 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdSelect: Synthetic Instruction Data Selection with Multi-LLM Wisdom
Mar 03, 2025



Distilling advanced Large Language Models' instruction-following capabilities into smaller models using a selected subset has become a mainstream approach in model training. While existing synthetic instruction data selection strategies rely mainly on single-dimensional signals (i.e., reward scores, model perplexity), they fail to capture the complexity of instruction-following across diverse fields. Therefore, we investigate more diverse signals to capture comprehensive instruction-response pair characteristics and propose three foundational metrics that leverage Multi-LLM wisdom, informed by (1) diverse LLM responses and (2) reward model assessment. Building upon base metrics, we propose CrowdSelect, an integrated metric incorporating a clustering-based approach to maintain response diversity. Our comprehensive experiments demonstrate that our foundation metrics consistently improve performance across 4 base models on MT-bench and Arena-Hard. CrowdSelect, efficiently incorporating all metrics, achieves state-of-the-art performance in both Full and LoRA fine-tuning, showing improvements of 4.81% on Arena-Hard and 11.1% on MT-bench with Llama-3.2-3b-instruct. We hope our findings will bring valuable insights for future research in this direction. Code are available at https://github.com/listentm/crowdselect.
Agent-based Video Trimming
Dec 12, 2024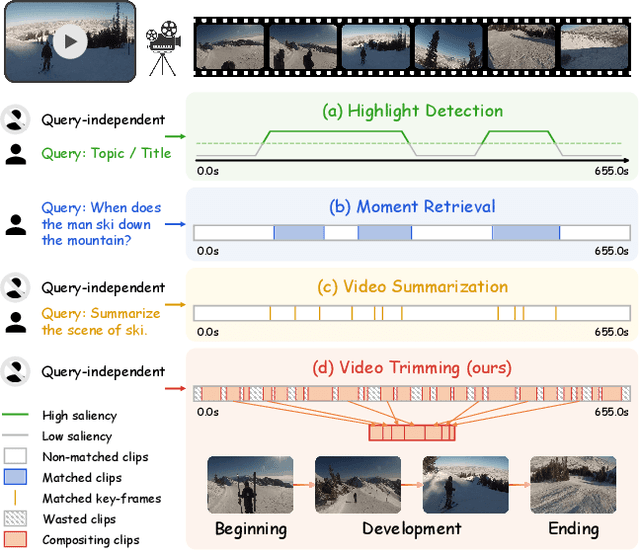
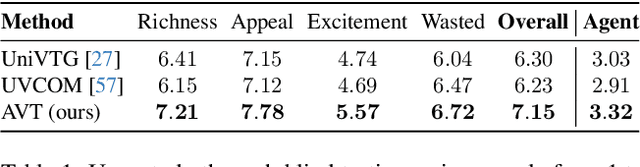
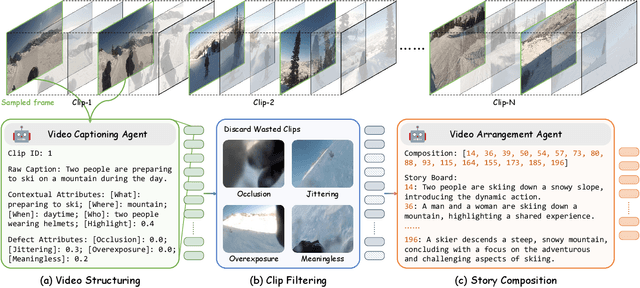
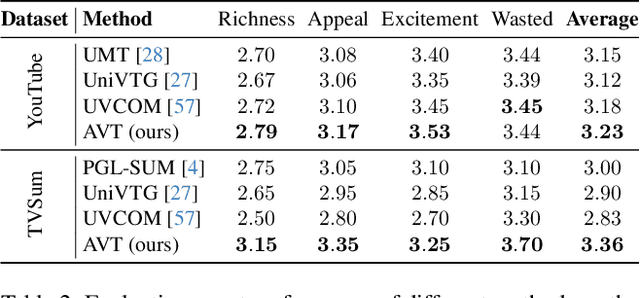
As information becomes more accessible, user-generated videos are increasing in length, placing a burden on viewers to sift through vast content for valuable insights. This trend underscores the need for an algorithm to extract key video information efficiently. Despite significant advancements in highlight detection, moment retrieval, and video summarization, current approaches primarily focus on selecting specific time intervals, often overlooking the relevance between segments and the potential for segment arranging. In this paper, we introduce a novel task called Video Trimming (VT), which focuses on detecting wasted footage, selecting valuable segments, and composing them into a final video with a coherent story. To address this task, we propose Agent-based Video Trimming (AVT), structured into three phases: Video Structuring, Clip Filtering, and Story Composition. Specifically, we employ a Video Captioning Agent to convert video slices into structured textual descriptions, a Filtering Module to dynamically discard low-quality footage based on the structured information of each clip, and a Video Arrangement Agent to select and compile valid clips into a coherent final narrative. For evaluation, we develop a Video Evaluation Agent to assess trimmed videos, conducting assessments in parallel with human evaluations. Additionally, we curate a new benchmark dataset for video trimming using raw user videos from the internet. As a result, AVT received more favorable evaluations in user studies and demonstrated superior mAP and precision on the YouTube Highlights, TVSum, and our own dataset for the highlight detection task. The code and models are available at https://ylingfeng.github.io/AVT.
SimVG: A Simple Framework for Visual Grounding with Decoupled Multi-modal Fusion
Sep 26, 2024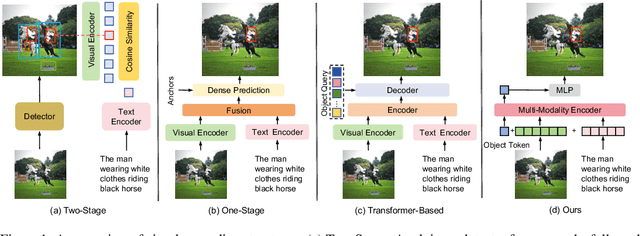
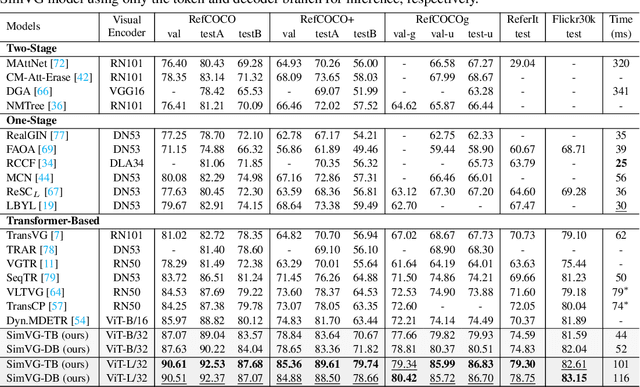
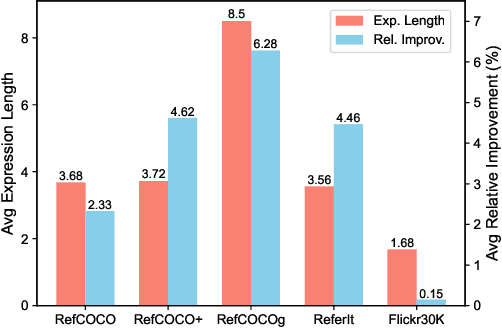
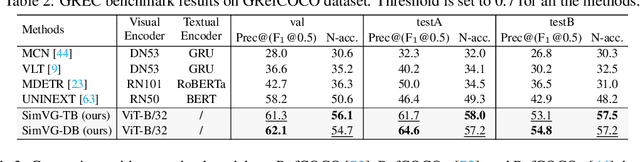
Visual grounding is a common vision task that involves grounding descriptive sentences to the corresponding regions of an image. Most existing methods use independent image-text encoding and apply complex hand-crafted modules or encoder-decoder architectures for modal interaction and query reasoning. However, their performance significantly drops when dealing with complex textual expressions. This is because the former paradigm only utilizes limited downstream data to fit the multi-modal feature fusion. Therefore, it is only effective when the textual expressions are relatively simple. In contrast, given the wide diversity of textual expressions and the uniqueness of downstream training data, the existing fusion module, which extracts multimodal content from a visual-linguistic context, has not been fully investigated. In this paper, we present a simple yet robust transformer-based framework, SimVG, for visual grounding. Specifically, we decouple visual-linguistic feature fusion from downstream tasks by leveraging existing multimodal pre-trained models and incorporating additional object tokens to facilitate deep integration of downstream and pre-training tasks. Furthermore, we design a dynamic weight-balance distillation method in the multi-branch synchronous learning process to enhance the representation capability of the simpler branch. This branch only consists of a lightweight MLP, which simplifies the structure and improves reasoning speed. Experiments on six widely used VG datasets, i.e., RefCOCO/+/g, ReferIt, Flickr30K, and GRefCOCO, demonstrate the superiority of SimVG. Finally, the proposed method not only achieves improvements in efficiency and convergence speed but also attains new state-of-the-art performance on these benchmarks. Codes and models will be available at \url{https://github.com/Dmmm1997/SimVG}.
Revisiting Prompt Pretraining of Vision-Language Models
Sep 10, 2024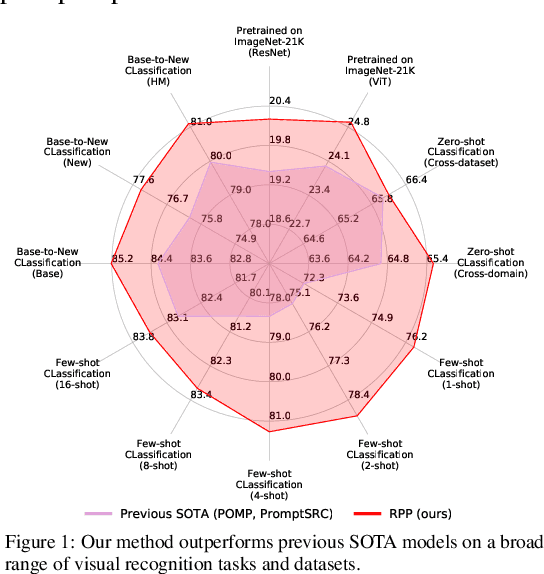

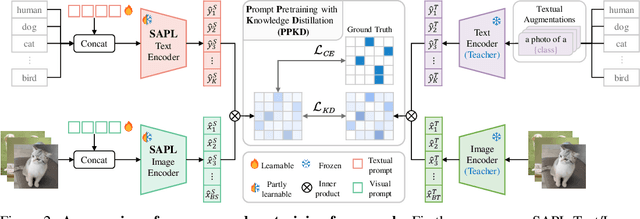
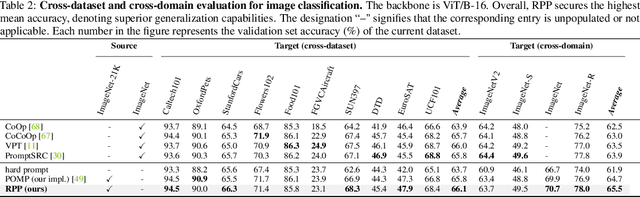
Prompt learning is an effective method to customize Vision-Language Models (VLMs) for various downstream tasks, involving tuning very few parameters of input prompt tokens. Recently, prompt pretraining in large-scale dataset (e.g., ImageNet-21K) has played a crucial role in prompt learning for universal visual discrimination. However, we revisit and observe that the limited learnable prompts could face underfitting risks given the extensive images during prompt pretraining, simultaneously leading to poor generalization. To address the above issues, in this paper, we propose a general framework termed Revisiting Prompt Pretraining (RPP), which targets at improving the fitting and generalization ability from two aspects: prompt structure and prompt supervision. For prompt structure, we break the restriction in common practice where query, key, and value vectors are derived from the shared learnable prompt token. Instead, we introduce unshared individual query, key, and value learnable prompts, thereby enhancing the model's fitting capacity through increased parameter diversity. For prompt supervision, we additionally utilize soft labels derived from zero-shot probability predictions provided by a pretrained Contrastive Language Image Pretraining (CLIP) teacher model. These soft labels yield more nuanced and general insights into the inter-class relationships, thereby endowing the pretraining process with better generalization ability. RPP produces a more resilient prompt initialization, enhancing its robust transferability across diverse visual recognition tasks. Experiments across various benchmarks consistently confirm the state-of-the-art (SOTA) performance of our pretrained prompts. Codes and models will be made available soon.
Add-SD: Rational Generation without Manual Reference
Jul 30, 2024



Diffusion models have exhibited remarkable prowess in visual generalization. Building on this success, we introduce an instruction-based object addition pipeline, named Add-SD, which automatically inserts objects into realistic scenes with rational sizes and positions. Different from layout-conditioned methods, Add-SD is solely conditioned on simple text prompts rather than any other human-costly references like bounding boxes. Our work contributes in three aspects: proposing a dataset containing numerous instructed image pairs; fine-tuning a diffusion model for rational generation; and generating synthetic data to boost downstream tasks. The first aspect involves creating a RemovalDataset consisting of original-edited image pairs with textual instructions, where an object has been removed from the original image while maintaining strong pixel consistency in the background. These data pairs are then used for fine-tuning the Stable Diffusion (SD) model. Subsequently, the pretrained Add-SD model allows for the insertion of expected objects into an image with good rationale. Additionally, we generate synthetic instances for downstream task datasets at scale, particularly for tail classes, to alleviate the long-tailed problem. Downstream tasks benefit from the enriched dataset with enhanced diversity and rationale. Experiments on LVIS val demonstrate that Add-SD yields an improvement of 4.3 mAP on rare classes over the baseline. Code and models are available at https://github.com/ylingfeng/Add-SD.
Fine-Grained Visual Prompting
Jun 07, 2023
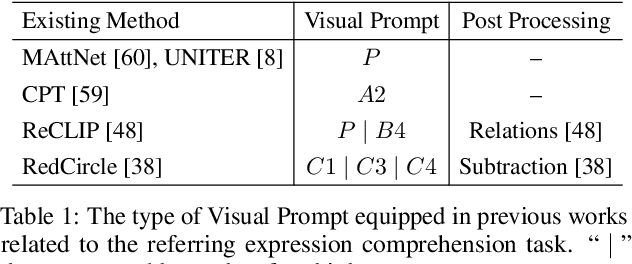
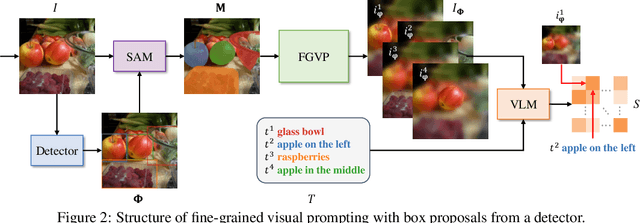
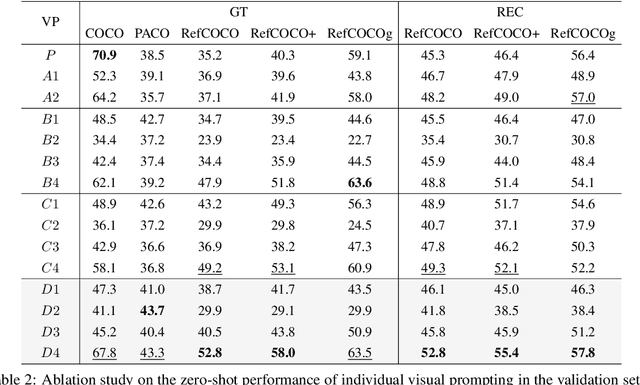
Vision-Language Models (VLMs), such as CLIP, have demonstrated impressive zero-shot transfer capabilities in image-level visual perception. However, these models have shown limited performance in instance-level tasks that demand precise localization and recognition. Previous works have suggested that incorporating visual prompts, such as colorful boxes or circles, can improve the ability of models to recognize objects of interest. Nonetheless, compared to language prompting, visual prompting designs are rarely explored. Existing approaches, which employ coarse visual cues such as colorful boxes or circles, often result in sub-optimal performance due to the inclusion of irrelevant and noisy pixels. In this paper, we carefully study the visual prompting designs by exploring more fine-grained markings, such as segmentation masks and their variations. In addition, we introduce a new zero-shot framework that leverages pixel-level annotations acquired from a generalist segmentation model for fine-grained visual prompting. Consequently, our investigation reveals that a straightforward application of blur outside the target mask, referred to as the Blur Reverse Mask, exhibits exceptional effectiveness. This proposed prompting strategy leverages the precise mask annotations to reduce focus on weakly related regions while retaining spatial coherence between the target and the surrounding background. Our Fine-Grained Visual Prompting (FGVP) demonstrates superior performance in zero-shot comprehension of referring expressions on the RefCOCO, RefCOCO+, and RefCOCOg benchmarks. It outperforms prior methods by an average margin of 3.0% to 4.6%, with a maximum improvement of 12.5% on the RefCOCO+ testA subset. The part detection experiments conducted on the PACO dataset further validate the preponderance of FGVP over existing visual prompting techniques. Code and models will be made available.
A Survey of Historical Learning: Learning Models with Learning History
Mar 23, 2023



New knowledge originates from the old. The various types of elements, deposited in the training history, are a large amount of wealth for improving learning deep models. In this survey, we comprehensively review and summarize the topic--``Historical Learning: Learning Models with Learning History'', which learns better neural models with the help of their learning history during its optimization, from three detailed aspects: Historical Type (what), Functional Part (where) and Storage Form (how). To our best knowledge, it is the first survey that systematically studies the methodologies which make use of various historical statistics when training deep neural networks. The discussions with related topics like recurrent/memory networks, ensemble learning, and reinforcement learning are demonstrated. We also expose future challenges of this topic and encourage the community to pay attention to the think of historical learning principles when designing algorithms. The paper list related to historical learning is available at \url{https://github.com/Martinser/Awesome-Historical-Learning.}
Curriculum Temperature for Knowledge Distillation
Dec 04, 2022



Most existing distillation methods ignore the flexible role of the temperature in the loss function and fix it as a hyper-parameter that can be decided by an inefficient grid search. In general, the temperature controls the discrepancy between two distributions and can faithfully determine the difficulty level of the distillation task. Keeping a constant temperature, i.e., a fixed level of task difficulty, is usually sub-optimal for a growing student during its progressive learning stages. In this paper, we propose a simple curriculum-based technique, termed Curriculum Temperature for Knowledge Distillation (CTKD), which controls the task difficulty level during the student's learning career through a dynamic and learnable temperature. Specifically, following an easy-to-hard curriculum, we gradually increase the distillation loss w.r.t. the temperature, leading to increased distillation difficulty in an adversarial manner. As an easy-to-use plug-in technique, CTKD can be seamlessly integrated into existing knowledge distillation frameworks and brings general improvements at a negligible additional computation cost. Extensive experiments on CIFAR-100, ImageNet-2012, and MS-COCO demonstrate the effectiveness of our method. Our code is available at https://github.com/zhengli97/CTKD.
Uniform Masking: Enabling MAE Pre-training for Pyramid-based Vision Transformers with Locality
May 20, 2022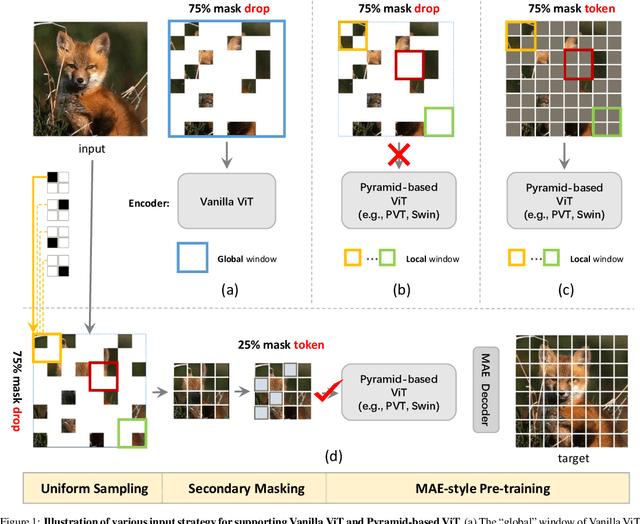
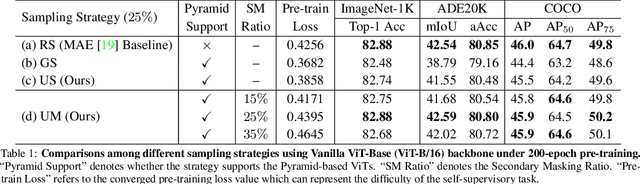
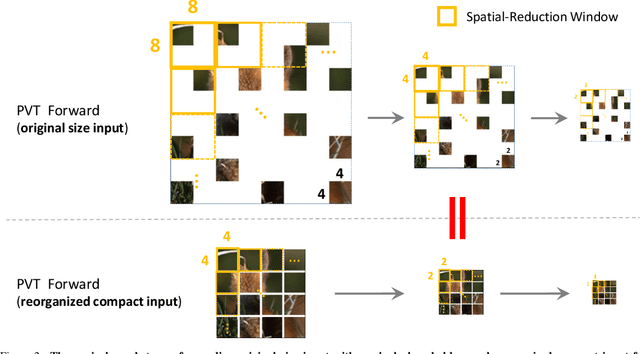
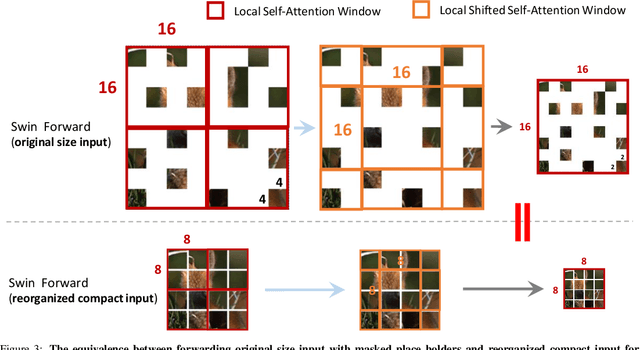
Masked AutoEncoder (MAE) has recently led the trends of visual self-supervision area by an elegant asymmetric encoder-decoder design, which significantly optimizes both the pre-training efficiency and fine-tuning accuracy. Notably, the success of the asymmetric structure relies on the "global" property of Vanilla Vision Transformer (ViT), whose self-attention mechanism reasons over arbitrary subset of discrete image patches. However, it is still unclear how the advanced Pyramid-based ViTs (e.g., PVT, Swin) can be adopted in MAE pre-training as they commonly introduce operators within "local" windows, making it difficult to handle the random sequence of partial vision tokens. In this paper, we propose Uniform Masking (UM), successfully enabling MAE pre-training for Pyramid-based ViTs with locality (termed "UM-MAE" for short). Specifically, UM includes a Uniform Sampling (US) that strictly samples $1$ random patch from each $2 \times 2$ grid, and a Secondary Masking (SM) which randomly masks a portion of (usually $25\%$) the already sampled regions as learnable tokens. US preserves equivalent elements across multiple non-overlapped local windows, resulting in the smooth support for popular Pyramid-based ViTs; whilst SM is designed for better transferable visual representations since US reduces the difficulty of pixel recovery pre-task that hinders the semantic learning. We demonstrate that UM-MAE significantly improves the pre-training efficiency (e.g., it speeds up and reduces the GPU memory by $\sim 2\times$) of Pyramid-based ViTs, but maintains the competitive fine-tuning performance across downstream tasks. For example using HTC++ detector, the pre-trained Swin-Large backbone self-supervised under UM-MAE only in ImageNet-1K can even outperform the one supervised in ImageNet-22K. The codes are available at https://github.com/implus/UM-MAE.
RecursiveMix: Mixed Learning with History
Mar 14, 2022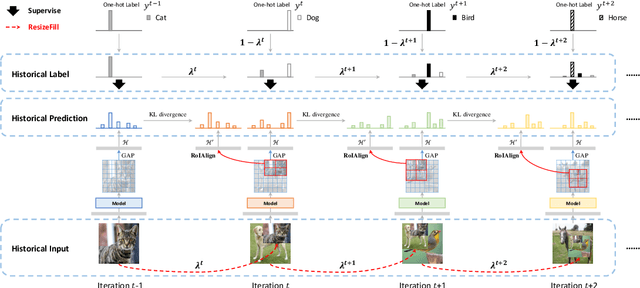
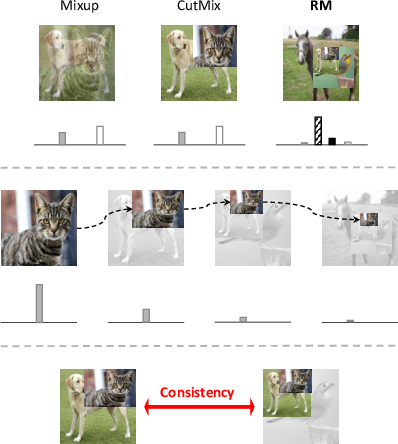
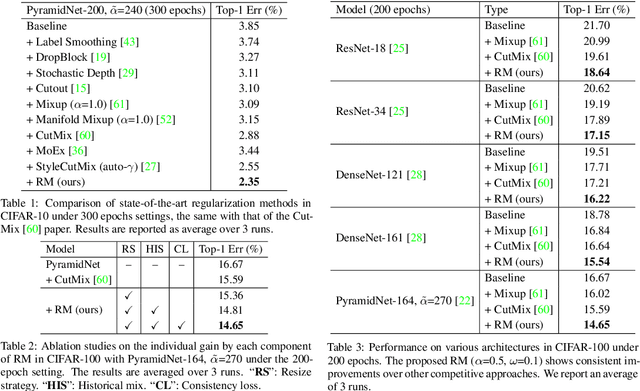
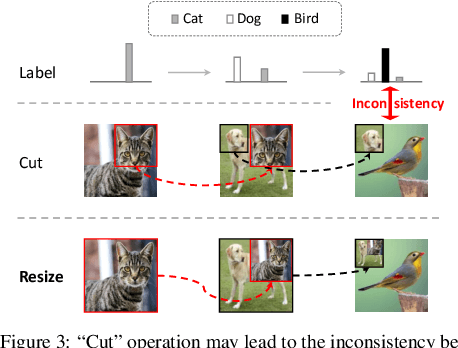
Mix-based augmentation has been proven fundamental to the generalization of deep vision models. However, current augmentations only mix samples at the current data batch during training, which ignores the possible knowledge accumulated in the learning history. In this paper, we propose a recursive mixed-sample learning paradigm, termed "RecursiveMix" (RM), by exploring a novel training strategy that leverages the historical input-prediction-label triplets. More specifically, we iteratively resize the input image batch from the previous iteration and paste it into the current batch while their labels are fused proportionally to the area of the operated patches. Further, a consistency loss is introduced to align the identical image semantics across the iterations, which helps the learning of scale-invariant feature representations. Based on ResNet-50, RM largely improves classification accuracy by $\sim$3.2\% on CIFAR100 and $\sim$2.8\% on ImageNet with negligible extra computation/storage costs. In the downstream object detection task, the RM pretrained model outperforms the baseline by 2.1 AP points and surpasses CutMix by 1.4 AP points under the ATSS detector on COCO. In semantic segmentation, RM also surpasses the baseline and CutMix by 1.9 and 1.1 mIoU points under UperNet on ADE20K, respectively. Codes and pretrained models are available at \url{https://github.com/megvii-research/RecursiveMix}.