 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUGAE: Unified Geometry and Attribute Enhancement for G-PCC Compressed Point Clouds
Oct 27, 2025Lossy compression of point clouds reduces storage and transmission costs; however, it inevitably leads to irreversible distortion in geometry structure and attribute information. To address these issues, we propose a unified geometry and attribute enhancement (UGAE) framework, which consists of three core components: post-geometry enhancement (PoGE), pre-attribute enhancement (PAE), and post-attribute enhancement (PoAE). In PoGE, a Transformer-based sparse convolutional U-Net is used to reconstruct the geometry structure with high precision by predicting voxel occupancy probabilities. Building on the refined geometry structure, PAE introduces an innovative enhanced geometry-guided recoloring strategy, which uses a detail-aware K-Nearest Neighbors (DA-KNN) method to achieve accurate recoloring and effectively preserve high-frequency details before attribute compression. Finally, at the decoder side, PoAE uses an attribute residual prediction network with a weighted mean squared error (W-MSE) loss to enhance the quality of high-frequency regions while maintaining the fidelity of low-frequency regions. UGAE significantly outperformed existing methods on three benchmark datasets: 8iVFB, Owlii, and MVUB. Compared to the latest G-PCC test model (TMC13v29), UGAE achieved an average BD-PSNR gain of 9.98 dB and 90.98% BD-bitrate savings for geometry under the D1 metric, as well as a 3.67 dB BD-PSNR improvement with 56.88% BD-bitrate savings for attributes on the Y component. Additionally, it improved perceptual quality significantly.
Student Helping Teacher: Teacher Evolution via Self-Knowledge Distillation
Oct 13, 2021
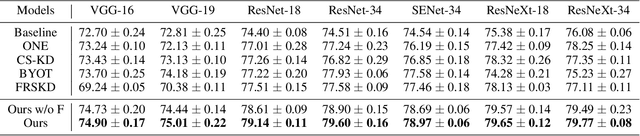
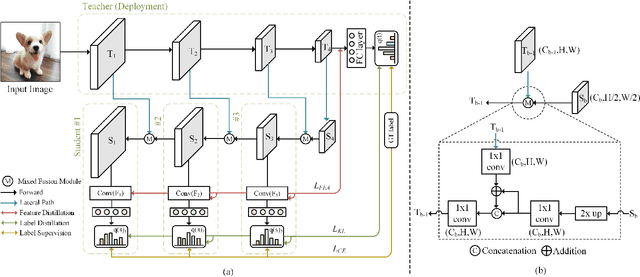
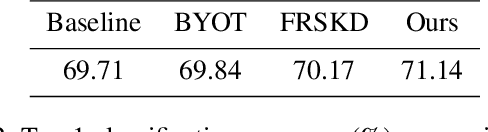
Knowledge distillation usually transfers the knowledge from a pre-trained cumbersome teacher network to a compact student network, which follows the classical teacher-teaching-student paradigm. Based on this paradigm, previous methods mostly focus on how to efficiently train a better student network for deployment. Different from the existing practices, in this paper, we propose a novel student-helping-teacher formula, Teacher Evolution via Self-Knowledge Distillation (TESKD), where the target teacher (for deployment) is learned with the help of multiple hierarchical students by sharing the structural backbone. The diverse feedback from multiple students allows the teacher to improve itself through the shared feature representations. The effectiveness of our proposed framework is demonstrated by extensive experiments with various network settings on two standard benchmarks including CIFAR-100 and ImageNet. Notably, when trained together with our proposed method, ResNet-18 achieves 79.15% and 71.14% accuracy on CIFAR-100 and ImageNet, outperforming the baseline results by 4.74% and 1.43%, respectively. The code is available at: https://github.com/zhengli427/TESKD.
Online Knowledge Distillation for Efficient Pose Estimation
Aug 04, 2021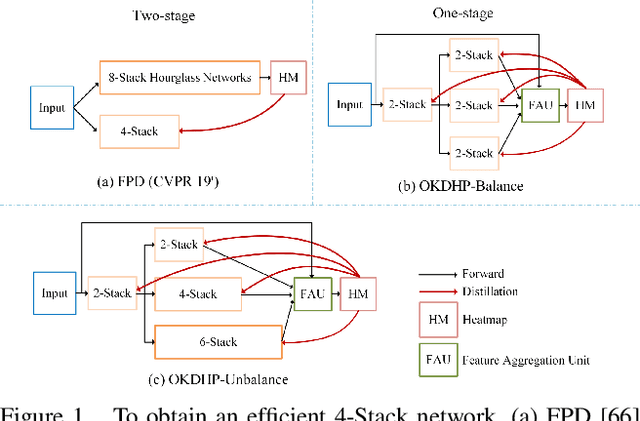
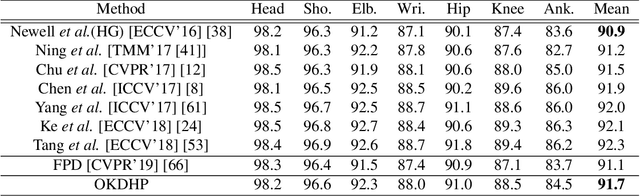
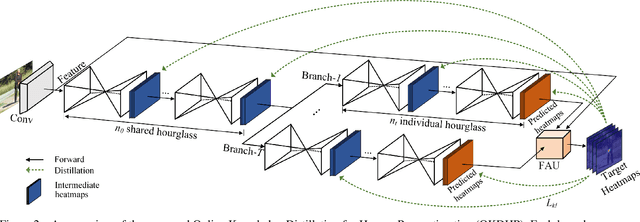
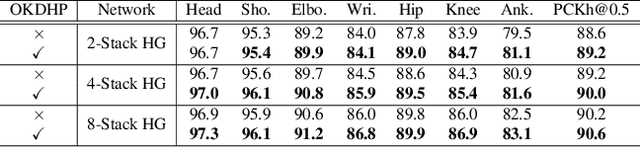
Existing state-of-the-art human pose estimation methods require heavy computational resources for accurate predictions. One promising technique to obtain an accurate yet lightweight pose estimator is knowledge distillation, which distills the pose knowledge from a powerful teacher model to a less-parameterized student model. However, existing pose distillation works rely on a heavy pre-trained estimator to perform knowledge transfer and require a complex two-stage learning procedure. In this work, we investigate a novel Online Knowledge Distillation framework by distilling Human Pose structure knowledge in a one-stage manner to guarantee the distillation efficiency, termed OKDHP. Specifically, OKDHP trains a single multi-branch network and acquires the predicted heatmaps from each, which are then assembled by a Feature Aggregation Unit (FAU) as the target heatmaps to teach each branch in reverse. Instead of simply averaging the heatmaps, FAU which consists of multiple parallel transformations with different receptive fields, leverages the multi-scale information, thus obtains target heatmaps with higher-quality. Specifically, the pixel-wise Kullback-Leibler (KL) divergence is utilized to minimize the discrepancy between the target heatmaps and the predicted ones, which enables the student network to learn the implicit keypoint relationship. Besides, an unbalanced OKDHP scheme is introduced to customize the student networks with different compression rates. The effectiveness of our approach is demonstrated by extensive experiments on two common benchmark datasets, MPII and COCO.
Online Knowledge Distillation via Multi-branch Diversity Enhancement
Oct 02, 2020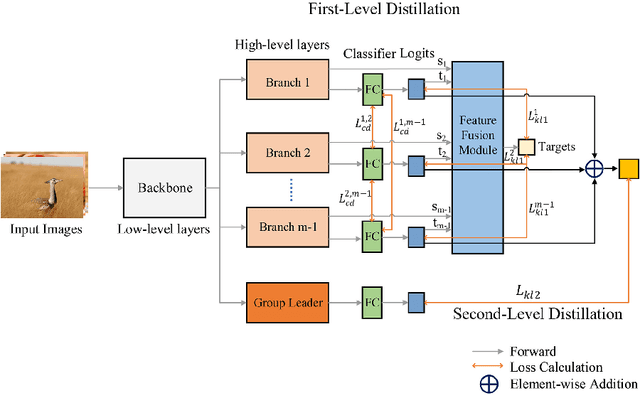
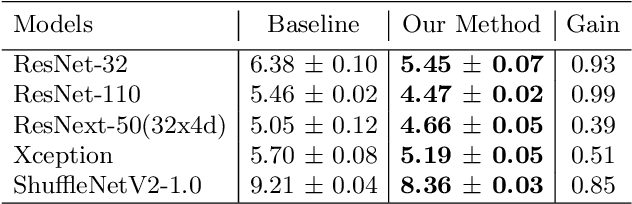
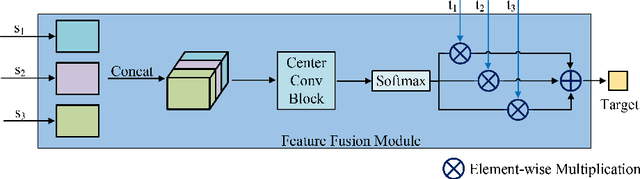
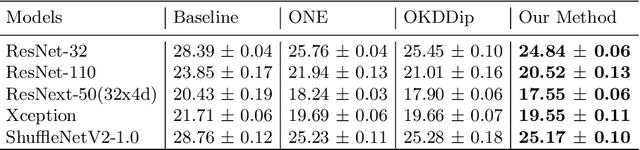
Knowledge distillation is an effective method to transfer the knowledge from the cumbersome teacher model to the lightweight student model. Online knowledge distillation uses the ensembled prediction results of multiple student models as soft targets to train each student model. However, the homogenization problem will lead to difficulty in further improving model performance. In this work, we propose a new distillation method to enhance the diversity among multiple student models. We introduce Feature Fusion Module (FFM), which improves the performance of the attention mechanism in the network by integrating rich semantic information contained in the last block of multiple student models. Furthermore, we use the Classifier Diversification(CD) loss function to strengthen the differences between the student models and deliver a better ensemble result. Extensive experiments proved that our method significantly enhances the diversity among student models and brings better distillation performance. We evaluate our method on three image classification datasets: CIFAR-10/100 and CINIC-10. The results show that our method achieves state-of-the-art performance on these datasets.