (mRAG) has emerged as a promising solution to address the temporal limitations of Multimodal Large Language Models (MLLMs) in real-world scenarios like news analysis and trending topics. However, existing approaches often suffer from rigid retrieval strategies and under-utilization of visual information. To bridge this gap, we propose E-Agent, an agent framework featuring two key innovations: a mRAG planner trained to dynamically orchestrate multimodal tools based on contextual reasoning, and a task executor employing tool-aware execution sequencing to implement optimized mRAG workflows. E-Agent adopts a one-time mRAG planning strategy that enables efficient information retrieval while minimizing redundant tool invocations. To rigorously assess the planning capabilities of mRAG systems, we introduce the Real-World mRAG Planning (RemPlan) benchmark. This novel benchmark contains both retrieval-dependent and retrieval-independent question types, systematically annotated with essential retrieval tools required for each instance. The benchmark's explicit mRAG planning annotations and diverse question design enhance its practical relevance by simulating real-world scenarios requiring dynamic mRAG decisions. Experiments across RemPlan and three established benchmarks demonstrate E-Agent's superiority: 13% accuracy gain over state-of-the-art mRAG methods while reducing redundant searches by 37%.
Comet: Accelerating Private Inference for Large Language Model by Predicting Activation Sparsity
May 12, 2025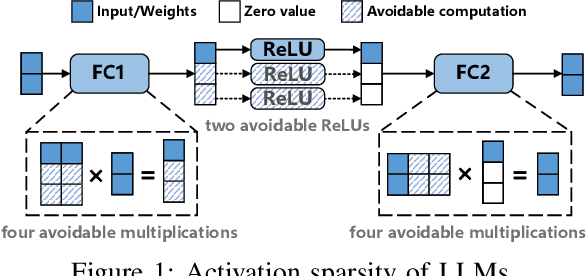
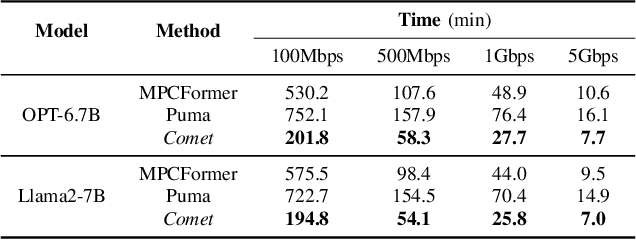
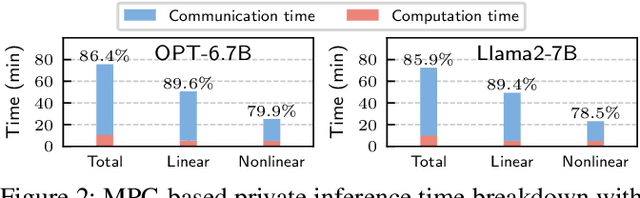
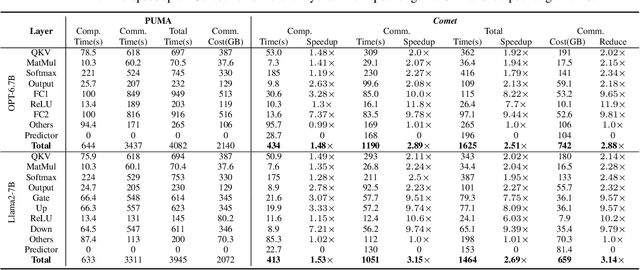
With the growing use of large language models (LLMs) hosted on cloud platforms to offer inference services, privacy concerns about the potential leakage of sensitive information are escalating. Secure multi-party computation (MPC) is a promising solution to protect the privacy in LLM inference. However, MPC requires frequent inter-server communication, causing high performance overhead. Inspired by the prevalent activation sparsity of LLMs, where most neuron are not activated after non-linear activation functions, we propose an efficient private inference system, Comet. This system employs an accurate and fast predictor to predict the sparsity distribution of activation function output. Additionally, we introduce a new private inference protocol. It efficiently and securely avoids computations involving zero values by exploiting the spatial locality of the predicted sparse distribution. While this computation-avoidance approach impacts the spatiotemporal continuity of KV cache entries, we address this challenge with a low-communication overhead cache refilling strategy that merges miss requests and incorporates a prefetching mechanism. Finally, we evaluate Comet on four common LLMs and compare it with six state-of-the-art private inference systems. Comet achieves a 1.87x-2.63x speedup and a 1.94x-2.64x communication reduction.
Attention to Trajectory: Trajectory-Aware Open-Vocabulary Tracking
Mar 11, 2025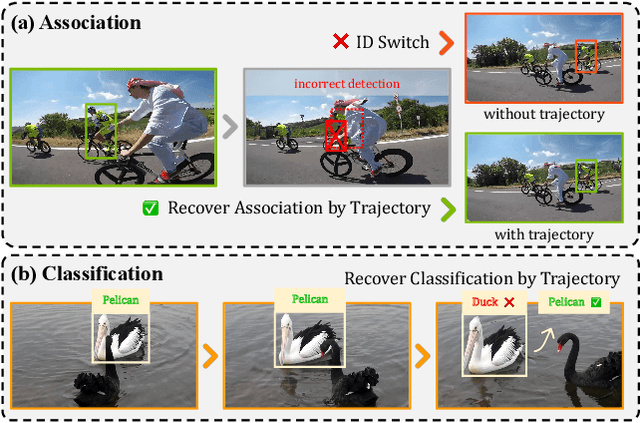


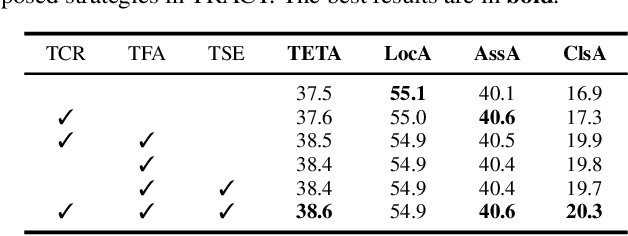
Open-Vocabulary Multi-Object Tracking (OV-MOT) aims to enable approaches to track objects without being limited to a predefined set of categories. Current OV-MOT methods typically rely primarily on instance-level detection and association, often overlooking trajectory information that is unique and essential for object tracking tasks. Utilizing trajectory information can enhance association stability and classification accuracy, especially in cases of occlusion and category ambiguity, thereby improving adaptability to novel classes. Thus motivated, in this paper we propose \textbf{TRACT}, an open-vocabulary tracker that leverages trajectory information to improve both object association and classification in OV-MOT. Specifically, we introduce a \textit{Trajectory Consistency Reinforcement} (\textbf{TCR}) strategy, that benefits tracking performance by improving target identity and category consistency. In addition, we present \textbf{TraCLIP}, a plug-and-play trajectory classification module. It integrates \textit{Trajectory Feature Aggregation} (\textbf{TFA}) and \textit{Trajectory Semantic Enrichment} (\textbf{TSE}) strategies to fully leverage trajectory information from visual and language perspectives for enhancing the classification results. Extensive experiments on OV-TAO show that our TRACT significantly improves tracking performance, highlighting trajectory information as a valuable asset for OV-MOT. Code will be released.
LoopAnimate: Loopable Salient Object Animation
Apr 14, 2024Research on diffusion model-based video generation has advanced rapidly. However, limitations in object fidelity and generation length hinder its practical applications. Additionally, specific domains like animated wallpapers require seamless looping, where the first and last frames of the video match seamlessly. To address these challenges, this paper proposes LoopAnimate, a novel method for generating videos with consistent start and end frames. To enhance object fidelity, we introduce a framework that decouples multi-level image appearance and textual semantic information. Building upon an image-to-image diffusion model, our approach incorporates both pixel-level and feature-level information from the input image, injecting image appearance and textual semantic embeddings at different positions of the diffusion model. Existing UNet-based video generation models require to input the entire videos during training to encode temporal and positional information at once. However, due to limitations in GPU memory, the number of frames is typically restricted to 16. To address this, this paper proposes a three-stage training strategy with progressively increasing frame numbers and reducing fine-tuning modules. Additionally, we introduce the Temporal E nhanced Motion Module(TEMM) to extend the capacity for encoding temporal and positional information up to 36 frames. The proposed LoopAnimate, which for the first time extends the single-pass generation length of UNet-based video generation models to 35 frames while maintaining high-quality video generation. Experiments demonstrate that LoopAnimate achieves state-of-the-art performance in both objective metrics, such as fidelity and temporal consistency, and subjective evaluation results.
Post-Training Attribute Unlearning in Recommender Systems
Mar 11, 2024



With the growing privacy concerns in recommender systems, recommendation unlearning is getting increasing attention. Existing studies predominantly use training data, i.e., model inputs, as unlearning target. However, attackers can extract private information from the model even if it has not been explicitly encountered during training. We name this unseen information as \textit{attribute} and treat it as unlearning target. To protect the sensitive attribute of users, Attribute Unlearning (AU) aims to make target attributes indistinguishable. In this paper, we focus on a strict but practical setting of AU, namely Post-Training Attribute Unlearning (PoT-AU), where unlearning can only be performed after the training of the recommendation model is completed. To address the PoT-AU problem in recommender systems, we propose a two-component loss function. The first component is distinguishability loss, where we design a distribution-based measurement to make attribute labels indistinguishable from attackers. We further extend this measurement to handle multi-class attribute cases with efficient computational overhead. The second component is regularization loss, where we explore a function-space measurement that effectively maintains recommendation performance compared to parameter-space regularization. We use stochastic gradient descent algorithm to optimize our proposed loss. Extensive experiments on four real-world datasets demonstrate the effectiveness of our proposed methods.
A Comprehensive Survey on Process-Oriented Automatic Text Summarization with Exploration of LLM-Based Methods
Mar 05, 2024
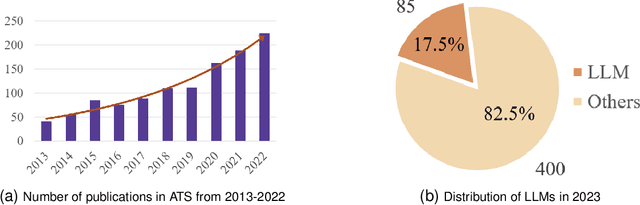
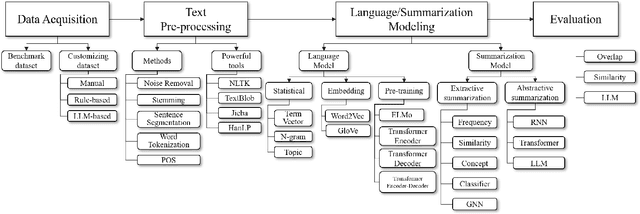
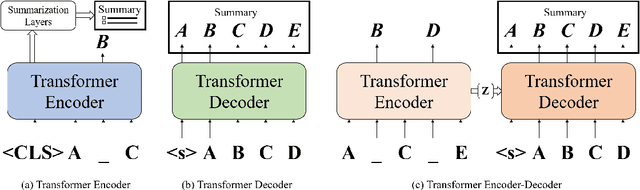
Automatic Text Summarization (ATS), utilizing Natural Language Processing (NLP) algorithms, aims to create concise and accurate summaries, thereby significantly reducing the human effort required in processing large volumes of text. ATS has drawn considerable interest in both academic and industrial circles. Many studies have been conducted in the past to survey ATS methods; however, they generally lack practicality for real-world implementations, as they often categorize previous methods from a theoretical standpoint. Moreover, the advent of Large Language Models (LLMs) has altered conventional ATS methods. In this survey, we aim to 1) provide a comprehensive overview of ATS from a ``Process-Oriented Schema'' perspective, which is best aligned with real-world implementations; 2) comprehensively review the latest LLM-based ATS works; and 3) deliver an up-to-date survey of ATS, bridging the two-year gap in the literature. To the best of our knowledge, this is the first survey to specifically investigate LLM-based ATS methods.
Making Users Indistinguishable: Attribute-wise Unlearning in Recommender Systems
Oct 06, 2023
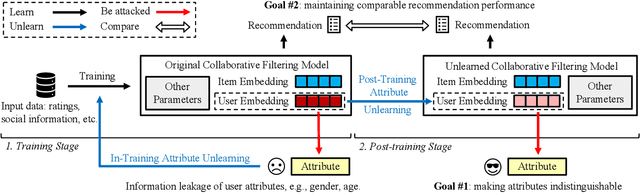
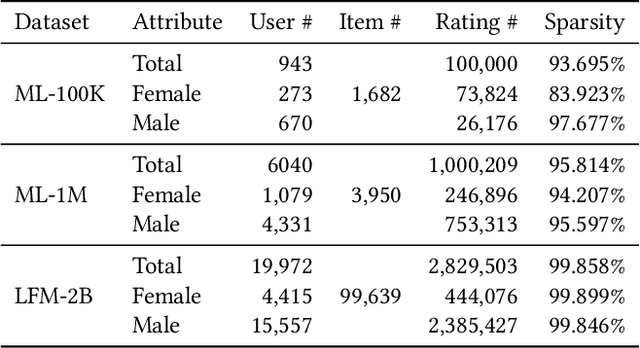
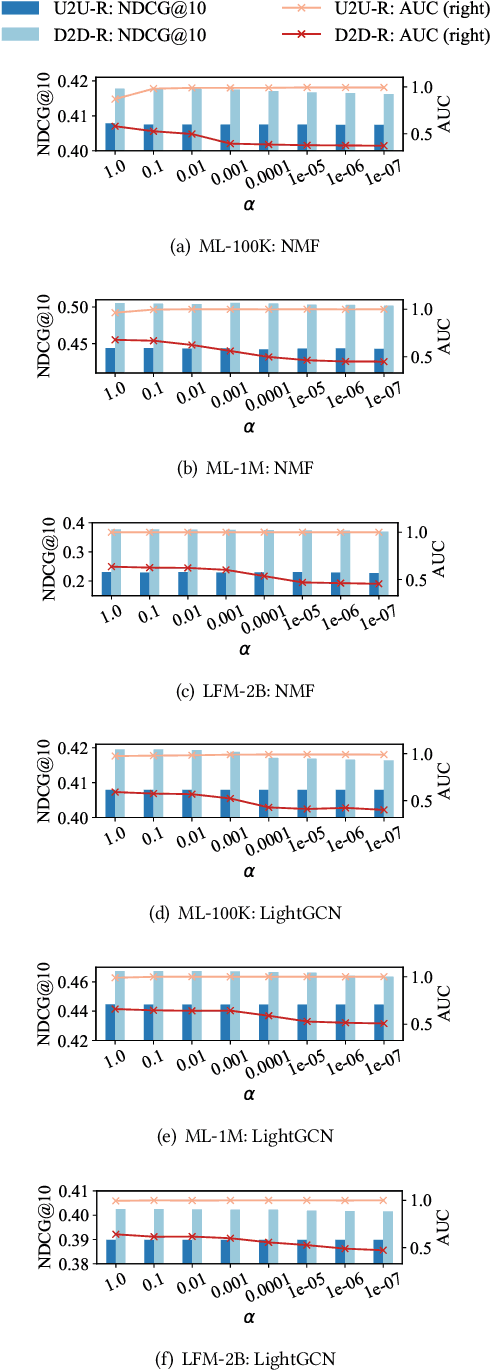
With the growing privacy concerns in recommender systems, recommendation unlearning, i.e., forgetting the impact of specific learned targets, is getting increasing attention. Existing studies predominantly use training data, i.e., model inputs, as the unlearning target. However, we find that attackers can extract private information, i.e., gender, race, and age, from a trained model even if it has not been explicitly encountered during training. We name this unseen information as attribute and treat it as the unlearning target. To protect the sensitive attribute of users, Attribute Unlearning (AU) aims to degrade attacking performance and make target attributes indistinguishable. In this paper, we focus on a strict but practical setting of AU, namely Post-Training Attribute Unlearning (PoT-AU), where unlearning can only be performed after the training of the recommendation model is completed. To address the PoT-AU problem in recommender systems, we design a two-component loss function that consists of i) distinguishability loss: making attribute labels indistinguishable from attackers, and ii) regularization loss: preventing drastic changes in the model that result in a negative impact on recommendation performance. Specifically, we investigate two types of distinguishability measurements, i.e., user-to-user and distribution-to-distribution. We use the stochastic gradient descent algorithm to optimize our proposed loss. Extensive experiments on three real-world datasets demonstrate the effectiveness of our proposed methods.
AttMOT: Improving Multiple-Object Tracking by Introducing Auxiliary Pedestrian Attributes
Aug 15, 2023



Multi-object tracking (MOT) is a fundamental problem in computer vision with numerous applications, such as intelligent surveillance and automated driving. Despite the significant progress made in MOT, pedestrian attributes, such as gender, hairstyle, body shape, and clothing features, which contain rich and high-level information, have been less explored. To address this gap, we propose a simple, effective, and generic method to predict pedestrian attributes to support general Re-ID embedding. We first introduce AttMOT, a large, highly enriched synthetic dataset for pedestrian tracking, containing over 80k frames and 6 million pedestrian IDs with different time, weather conditions, and scenarios. To the best of our knowledge, AttMOT is the first MOT dataset with semantic attributes. Subsequently, we explore different approaches to fuse Re-ID embedding and pedestrian attributes, including attention mechanisms, which we hope will stimulate the development of attribute-assisted MOT. The proposed method AAM demonstrates its effectiveness and generality on several representative pedestrian multi-object tracking benchmarks, including MOT17 and MOT20, through experiments on the AttMOT dataset. When applied to state-of-the-art trackers, AAM achieves consistent improvements in MOTA, HOTA, AssA, IDs, and IDF1 scores. For instance, on MOT17, the proposed method yields a +1.1 MOTA, +1.7 HOTA, and +1.8 IDF1 improvement when used with FairMOT. To encourage further research on attribute-assisted MOT, we will release the AttMOT dataset.
Knowledge Federation: Hierarchy and Unification
Feb 05, 2020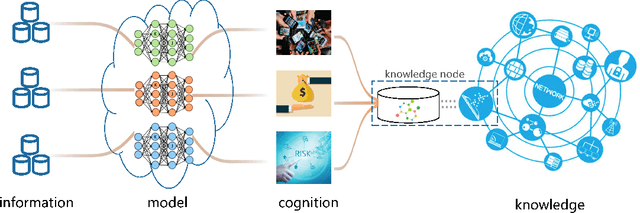
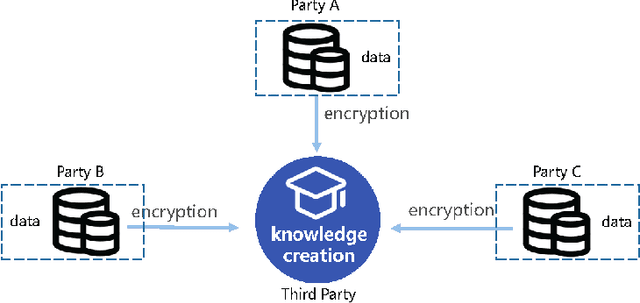
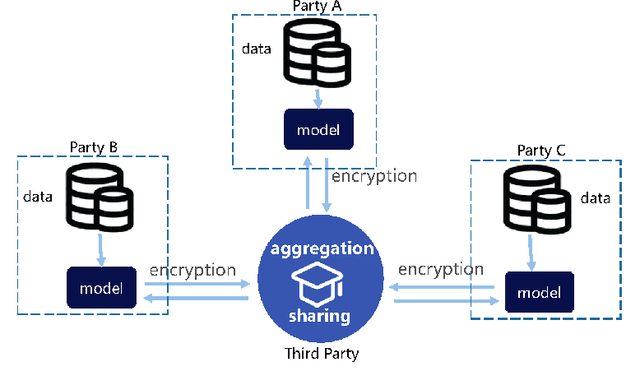
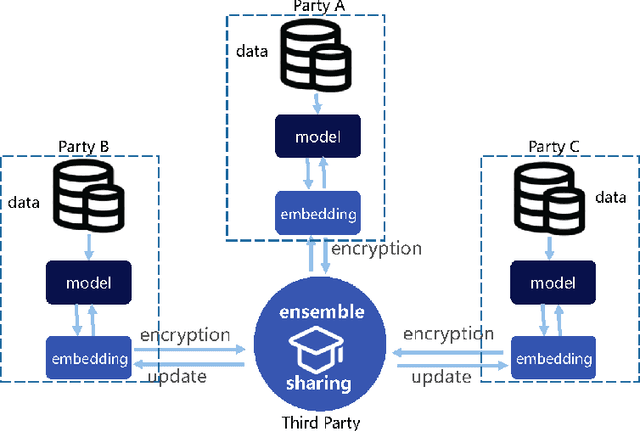
With the strengthening of data privacy and security, traditional data centralization for AI faces huge challenges. Moreover, isolated data existing in various industries and institutions is grossly underused and thus retards the advance of AI applications. We propose a possible solution to these problems: knowledge federation. Beyond the concepts of federated learning and secure multi-party computation, we introduce a comprehensive knowledge federation framework, which is a hierarchy with four-level federation. In terms of the occurrence time of federation, knowledge federation can be categorized into information level, model level, cognition level, and knowledge level. To facilitate widespread academic and commercial adoption of this concept, we provide definitions free from ambiguity for the knowledge federation framework. In addition, we clarify the relationship and differentiation between knowledge federation and other related research fields and conclude that knowledge federation is a unified framework for secure multi-party computation and learning.
Template-Instance Loss for Offline Handwritten Chinese Character Recognition
Oct 12, 2019
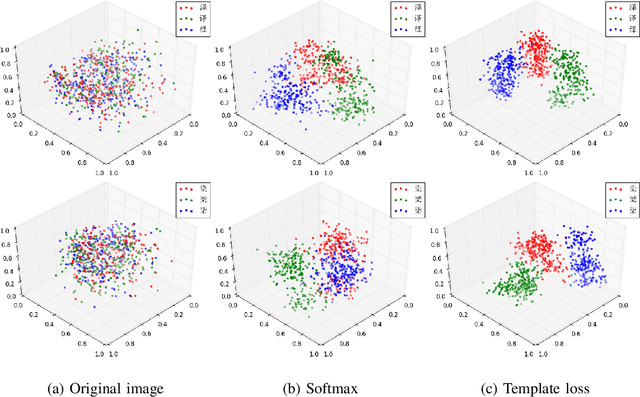


The long-standing challenges for offline handwritten Chinese character recognition (HCCR) are twofold: Chinese characters can be very diverse and complicated while similarly looking, and cursive handwriting (due to increased writing speed and infrequent pen lifting) makes strokes and even characters connected together in a flowing manner. In this paper, we propose the template and instance loss functions for the relevant machine learning tasks in offline handwritten Chinese character recognition. First, the character template is designed to deal with the intrinsic similarities among Chinese characters. Second, the instance loss can reduce category variance according to classification difficulty, giving a large penalty to the outlier instance of handwritten Chinese character. Trained with the new loss functions using our deep network architecture HCCR14Layer model consisting of simple layers, our extensive experiments show that it yields state-of-the-art performance and beyond for offline HCCR.