 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSsciBERT: A Pre-trained Language Model for Social Science Texts
Paper and Code
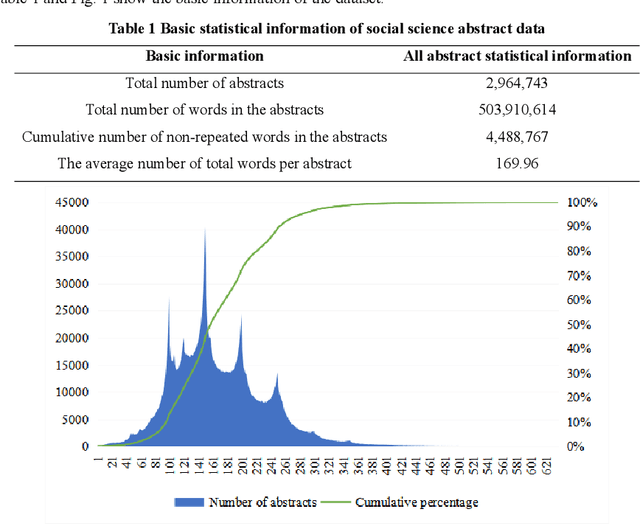
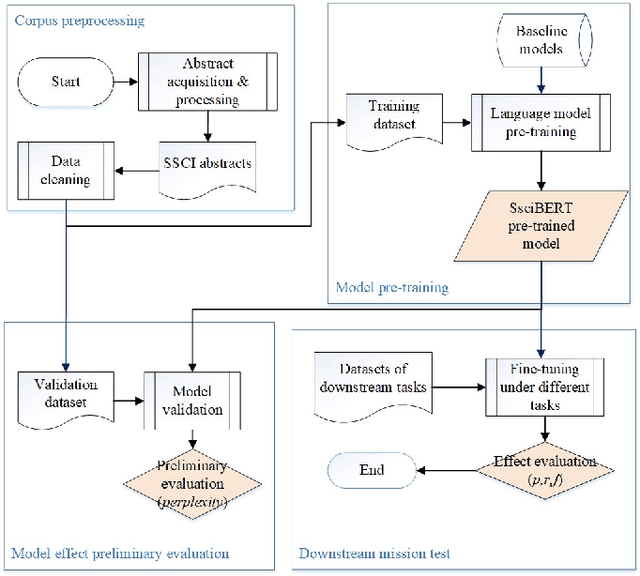


The academic literature of social sciences is the literature that records human civilization and studies human social problems. With the large-scale growth of this literature, ways to quickly find existing research on relevant issues have become an urgent demand for researchers. Previous studies, such as SciBERT, have shown that pre-training using domain-specific texts can improve the performance of natural language processing tasks in those fields. However, there is no pre-trained language model for social sciences, so this paper proposes a pre-trained model on many abstracts published in the Social Science Citation Index (SSCI) journals. The models, which are available on Github (https://github.com/S-T-Full-Text-Knowledge-Mining/SSCI-BERT), show excellent performance on discipline classification and abstract structure-function recognition tasks with the social sciences literature.