 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSA: Compressed Sensing-Based Adaptation of Large Language Models
Feb 05, 2026Parameter-Efficient Fine-Tuning (PEFT) has emerged as a practical paradigm for adapting large language models (LLMs) without updating all parameters. Most existing approaches, such as LoRA and PiSSA, rely on low-rank decompositions of weight updates. However, the low-rank assumption may restrict expressivity, particularly in task-specific adaptation scenarios where singular values are distributed relatively uniformly. To address this limitation, we propose CoSA (Compressed Sensing-Based Adaptation), a new PEFT method extended from compressed sensing theory. Instead of constraining weight updates to a low-rank subspace, CoSA expresses them through fixed random projection matrices and a compact learnable core. We provide a formal theoretical analysis of CoSA as a synthesis process, proving that weight updates can be compactly encoded into a low-dimensional space and mapped back through random projections. Extensive experimental results show that CoSA provides a principled perspective for efficient and expressive multi-scale model adaptation. Specifically, we evaluate CoSA on 10 diverse tasks, including natural language understanding and generation, employing 5 models of different scales from RoBERTa, Llama, and Qwen families. Across these settings, CoSA consistently matches or outperforms state-of-the-art PEFT methods.
GAIA: A Data Flywheel System for Training GUI Test-Time Scaling Critic Models
Jan 26, 2026While Large Vision-Language Models (LVLMs) have significantly advanced GUI agents' capabilities in parsing textual instructions, interpreting screen content, and executing tasks, a critical challenge persists: the irreversibility of agent operations, where a single erroneous action can trigger catastrophic deviations. To address this, we propose the GUI Action Critic's Data Flywheel System (GAIA), a training framework that enables the models to have iterative critic capabilities, which are used to improve the Test-Time Scaling (TTS) of basic GUI agents' performance. Specifically, we train an Intuitive Critic Model (ICM) using positive and negative action examples from a base agent first. This critic evaluates the immediate correctness of the agent's intended actions, thereby selecting operations with higher success probability. Then, the initial critic guides agent actions to collect refined positive/negative samples, initiating the self-improving cycle. The augmented data then trains a second-round critic with enhanced discernment capability. We conduct experiments on various datasets and demonstrate that the proposed ICM can improve the test-time performance of various closed-source and open-source models, and the performance can be gradually improved as the data is recycled. The code and dataset will be publicly released.
Unified Multimodal and Multilingual Retrieval via Multi-Task Learning with NLU Integration
Jan 21, 2026Multimodal retrieval systems typically employ Vision Language Models (VLMs) that encode images and text independently into vectors within a shared embedding space. Despite incorporating text encoders, VLMs consistently underperform specialized text models on text-only retrieval tasks. Moreover, introducing additional text encoders increases storage, inference overhead, and exacerbates retrieval inefficiencies, especially in multilingual settings. To address these limitations, we propose a multi-task learning framework that unifies the feature representation across images, long and short texts, and intent-rich queries. To our knowledge, this is the first work to jointly optimize multilingual image retrieval, text retrieval, and natural language understanding (NLU) tasks within a single framework. Our approach integrates image and text retrieval with a shared text encoder that is enhanced by NLU features for intent understanding and retrieval accuracy.
MT-Mark: Rethinking Image Watermarking via Mutual-Teacher Collaboration with Adaptive Feature Modulation
Dec 22, 2025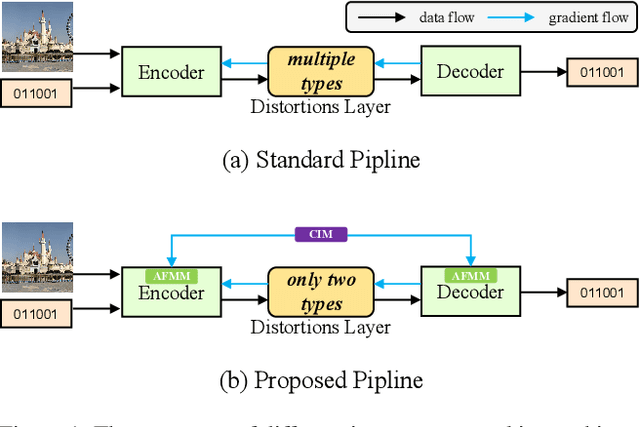
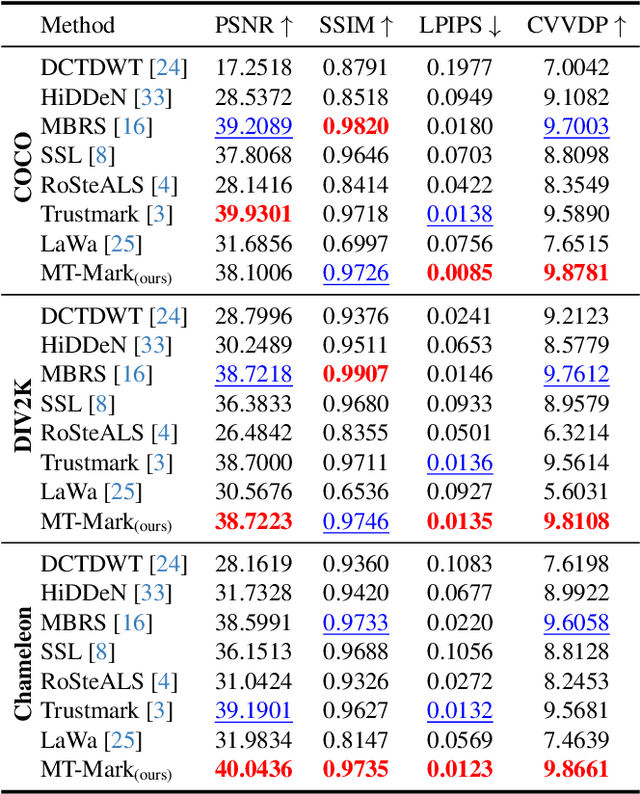
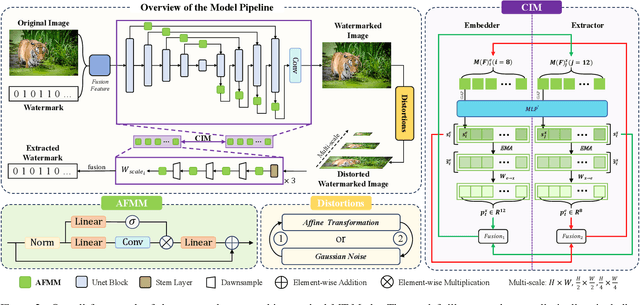
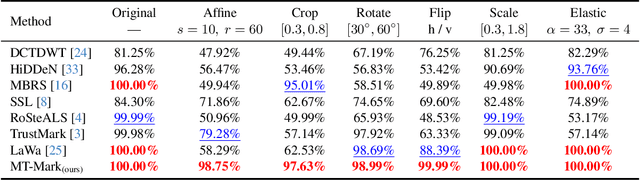
Existing deep image watermarking methods follow a fixed embedding-distortion-extraction pipeline, where the embedder and extractor are weakly coupled through a final loss and optimized in isolation. This design lacks explicit collaboration, leaving no structured mechanism for the embedder to incorporate decoding-aware cues or for the extractor to guide embedding during training. To address this architectural limitation, we rethink deep image watermarking by reformulating embedding and extraction as explicitly collaborative components. To realize this reformulation, we introduce a Collaborative Interaction Mechanism (CIM) that establishes direct, bidirectional communication between the embedder and extractor, enabling a mutual-teacher training paradigm and coordinated optimization. Built upon this explicitly collaborative architecture, we further propose an Adaptive Feature Modulation Module (AFMM) to support effective interaction. AFMM enables content-aware feature regulation by decoupling modulation structure and strength, guiding watermark embedding toward stable image features while suppressing host interference during extraction. Under CIM, the AFMMs on both sides form a closed-loop collaboration that aligns embedding behavior with extraction objectives. This architecture-level redesign changes how robustness is learned in watermarking systems. Rather than relying on exhaustive distortion simulation, robustness emerges from coordinated representation learning between embedding and extraction. Experiments on real-world and AI-generated datasets demonstrate that the proposed method consistently outperforms state-of-the-art approaches in watermark extraction accuracy while maintaining high perceptual quality, showing strong robustness and generalization.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025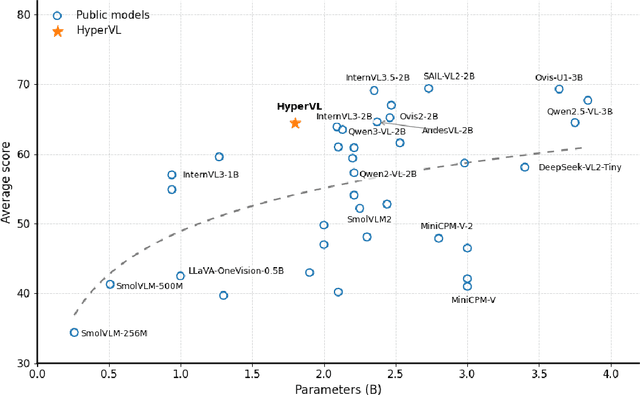

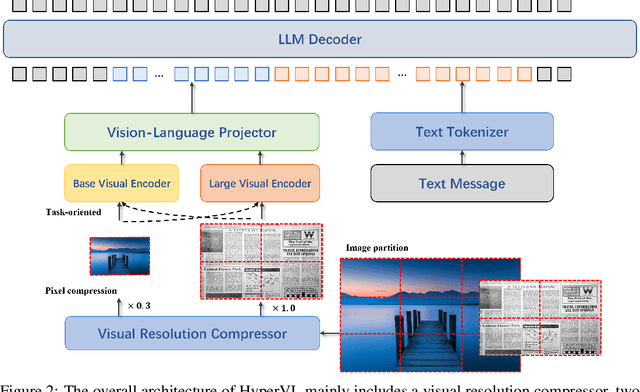

Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
HyperClick: Advancing Reliable GUI Grounding via Uncertainty Calibration
Oct 31, 2025Autonomous Graphical User Interface (GUI) agents rely on accurate GUI grounding, which maps language instructions to on-screen coordinates, to execute user commands. However, current models, whether trained via supervised fine-tuning (SFT) or reinforcement fine-tuning (RFT), lack self-awareness of their capability boundaries, leading to overconfidence and unreliable predictions. We first systematically evaluate probabilistic and verbalized confidence in general and GUI-specific models, revealing a misalignment between confidence and actual accuracy, which is particularly critical in dynamic GUI automation tasks, where single errors can cause task failure. To address this, we propose HyperClick, a novel framework that enhances reliable GUI grounding through uncertainty calibration. HyperClick introduces a dual reward mechanism, combining a binary reward for correct actions with a truncated Gaussian-based spatial confidence modeling, calibrated using the Brier score. This approach jointly optimizes grounding accuracy and confidence reliability, fostering introspective self-criticism. Extensive experiments on seven challenge benchmarks show that HyperClick achieves state-of-the-art performance while providing well-calibrated confidence. By enabling explicit confidence calibration and introspective self-criticism, HyperClick reduces overconfidence and supports more reliable GUI automation.
BTL-UI: Blink-Think-Link Reasoning Model for GUI Agent
Sep 19, 2025In the field of AI-driven human-GUI interaction automation, while rapid advances in multimodal large language models and reinforcement fine-tuning techniques have yielded remarkable progress, a fundamental challenge persists: their interaction logic significantly deviates from natural human-GUI communication patterns. To fill this gap, we propose "Blink-Think-Link" (BTL), a brain-inspired framework for human-GUI interaction that mimics the human cognitive process between users and graphical interfaces. The system decomposes interactions into three biologically plausible phases: (1) Blink - rapid detection and attention to relevant screen areas, analogous to saccadic eye movements; (2) Think - higher-level reasoning and decision-making, mirroring cognitive planning; and (3) Link - generation of executable commands for precise motor control, emulating human action selection mechanisms. Additionally, we introduce two key technical innovations for the BTL framework: (1) Blink Data Generation - an automated annotation pipeline specifically optimized for blink data, and (2) BTL Reward -- the first rule-based reward mechanism that enables reinforcement learning driven by both process and outcome. Building upon this framework, we develop a GUI agent model named BTL-UI, which demonstrates consistent state-of-the-art performance across both static GUI understanding and dynamic interaction tasks in comprehensive benchmarks. These results provide conclusive empirical validation of the framework's efficacy in developing advanced GUI Agents.
Lego-Edit: A General Image Editing Framework with Model-Level Bricks and MLLM Builder
Sep 16, 2025Instruction-based image editing has garnered significant attention due to its direct interaction with users. However, real-world user instructions are immensely diverse, and existing methods often fail to generalize effectively to instructions outside their training domain, limiting their practical application. To address this, we propose Lego-Edit, which leverages the generalization capability of Multi-modal Large Language Model (MLLM) to organize a suite of model-level editing tools to tackle this challenge. Lego-Edit incorporates two key designs: (1) a model-level toolkit comprising diverse models efficiently trained on limited data and several image manipulation functions, enabling fine-grained composition of editing actions by the MLLM; and (2) a three-stage progressive reinforcement learning approach that uses feedback on unannotated, open-domain instructions to train the MLLM, equipping it with generalized reasoning capabilities for handling real-world instructions. Experiments demonstrate that Lego-Edit achieves state-of-the-art performance on GEdit-Bench and ImgBench. It exhibits robust reasoning capabilities for open-domain instructions and can utilize newly introduced editing tools without additional fine-tuning. Code is available: https://github.com/xiaomi-research/lego-edit.
AdaCM$^2$: On Understanding Extremely Long-Term Video with Adaptive Cross-Modality Memory Reduction
Nov 19, 2024The advancements in large language models (LLMs) have propelled the improvement of video understanding tasks by incorporating LLMs with visual models. However, most existing LLM-based models (e.g., VideoLLaMA, VideoChat) are constrained to processing short-duration videos. Recent attempts to understand long-term videos by extracting and compressing visual features into a fixed memory size. Nevertheless, those methods leverage only visual modality to merge video tokens and overlook the correlation between visual and textual queries, leading to difficulties in effectively handling complex question-answering tasks. To address the challenges of long videos and complex prompts, we propose AdaCM$^2$, which, for the first time, introduces an adaptive cross-modality memory reduction approach to video-text alignment in an auto-regressive manner on video streams. Our extensive experiments on various video understanding tasks, such as video captioning, video question answering, and video classification, demonstrate that AdaCM$^2$ achieves state-of-the-art performance across multiple datasets while significantly reducing memory usage. Notably, it achieves a 4.5% improvement across multiple tasks in the LVU dataset with a GPU memory consumption reduction of up to 65%.
Beyond Point Annotation: A Weakly Supervised Network Guided by Multi-Level Labels Generated from Four-Point Annotation for Thyroid Nodule Segmentation in Ultrasound Image
Oct 25, 2024

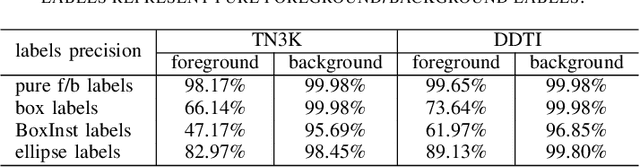

Weakly-supervised methods typically guided the pixel-wise training by comparing the predictions to single-level labels containing diverse segmentation-related information at once, but struggled to represent delicate feature differences between nodule and background regions and confused incorrect information, resulting in underfitting or overfitting in the segmentation predictions. In this work, we propose a weakly-supervised network that generates multi-level labels from four-point annotation to refine diverse constraints for delicate nodule segmentation. The Distance-Similarity Fusion Prior referring to the points annotations filters out information irrelevant to nodules. The bounding box and pure foreground/background labels, generated from the point annotation, guarantee the rationality of the prediction in the arrangement of target localization and the spatial distribution of target/background regions, respectively. Our proposed network outperforms existing weakly-supervised methods on two public datasets with respect to the accuracy and robustness, improving the applicability of deep-learning based segmentation in the clinical practice of thyroid nodule diagnosis.