 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Metrics: Measuring Research Impact Through Large Language Model Memory
May 21, 2026Citation counts remain the dominant metric for assessing research impact, yet they suffer from well-documented limitations: temporal lag, disciplinary bias, and Matthew effects. Here we propose LLM-Metrics, a research-impact assessment metric derived from the parametric memory of large language models (LLMs). The central hypothesis is that high-impact papers receive greater exposure in the academic community, that this exposure enters LLM training data in textual form, and that models consequently form stronger parametric memory of these papers. We designed four types of multiple-choice probes, covering title recognition, author recognition, method recognition, and venue recognition, and evaluated 549 computer science papers published in 2023-2024 across 17 LLMs spanning 0.5B to 72B parameters from six vendors. Of the 17 models, 15 produced positive predictions, 9 of which were significant at p less than 0.05, with an overall Spearman correlation of rho = 0.1495 and p = 0.0004 against citation counts. Three additional findings support the proposed mechanism. First, the predictive signal was stronger for 2024 papers, rho = 0.1880, whose citation counts were near zero at model-training time, reducing the plausibility of a simple reverse-causality explanation. Second, author-recognition probes showed the strongest discriminative power, consistent with an exposure-driven memory mechanism. Third, model scale and predictive power were non-monotonic: a 3B-parameter model, Llama-3.2-3B-Instruct, with rho = 0.1829, outperformed most larger models, supporting a selective-memory hypothesis in which the limited capacity of smaller models can serve as an effective information filter. LLM-Metrics offers a real-time, cross-disciplinary, citation-independent paradigm for research assessment.
VersaVogue: Visual Expert Orchestration and Preference Alignment for Unified Fashion Synthesis
Apr 08, 2026Diffusion models have driven remarkable advancements in fashion image generation, yet prior works usually treat garment generation and virtual dressing as separate problems, limiting their flexibility in real-world fashion workflows. Moreover, fashion image synthesis under multi-source heterogeneous conditions remains challenging, as existing methods typically rely on simple feature concatenation or static layer-wise injection, which often causes attribute entanglement and semantic interference. To address these issues, we propose VersaVogue, a unified framework for multi-condition controllable fashion synthesis that jointly supports garment generation and virtual dressing, corresponding to the design and showcase stages of the fashion lifecycle. Specifically, we introduce a trait-routing attention (TA) module that leverages a mixture-of-experts mechanism to dynamically route condition features to the most compatible experts and generative layers, enabling disentangled injection of visual attributes such as texture, shape, and color. To further improve realism and controllability, we develop an automated multi-perspective preference optimization (MPO) pipeline that constructs preference data without human annotation or task-specific reward models. By combining evaluators of content fidelity, textual alignment, and perceptual quality, MPO identifies reliable preference pairs, which are then used to optimize the model via direct preference optimization (DPO). Extensive experiments on both garment generation and virtual dressing benchmarks demonstrate that VersaVogue consistently outperforms existing methods in visual fidelity, semantic consistency, and fine-grained controllability.
Jointly Conditioned Diffusion Model for Multi-View Pose-Guided Person Image Synthesis
Nov 19, 2025Pose-guided human image generation is limited by incomplete textures from single reference views and the absence of explicit cross-view interaction. We present jointly conditioned diffusion model (JCDM), a jointly conditioned diffusion framework that exploits multi-view priors. The appearance prior module (APM) infers a holistic identity preserving prior from incomplete references, and the joint conditional injection (JCI) mechanism fuses multi-view cues and injects shared conditioning into the denoising backbone to align identity, color, and texture across poses. JCDM supports a variable number of reference views and integrates with standard diffusion backbones with minimal and targeted architectural modifications. Experiments demonstrate state of the art fidelity and cross-view consistency.
RevOrder: A Novel Method for Enhanced Arithmetic in Language Models
Feb 06, 2024This paper presents RevOrder, a novel technique aimed at improving arithmetic operations in large language models (LLMs) by reversing the output digits in addition, subtraction, and n-digit by 1-digit (nD by 1D) multiplication tasks. Our method significantly reduces the Count of Sequential Intermediate Digits (CSID) to $\mathcal{O}(1)$, a new metric we introduce to assess equation complexity. Through comprehensive testing, RevOrder not only achieves perfect accuracy in basic arithmetic operations but also substantially boosts LLM performance in division tasks, particularly with large numbers where traditional models struggle. Implementation of RevOrder is cost-effective for both training and inference phases. Moreover, applying RevOrder to fine-tune the LLaMA2-7B model on the GSM8K math task results in a considerable improvement, reducing equation calculation errors by 46% and increasing overall scores from 41.6 to 44.4.
GujiBERT and GujiGPT: Construction of Intelligent Information Processing Foundation Language Models for Ancient Texts
Jul 11, 2023



In the context of the rapid development of large language models, we have meticulously trained and introduced the GujiBERT and GujiGPT language models, which are foundational models specifically designed for intelligent information processing of ancient texts. These models have been trained on an extensive dataset that encompasses both simplified and traditional Chinese characters, allowing them to effectively handle various natural language processing tasks related to ancient books, including but not limited to automatic sentence segmentation, punctuation, word segmentation, part-of-speech tagging, entity recognition, and automatic translation. Notably, these models have exhibited exceptional performance across a range of validation tasks using publicly available datasets. Our research findings highlight the efficacy of employing self-supervised methods to further train the models using classical text corpora, thus enhancing their capability to tackle downstream tasks. Moreover, it is worth emphasizing that the choice of font, the scale of the corpus, and the initial model selection all exert significant influence over the ultimate experimental outcomes. To cater to the diverse text processing preferences of researchers in digital humanities and linguistics, we have developed three distinct categories comprising a total of nine model variations. We believe that by sharing these foundational language models specialized in the domain of ancient texts, we can facilitate the intelligent processing and scholarly exploration of ancient literary works and, consequently, contribute to the global dissemination of China's rich and esteemed traditional culture in this new era.
Increasing Visual Awareness in Multimodal Neural Machine Translation from an Information Theoretic Perspective
Oct 16, 2022
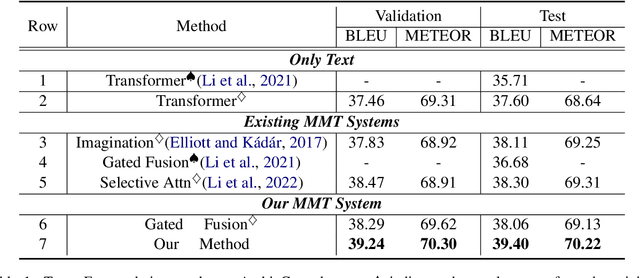

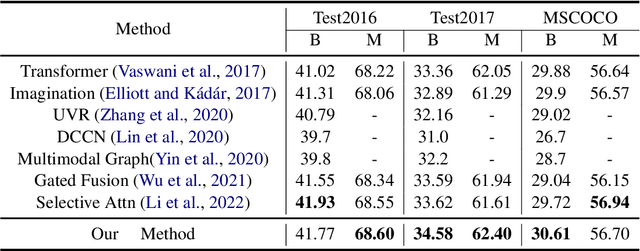
Multimodal machine translation (MMT) aims to improve translation quality by equipping the source sentence with its corresponding image. Despite the promising performance, MMT models still suffer the problem of input degradation: models focus more on textual information while visual information is generally overlooked. In this paper, we endeavor to improve MMT performance by increasing visual awareness from an information theoretic perspective. In detail, we decompose the informative visual signals into two parts: source-specific information and target-specific information. We use mutual information to quantify them and propose two methods for objective optimization to better leverage visual signals. Experiments on two datasets demonstrate that our approach can effectively enhance the visual awareness of MMT model and achieve superior results against strong baselines.
SsciBERT: A Pre-trained Language Model for Social Science Texts
Jun 11, 2022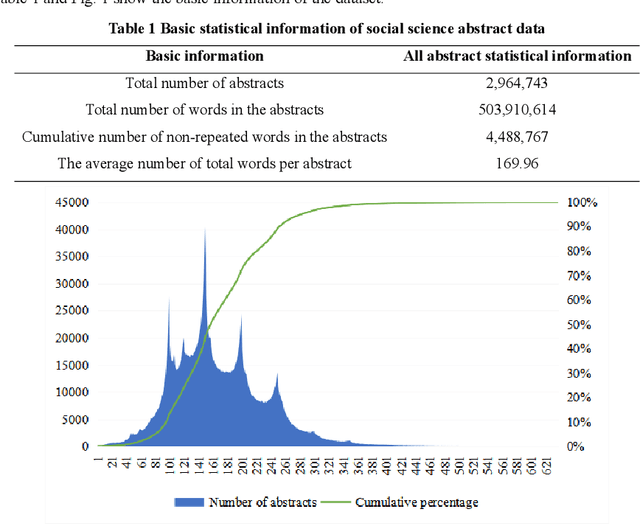
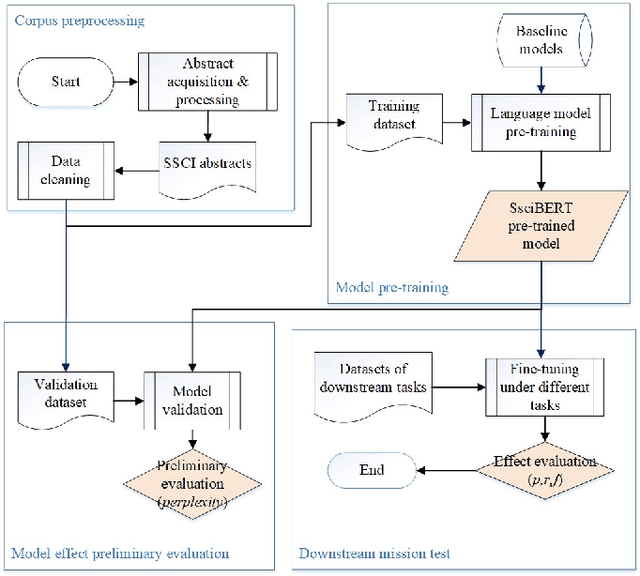


The academic literature of social sciences is the literature that records human civilization and studies human social problems. With the large-scale growth of this literature, ways to quickly find existing research on relevant issues have become an urgent demand for researchers. Previous studies, such as SciBERT, have shown that pre-training using domain-specific texts can improve the performance of natural language processing tasks in those fields. However, there is no pre-trained language model for social sciences, so this paper proposes a pre-trained model on many abstracts published in the Social Science Citation Index (SSCI) journals. The models, which are available on Github (https://github.com/S-T-Full-Text-Knowledge-Mining/SSCI-BERT), show excellent performance on discipline classification and abstract structure-function recognition tasks with the social sciences literature.
Going Wider: Recurrent Neural Network With Parallel Cells
May 03, 2017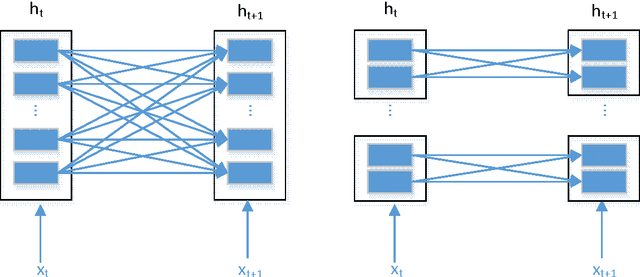
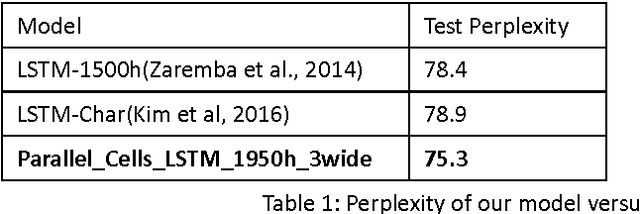
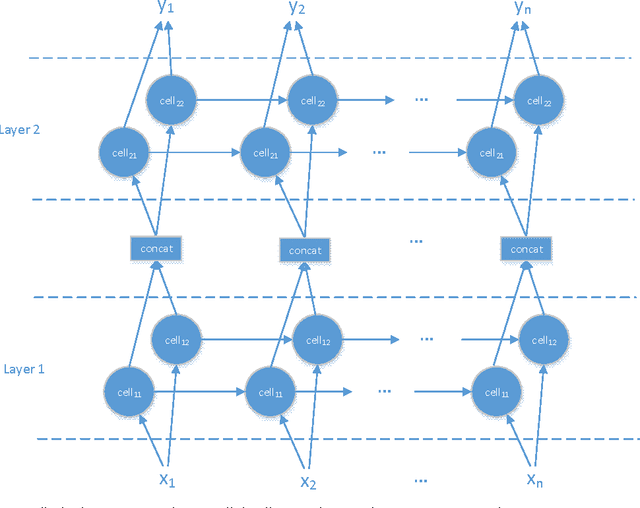
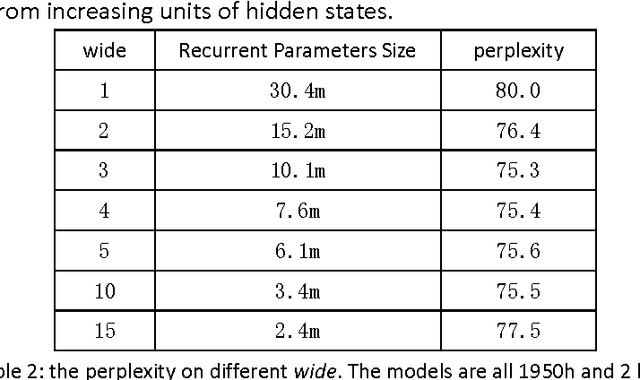
Recurrent Neural Network (RNN) has been widely applied for sequence modeling. In RNN, the hidden states at current step are full connected to those at previous step, thus the influence from less related features at previous step may potentially decrease model's learning ability. We propose a simple technique called parallel cells (PCs) to enhance the learning ability of Recurrent Neural Network (RNN). In each layer, we run multiple small RNN cells rather than one single large cell. In this paper, we evaluate PCs on 2 tasks. On language modeling task on PTB (Penn Tree Bank), our model outperforms state of art models by decreasing perplexity from 78.6 to 75.3. On Chinese-English translation task, our model increases BLEU score for 0.39 points than baseline model.