 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastMap: Fast Queries Initialization Based Vectorized HD Map Reconstruction Framework
Mar 07, 2025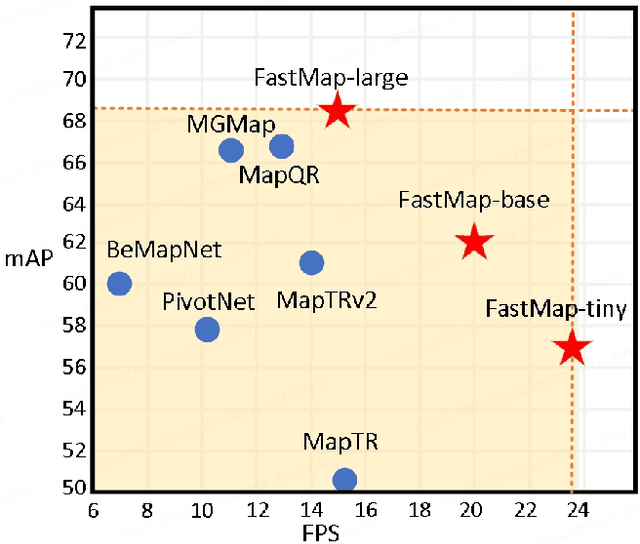
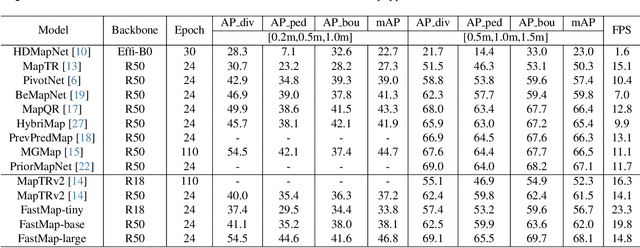
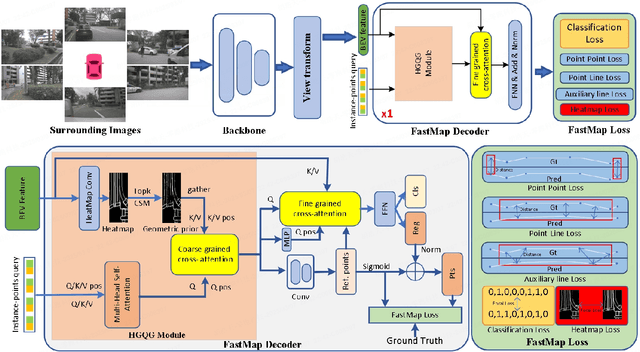
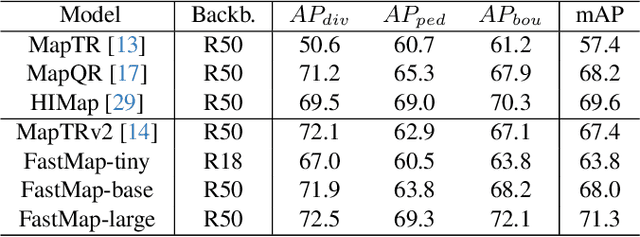
Reconstruction of high-definition maps is a crucial task in perceiving the autonomous driving environment, as its accuracy directly impacts the reliability of prediction and planning capabilities in downstream modules. Current vectorized map reconstruction methods based on the DETR framework encounter limitations due to the redundancy in the decoder structure, necessitating the stacking of six decoder layers to maintain performance, which significantly hampers computational efficiency. To tackle this issue, we introduce FastMap, an innovative framework designed to reduce decoder redundancy in existing approaches. FastMap optimizes the decoder architecture by employing a single-layer, two-stage transformer that achieves multilevel representation capabilities. Our framework eliminates the conventional practice of randomly initializing queries and instead incorporates a heatmap-guided query generation module during the decoding phase, which effectively maps image features into structured query vectors using learnable positional encoding. Additionally, we propose a geometry-constrained point-to-line loss mechanism for FastMap, which adeptly addresses the challenge of distinguishing highly homogeneous features that often arise in traditional point-to-point loss computations. Extensive experiments demonstrate that FastMap achieves state-of-the-art performance in both nuScenes and Argoverse2 datasets, with its decoder operating 3.2 faster than the baseline. Code and more demos are available at https://github.com/hht1996ok/FastMap.
Stable-SPAM: How to Train in 4-Bit More Stably than 16-Bit Adam
Feb 24, 2025



This paper comprehensively evaluates several recently proposed optimizers for 4-bit training, revealing that low-bit precision amplifies sensitivity to learning rates and often causes unstable gradient norms, leading to divergence at higher learning rates. Among these, SPAM, a recent optimizer featuring momentum reset and spike-aware gradient clipping, achieves the best performance across various bit levels, but struggles to stabilize gradient norms, requiring careful learning rate tuning. To address these limitations, we propose Stable-SPAM, which incorporates enhanced gradient normalization and clipping techniques. In particular, Stable-SPAM (1) adaptively updates the clipping threshold for spiked gradients by tracking their historical maxima; (2) normalizes the entire gradient matrix based on its historical $l_2$-norm statistics; and $(3)$ inherits momentum reset from SPAM to periodically reset the first and second moments of Adam, mitigating the accumulation of spiked gradients. Extensive experiments show that Stable-SPAM effectively stabilizes gradient norms in 4-bit LLM training, delivering superior performance compared to Adam and SPAM. Notably, our 4-bit LLaMA-1B model trained with Stable-SPAM outperforms the BF16 LLaMA-1B trained with Adam by up to $2$ perplexity. Furthermore, when both models are trained in 4-bit, Stable-SPAM achieves the same loss as Adam while requiring only about half the training steps. Code is available at https://github.com/TianjinYellow/StableSPAM.git.
LoopAnimate: Loopable Salient Object Animation
Apr 14, 2024Research on diffusion model-based video generation has advanced rapidly. However, limitations in object fidelity and generation length hinder its practical applications. Additionally, specific domains like animated wallpapers require seamless looping, where the first and last frames of the video match seamlessly. To address these challenges, this paper proposes LoopAnimate, a novel method for generating videos with consistent start and end frames. To enhance object fidelity, we introduce a framework that decouples multi-level image appearance and textual semantic information. Building upon an image-to-image diffusion model, our approach incorporates both pixel-level and feature-level information from the input image, injecting image appearance and textual semantic embeddings at different positions of the diffusion model. Existing UNet-based video generation models require to input the entire videos during training to encode temporal and positional information at once. However, due to limitations in GPU memory, the number of frames is typically restricted to 16. To address this, this paper proposes a three-stage training strategy with progressively increasing frame numbers and reducing fine-tuning modules. Additionally, we introduce the Temporal E nhanced Motion Module(TEMM) to extend the capacity for encoding temporal and positional information up to 36 frames. The proposed LoopAnimate, which for the first time extends the single-pass generation length of UNet-based video generation models to 35 frames while maintaining high-quality video generation. Experiments demonstrate that LoopAnimate achieves state-of-the-art performance in both objective metrics, such as fidelity and temporal consistency, and subjective evaluation results.
ADMap: Anti-disturbance framework for reconstructing online vectorized HD map
Jan 24, 2024



In the field of autonomous driving, online high-definition (HD) map reconstruction is crucial for planning tasks. Recent research has developed several high-performance HD map reconstruction models to meet this necessity. However, the point sequences within the instance vectors may be jittery or jagged due to prediction bias, which can impact subsequent tasks. Therefore, this paper proposes the Anti-disturbance Map reconstruction framework (ADMap). To mitigate point-order jitter, the framework consists of three modules: Multi-Scale Perception Neck, Instance Interactive Attention (IIA), and Vector Direction Difference Loss (VDDL). By exploring the point-order relationships between and within instances in a cascading manner, the model can monitor the point-order prediction process more effectively. ADMap achieves state-of-the-art performance on the nuScenes and Argoverse2 datasets. Extensive results demonstrate its ability to produce stable and reliable map elements in complex and changing driving scenarios. Code and more demos are available at https://github.com/hht1996ok/ADMap.
A Machine Vision Method for Correction of Eccentric Error: Based on Adaptive Enhancement Algorithm
Sep 01, 2023In the procedure of surface defects detection for large-aperture aspherical optical elements, it is of vital significance to adjust the optical axis of the element to be coaxial with the mechanical spin axis accurately. Therefore, a machine vision method for eccentric error correction is proposed in this paper. Focusing on the severe defocus blur of reference crosshair image caused by the imaging characteristic of the aspherical optical element, which may lead to the failure of correction, an Adaptive Enhancement Algorithm (AEA) is proposed to strengthen the crosshair image. AEA is consisted of existed Guided Filter Dark Channel Dehazing Algorithm (GFA) and proposed lightweight Multi-scale Densely Connected Network (MDC-Net). The enhancement effect of GFA is excellent but time-consuming, and the enhancement effect of MDC-Net is slightly inferior but strongly real-time. As AEA will be executed dozens of times during each correction procedure, its real-time performance is very important. Therefore, by setting the empirical threshold of definition evaluation function SMD2, GFA and MDC-Net are respectively applied to highly and slightly blurred crosshair images so as to ensure the enhancement effect while saving as much time as possible. AEA has certain robustness in time-consuming performance, which takes an average time of 0.2721s and 0.0963s to execute GFA and MDC-Net separately on ten 200pixels 200pixels Region of Interest (ROI) images with different degrees of blur. And the eccentricity error can be reduced to within 10um by our method.
GujiBERT and GujiGPT: Construction of Intelligent Information Processing Foundation Language Models for Ancient Texts
Jul 11, 2023



In the context of the rapid development of large language models, we have meticulously trained and introduced the GujiBERT and GujiGPT language models, which are foundational models specifically designed for intelligent information processing of ancient texts. These models have been trained on an extensive dataset that encompasses both simplified and traditional Chinese characters, allowing them to effectively handle various natural language processing tasks related to ancient books, including but not limited to automatic sentence segmentation, punctuation, word segmentation, part-of-speech tagging, entity recognition, and automatic translation. Notably, these models have exhibited exceptional performance across a range of validation tasks using publicly available datasets. Our research findings highlight the efficacy of employing self-supervised methods to further train the models using classical text corpora, thus enhancing their capability to tackle downstream tasks. Moreover, it is worth emphasizing that the choice of font, the scale of the corpus, and the initial model selection all exert significant influence over the ultimate experimental outcomes. To cater to the diverse text processing preferences of researchers in digital humanities and linguistics, we have developed three distinct categories comprising a total of nine model variations. We believe that by sharing these foundational language models specialized in the domain of ancient texts, we can facilitate the intelligent processing and scholarly exploration of ancient literary works and, consequently, contribute to the global dissemination of China's rich and esteemed traditional culture in this new era.
EA-BEV: Edge-aware Bird' s-Eye-View Projector for 3D Object Detection
Apr 18, 2023



In recent years, great progress has been made in the Lift-Splat-Shot-based (LSS-based) 3D object detection method, which converts features of 2D camera view and 3D lidar view to Bird's-Eye-View (BEV) for feature fusion. However, inaccurate depth estimation (e.g. the 'depth jump' problem) is an obstacle to develop LSS-based methods. To alleviate the 'depth jump' problem, we proposed Edge-Aware Bird's-Eye-View (EA-BEV) projector. By coupling proposed edge-aware depth fusion module and depth estimate module, the proposed EA-BEV projector solves the problem and enforces refined supervision on depth. Besides, we propose sparse depth supervision and gradient edge depth supervision, for constraining learning on global depth and local marginal depth information. Our EA-BEV projector is a plug-and-play module for any LSS-based 3D object detection models, and effectively improves the baseline performance. We demonstrate the effectiveness on the nuScenes benchmark. On the nuScenes 3D object detection validation dataset, our proposed EA-BEV projector can boost several state-of-the-art LLS-based baselines on nuScenes 3D object detection benchmark and nuScenes BEV map segmentation benchmark with negligible increment of inference time.
GAM : Gradient Attention Module of Optimization for Point Clouds Analysis
Mar 21, 2023In point cloud analysis tasks, the existing local feature aggregation descriptors (LFAD) are unable to fully utilize information in the neighborhood of central points. Previous methods rely solely on Euclidean distance to constrain the local aggregation process, which can be easily affected by abnormal points and cannot adequately fit with the original geometry of the point cloud. We believe that fine-grained geometric information (FGGI) is significant for the aggregation of local features. Therefore, we propose a gradient-based local attention module, termed as Gradient Attention Module (GAM), to address the aforementioned problem. Our proposed GAM simplifies the process that extracts gradient information in the neighborhood and uses the Zenith Angle matrix and Azimuth Angle matrix as explicit representation, which accelerates the module by 35X. Comprehensive experiments were conducted on five benchmark datasets to demonstrate the effectiveness and generalization capability of the proposed GAM for 3D point cloud analysis. Especially on S3DIS dataset, GAM achieves the best performance among current point-based models with mIoU/OA/mAcc of 74.4%/90.6%/83.2%, respectively.
* In AAAI, 2023
VA-GCN: A Vector Attention Graph Convolution Network for learning on Point Clouds
Jun 01, 2021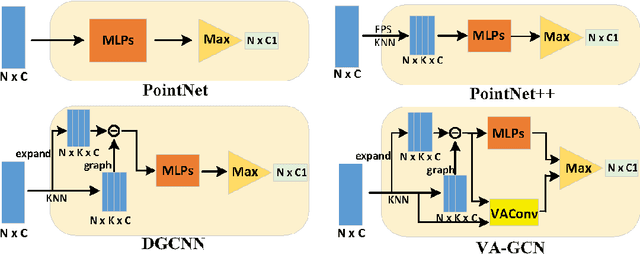
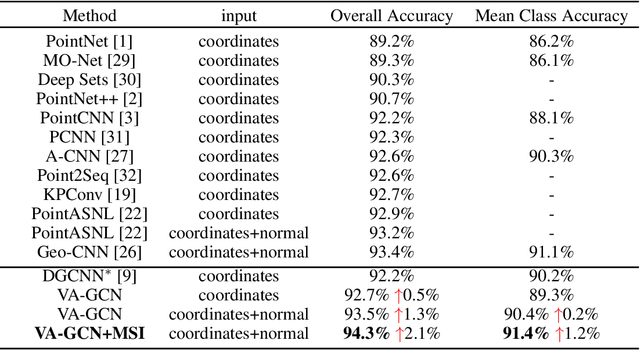
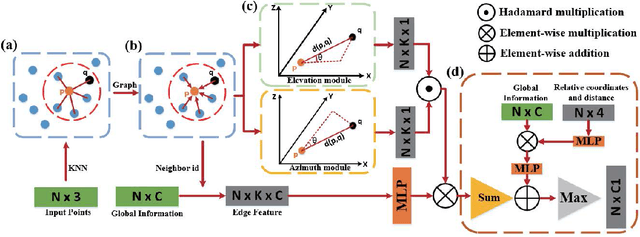
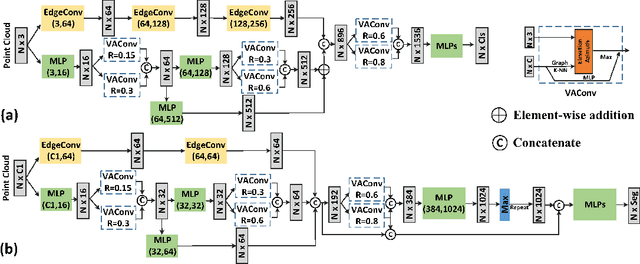
Owing to the development of research on local aggregation operators, dramatic breakthrough has been made in point cloud analysis models. However, existing local aggregation operators in the current literature fail to attach decent importance to the local information of the point cloud, which limits the power of the models. To fit this gap, we propose an efficient Vector Attention Convolution module (VAConv), which utilizes K-Nearest Neighbor (KNN) to extract the neighbor points of each input point, and then uses the elevation and azimuth relationship of the vectors between the center point and its neighbors to construct an attention weight matrix for edge features. Afterwards, the VAConv adopts a dual-channel structure to fuse weighted edge features and global features. To verify the efficiency of the VAConv, we connect the VAConvs with different receptive fields in parallel to obtain a Multi-scale graph convolutional network, VA-GCN. The proposed VA-GCN achieves state-of-the-art performance on standard benchmarks including ModelNet40, S3DIS and ShapeNet. Remarkably, on the ModelNet40 dataset for 3D classification, VA-GCN increased by 2.4% compared to the baseline.
BAM: A Lightweight and Efficient Balanced Attention Mechanism for Single Image Super Resolution
Apr 15, 2021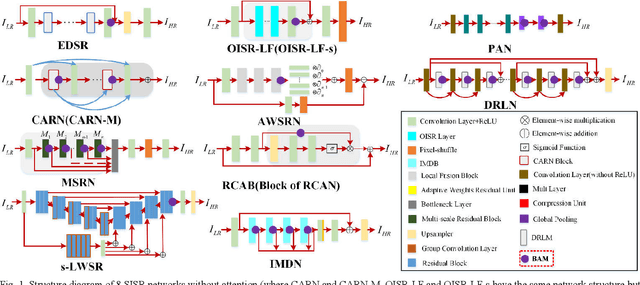

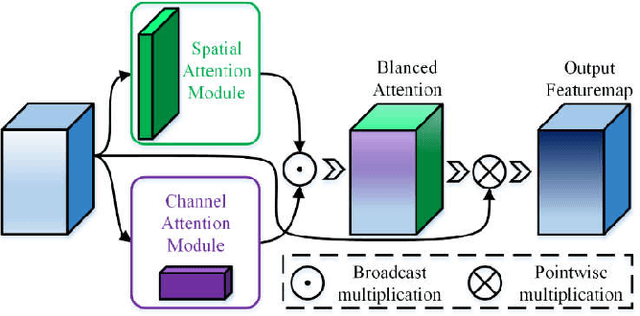
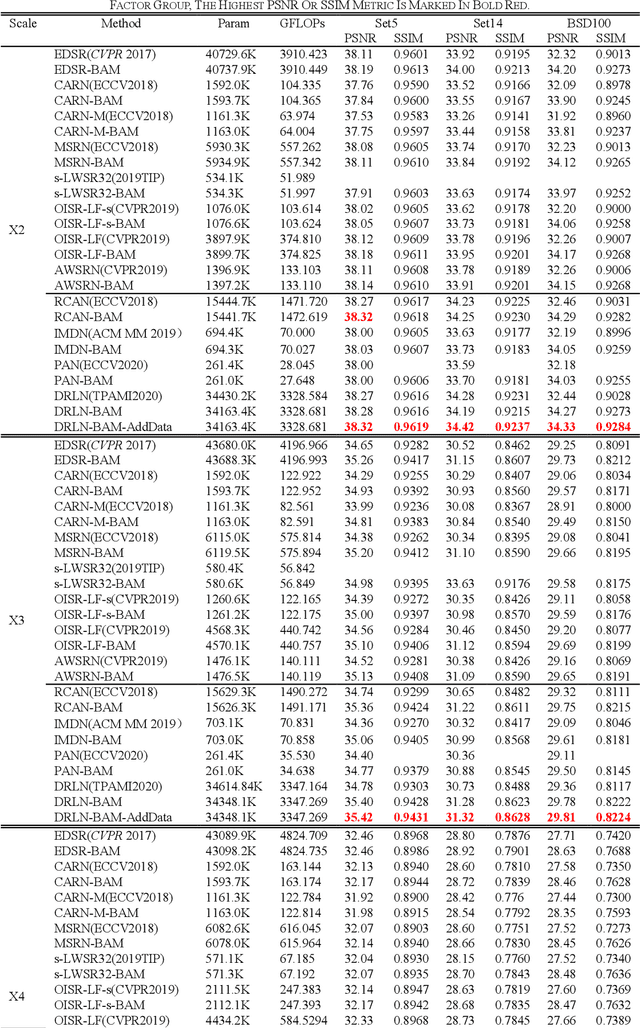
Single image super-resolution (SISR) is one of the most challenging problems in the field of computer vision. Among the deep convolutional neural network based methods, attention mechanism has shown the enormous potential. However, due to the diverse network architectures, there is a lack of a universal attention mechanism for the SISR task. In this paper, we propose a lightweight and efficient Balanced Attention Mechanism (BAM), which can be generally applicable for different SISR networks. It consists of Avgpool Channel Attention Module (ACAM) and Maxpool Spatial Attention Module (MSAM). These two modules are connected in parallel to minimize the error accumulation and the crosstalk. To reduce the undesirable effect of redundant information on the attention generation, we only apply Avgpool for channel attention because Maxpool could pick up the illusive extreme points in the feature map across the spatial dimensions, and we only apply Maxpool for spatial attention because the useful features along the channel dimension usually exist in the form of maximum values for SISR task. To verify the efficiency and robustness of BAM, we apply it to 12 state-of-the-art SISR networks, among which eight were without attention thus we plug BAM in and four were with attention thus we replace its original attention module with BAM. We experiment on Set5, Set14 and BSD100 benchmark datasets with the scale factor of x2 , x3 and x4 . The results demonstrate that BAM can generally improve the network performance. Moreover, we conduct the ablation experiments to prove the minimalism of BAM. Our results show that the parallel structure of BAM can better balance channel and spatial attentions, thus outperforming the series structure of prior Convolutional Block Attention Module (CBAM).