 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalSUG: Geography-Aware LLM for Query Suggestion in Local-Life Services
Mar 05, 2026In local-life service platforms, the query suggestion module plays a crucial role in enhancing user experience by generating candidate queries based on user input prefixes, thus reducing user effort and accelerating search. Traditional multi-stage cascading systems rely heavily on historical top queries, limiting their ability to address long-tail demand. While LLMs offer strong semantic generalization, deploying them in local-life services introduces three key challenges: lack of geographic grounding, exposure bias in preference optimization, and online inference latency. To address these issues, we propose LocalSUG, an LLM-based query suggestion framework tailored for local-life service platforms. First, we introduce a city-aware candidate mining strategy based on term co-occurrence to inject geographic grounding into generation. Second, we propose a beam-search-driven GRPO algorithm that aligns training with inference-time decoding, reducing exposure bias in autoregressive generation. A multi-objective reward mechanism further optimizes both relevance and business-oriented metrics. Finally, we develop quality-aware beam acceleration and vocabulary pruning techniques that significantly reduce online latency while preserving generation quality. Extensive offline evaluations and large-scale online A/B testing demonstrate that LocalSUG improves click-through rate (CTR) by +0.35% and reduces the low/no-result rate by 2.56%, validating its effectiveness in real-world deployment.
Detecting Stealthy Backdoor Samples based on Intra-class Distance for Large Language Models
May 29, 2025



Fine-tuning LLMs with datasets containing stealthy backdoors from publishers poses security risks to downstream applications. Mainstream detection methods either identify poisoned samples by analyzing the prediction probability of poisoned classification models or rely on the rewriting model to eliminate the stealthy triggers. However, the former cannot be applied to generation tasks, while the latter may degrade generation performance and introduce new triggers. Therefore, efficiently eliminating stealthy poisoned samples for LLMs remains an urgent problem. We observe that after applying TF-IDF clustering to the sample response, there are notable differences in the intra-class distances between clean and poisoned samples. Poisoned samples tend to cluster closely because of their specific malicious outputs, whereas clean samples are more scattered due to their more varied responses. Thus, in this paper, we propose a stealthy backdoor sample detection method based on Reference-Filtration and Tfidf-Clustering mechanisms (RFTC). Specifically, we first compare the sample response with the reference model's outputs and consider the sample suspicious if there's a significant discrepancy. And then we perform TF-IDF clustering on these suspicious samples to identify the true poisoned samples based on the intra-class distance. Experiments on two machine translation datasets and one QA dataset demonstrate that RFTC outperforms baselines in backdoor detection and model performance. Further analysis of different reference models also confirms the effectiveness of our Reference-Filtration.
Finding Counterfactual Evidences for Node Classification
May 16, 2025Counterfactual learning is emerging as an important paradigm, rooted in causality, which promises to alleviate common issues of graph neural networks (GNNs), such as fairness and interpretability. However, as in many real-world application domains where conducting randomized controlled trials is impractical, one has to rely on available observational (factual) data to detect counterfactuals. In this paper, we introduce and tackle the problem of searching for counterfactual evidences for the GNN-based node classification task. A counterfactual evidence is a pair of nodes such that, regardless they exhibit great similarity both in the features and in their neighborhood subgraph structures, they are classified differently by the GNN. We develop effective and efficient search algorithms and a novel indexing solution that leverages both node features and structural information to identify counterfactual evidences, and generalizes beyond any specific GNN. Through various downstream applications, we demonstrate the potential of counterfactual evidences to enhance fairness and accuracy of GNNs.
DATA-WA: Demand-based Adaptive Task Assignment with Dynamic Worker Availability Windows
Mar 27, 2025With the rapid advancement of mobile networks and the widespread use of mobile devices, spatial crowdsourcing, which involves assigning location-based tasks to mobile workers, has gained significant attention. However, most existing research focuses on task assignment at the current moment, overlooking the fluctuating demand and supply between tasks and workers over time. To address this issue, we introduce an adaptive task assignment problem, which aims to maximize the number of assigned tasks by dynamically adjusting task assignments in response to changing demand and supply. We develop a spatial crowdsourcing framework, namely demand-based adaptive task assignment with dynamic worker availability windows, which consists of two components including task demand prediction and task assignment. In the first component, we construct a graph adjacency matrix representing the demand dependency relationships in different regions and employ a multivariate time series learning approach to predict future task demands. In the task assignment component, we adjust tasks to workers based on these predictions, worker availability windows, and the current task assignments, where each worker has an availability window that indicates the time periods they are available for task assignments. To reduce the search space of task assignments and be efficient, we propose a worker dependency separation approach based on graph partition and a task value function with reinforcement learning. Experiments on real data demonstrate that our proposals are both effective and efficient.
Add-SD: Rational Generation without Manual Reference
Jul 30, 2024



Diffusion models have exhibited remarkable prowess in visual generalization. Building on this success, we introduce an instruction-based object addition pipeline, named Add-SD, which automatically inserts objects into realistic scenes with rational sizes and positions. Different from layout-conditioned methods, Add-SD is solely conditioned on simple text prompts rather than any other human-costly references like bounding boxes. Our work contributes in three aspects: proposing a dataset containing numerous instructed image pairs; fine-tuning a diffusion model for rational generation; and generating synthetic data to boost downstream tasks. The first aspect involves creating a RemovalDataset consisting of original-edited image pairs with textual instructions, where an object has been removed from the original image while maintaining strong pixel consistency in the background. These data pairs are then used for fine-tuning the Stable Diffusion (SD) model. Subsequently, the pretrained Add-SD model allows for the insertion of expected objects into an image with good rationale. Additionally, we generate synthetic instances for downstream task datasets at scale, particularly for tail classes, to alleviate the long-tailed problem. Downstream tasks benefit from the enriched dataset with enhanced diversity and rationale. Experiments on LVIS val demonstrate that Add-SD yields an improvement of 4.3 mAP on rare classes over the baseline. Code and models are available at https://github.com/ylingfeng/Add-SD.
Layered Rendering Diffusion Model for Zero-Shot Guided Image Synthesis
Nov 30, 2023This paper introduces innovative solutions to enhance spatial controllability in diffusion models reliant on text queries. We present two key innovations: Vision Guidance and the Layered Rendering Diffusion (LRDiff) framework. Vision Guidance, a spatial layout condition, acts as a clue in the perturbed distribution, greatly narrowing down the search space, to focus on the image sampling process adhering to the spatial layout condition. The LRDiff framework constructs an image-rendering process with multiple layers, each of which applies the vision guidance to instructively estimate the denoising direction for a single object. Such a layered rendering strategy effectively prevents issues like unintended conceptual blending or mismatches, while allowing for more coherent and contextually accurate image synthesis. The proposed method provides a more efficient and accurate means of synthesising images that align with specific spatial and contextual requirements. We demonstrate through our experiments that our method provides better results than existing techniques both quantitatively and qualitatively. We apply our method to three practical applications: bounding box-to-image, semantic mask-to-image and image editing.
UFO: Unified Feature Optimization
Jul 21, 2022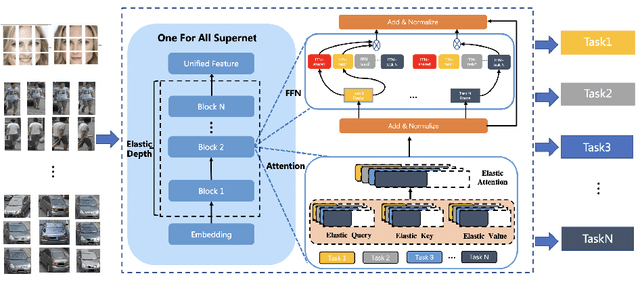
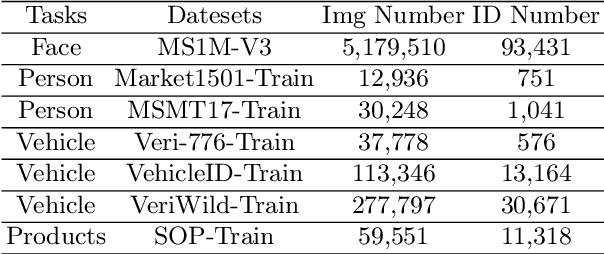
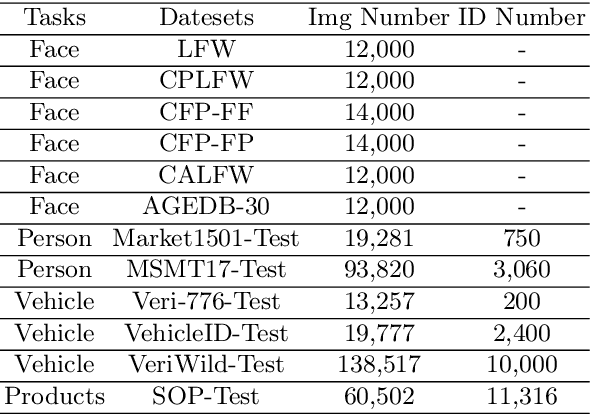
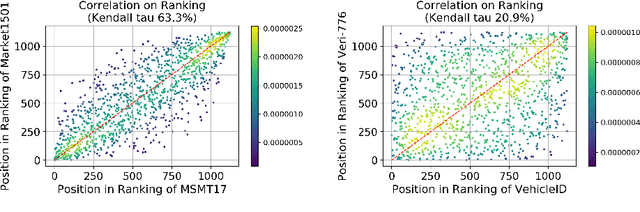
This paper proposes a novel Unified Feature Optimization (UFO) paradigm for training and deploying deep models under real-world and large-scale scenarios, which requires a collection of multiple AI functions. UFO aims to benefit each single task with a large-scale pretraining on all tasks. Compared with the well known foundation model, UFO has two different points of emphasis, i.e., relatively smaller model size and NO adaptation cost: 1) UFO squeezes a wide range of tasks into a moderate-sized unified model in a multi-task learning manner and further trims the model size when transferred to down-stream tasks. 2) UFO does not emphasize transfer to novel tasks. Instead, it aims to make the trimmed model dedicated for one or more already-seen task. With these two characteristics, UFO provides great convenience for flexible deployment, while maintaining the benefits of large-scale pretraining. A key merit of UFO is that the trimming process not only reduces the model size and inference consumption, but also even improves the accuracy on certain tasks. Specifically, UFO considers the multi-task training and brings two-fold impact on the unified model: some closely related tasks have mutual benefits, while some tasks have conflicts against each other. UFO manages to reduce the conflicts and to preserve the mutual benefits through a novel Network Architecture Search (NAS) method. Experiments on a wide range of deep representation learning tasks (i.e., face recognition, person re-identification, vehicle re-identification and product retrieval) show that the model trimmed from UFO achieves higher accuracy than its single-task-trained counterpart and yet has smaller model size, validating the concept of UFO. Besides, UFO also supported the release of 17 billion parameters computer vision (CV) foundation model which is the largest CV model in the industry.