 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM+Graph@VLDB'2025 Workshop Summary
Apr 03, 2026The integration of large language models (LLMs) with graph-structured data has become a pivotal and fast evolving research frontier, drawing strong interest from both academia and industry. The 2nd LLM+Graph Workshop, co-located with the 51st International Conference on Very Large Data Bases (VLDB 2025) in London, focused on advancing algorithms and systems that bridge LLMs, graph data management, and graph machine learning for practical applications. This report highlights the key research directions, challenges, and innovative solutions presented by the workshop's speakers.
Tipping the Balance: Impact of Class Imbalance Correction on the Performance of Clinical Risk Prediction Models
Feb 27, 2026Objective: ML-based clinical risk prediction models are increasingly used to support decision-making in healthcare. While class-imbalance correction techniques are commonly applied to improve model performance in settings with rare outcomes, their impact on probabilistic calibration remains insufficiently understood. This study evaluated the effect of widely used resampling strategies on both discrimination and calibration across real-world clinical prediction tasks. Methods: Ten clinical datasets spanning diverse medical domains and including 605,842 patients were analyzed. Multiple machine-learning model families, including linear models and several non-linear approaches, were evaluated. Models were trained on the original data and under three commonly used 1:1 class-imbalance correction strategies (SMOTE, RUS, ROS). Performance was assessed on held-out data using discrimination and calibration metrics. Results: Across all datasets and model families, resampling had no positive impact on predictive performance. Changes in the Receiver Operating Characteristic Area Under Curve (ROC-AUC) relative to models trained on the original data were small and inconsistent (ROS: -0.002, p<0.05; RUS: -0.004, p>0.05; SMOTE: -0.01, p<0.05), with no resampling strategy demonstrating a systematic improvement. In contrast, resampling in general degraded the calibration performance. Models trained using imbalance correction exhibited higher Brier scores (0.029 to 0.080, p<0.05), reflecting poorer probabilistic accuracy, and marked deviations in calibration intercept and slope, indicating systematic distortions of predicted risk despite preserved rank-based performance. Conclusion: In a diverse set of real-world clinical prediction tasks, commonly used class-imbalance correction techniques did not provide generalizable improvements in discrimination and were associated with degraded calibration.
ATEX-CF: Attack-Informed Counterfactual Explanations for Graph Neural Networks
Feb 05, 2026Counterfactual explanations offer an intuitive way to interpret graph neural networks (GNNs) by identifying minimal changes that alter a model's prediction, thereby answering "what must differ for a different outcome?". In this work, we propose a novel framework, ATEX-CF that unifies adversarial attack techniques with counterfactual explanation generation-a connection made feasible by their shared goal of flipping a node's prediction, yet differing in perturbation strategy: adversarial attacks often rely on edge additions, while counterfactual methods typically use deletions. Unlike traditional approaches that treat explanation and attack separately, our method efficiently integrates both edge additions and deletions, grounded in theory, leveraging adversarial insights to explore impactful counterfactuals. In addition, by jointly optimizing fidelity, sparsity, and plausibility under a constrained perturbation budget, our method produces instance-level explanations that are both informative and realistic. Experiments on synthetic and real-world node classification benchmarks demonstrate that ATEX-CF generates faithful, concise, and plausible explanations, highlighting the effectiveness of integrating adversarial insights into counterfactual reasoning for GNNs.
Cost-Efficient RAG for Entity Matching with LLMs: A Blocking-based Exploration
Feb 05, 2026Retrieval-augmented generation (RAG) enhances LLM reasoning in knowledge-intensive tasks, but existing RAG pipelines incur substantial retrieval and generation overhead when applied to large-scale entity matching. To address this limitation, we introduce CE-RAG4EM, a cost-efficient RAG architecture that reduces computation through blocking-based batch retrieval and generation. We also present a unified framework for analyzing and evaluating RAG systems for entity matching, focusing on blocking-aware optimizations and retrieval granularity. Extensive experiments suggest that CE-RAG4EM can achieve comparable or improved matching quality while substantially reducing end-to-end runtime relative to strong baselines. Our analysis further reveals that key configuration parameters introduce an inherent trade-off between performance and overhead, offering practical guidance for designing efficient and scalable RAG systems for entity matching and data integration.
Finding Counterfactual Evidences for Node Classification
May 16, 2025Counterfactual learning is emerging as an important paradigm, rooted in causality, which promises to alleviate common issues of graph neural networks (GNNs), such as fairness and interpretability. However, as in many real-world application domains where conducting randomized controlled trials is impractical, one has to rely on available observational (factual) data to detect counterfactuals. In this paper, we introduce and tackle the problem of searching for counterfactual evidences for the GNN-based node classification task. A counterfactual evidence is a pair of nodes such that, regardless they exhibit great similarity both in the features and in their neighborhood subgraph structures, they are classified differently by the GNN. We develop effective and efficient search algorithms and a novel indexing solution that leverages both node features and structural information to identify counterfactual evidences, and generalizes beyond any specific GNN. Through various downstream applications, we demonstrate the potential of counterfactual evidences to enhance fairness and accuracy of GNNs.
Generating Skyline Explanations for Graph Neural Networks
May 12, 2025This paper proposes a novel approach to generate subgraph explanations for graph neural networks GNNs that simultaneously optimize multiple measures for explainability. Existing GNN explanation methods often compute subgraphs (called ``explanatory subgraphs'') that optimize a pre-defined, single explainability measure, such as fidelity or conciseness. This can lead to biased explanations that cannot provide a comprehensive explanation to clarify the output of GNN models. We introduce skyline explanation, a GNN explanation paradigm that aims to identify k explanatory subgraphs by simultaneously optimizing multiple explainability measures. (1) We formulate skyline explanation generation as a multi-objective optimization problem, and pursue explanations that approximate a skyline set of explanatory subgraphs. We show the hardness for skyline explanation generation. (2) We design efficient algorithms with an onion-peeling approach that strategically removes edges from neighbors of nodes of interests, and incrementally improves explanations as it explores an interpretation domain, with provable quality guarantees. (3) We further develop an algorithm to diversify explanations to provide more comprehensive perspectives. Using real-world graphs, we empirically verify the effectiveness, efficiency, and scalability of our algorithms.
CoT-RAG: Integrating Chain of Thought and Retrieval-Augmented Generation to Enhance Reasoning in Large Language Models
Apr 18, 2025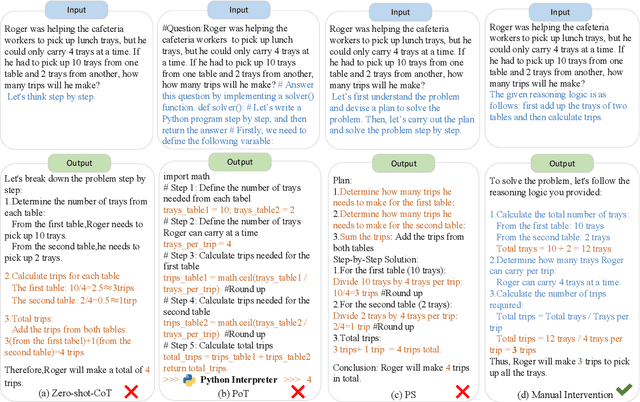

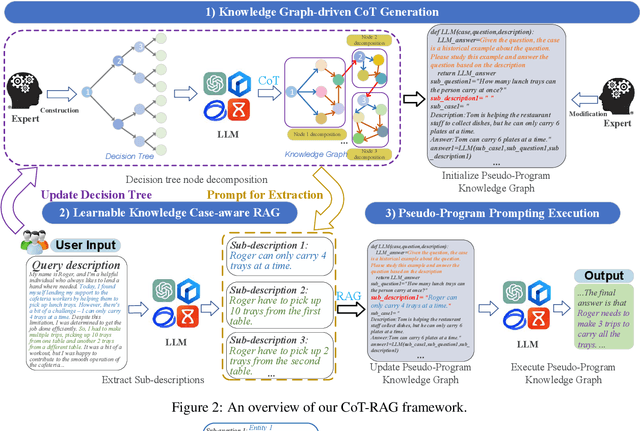

While chain-of-thought (CoT) reasoning improves the performance of large language models (LLMs) in complex tasks, it still has two main challenges: the low reliability of relying solely on LLMs to generate reasoning chains and the interference of natural language reasoning chains on the inference logic of LLMs. To address these issues, we propose CoT-RAG, a novel reasoning framework with three key designs: (i) Knowledge Graph-driven CoT Generation, featuring knowledge graphs to modulate reasoning chain generation of LLMs, thereby enhancing reasoning credibility; (ii) Learnable Knowledge Case-aware RAG, which incorporates retrieval-augmented generation (RAG) into knowledge graphs to retrieve relevant sub-cases and sub-descriptions, providing LLMs with learnable information; (iii) Pseudo-Program Prompting Execution, which encourages LLMs to execute reasoning tasks in pseudo-programs with greater logical rigor. We conduct a comprehensive evaluation on nine public datasets, covering three reasoning problems. Compared with the-state-of-the-art methods, CoT-RAG exhibits a significant accuracy improvement, ranging from 4.0% to 23.0%. Furthermore, testing on four domain-specific datasets, CoT-RAG shows remarkable accuracy and efficient execution, highlighting its strong practical applicability and scalability.
Knowledge Graph-based Retrieval-Augmented Generation for Schema Matching
Jan 15, 2025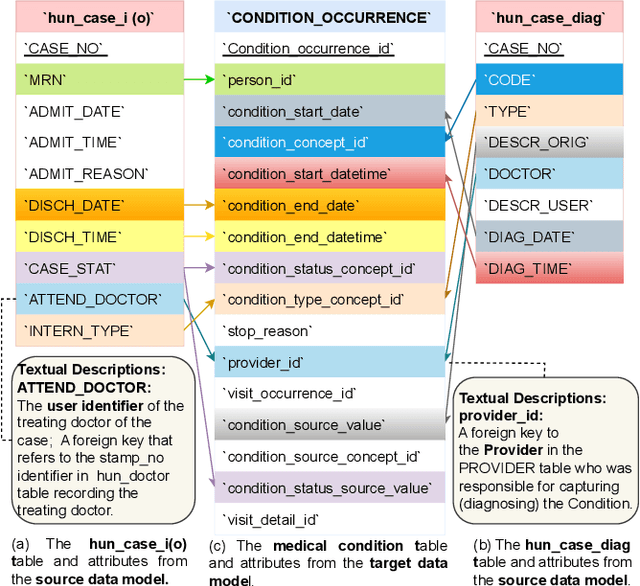
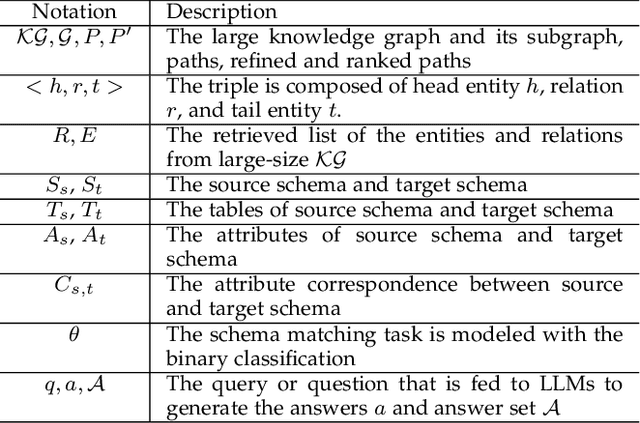
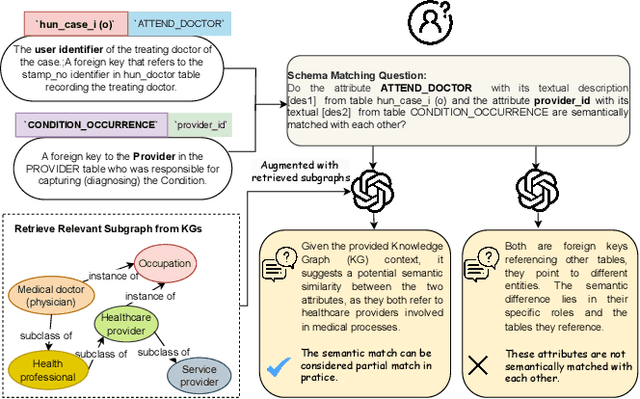
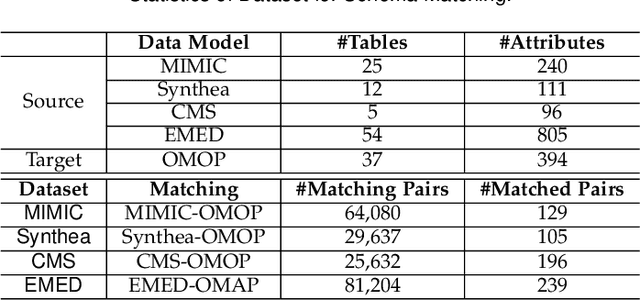
Traditional similarity-based schema matching methods are incapable of resolving semantic ambiguities and conflicts in domain-specific complex mapping scenarios due to missing commonsense and domain-specific knowledge. The hallucination problem of large language models (LLMs) also makes it challenging for LLM-based schema matching to address the above issues. Therefore, we propose a Knowledge Graph-based Retrieval-Augmented Generation model for Schema Matching, referred to as the KG-RAG4SM. In particular, KG-RAG4SM introduces novel vector-based, graph traversal-based, and query-based graph retrievals, as well as a hybrid approach and ranking schemes that identify the most relevant subgraphs from external large knowledge graphs (KGs). We showcase that KG-based retrieval-augmented LLMs are capable of generating more accurate results for complex matching cases without any re-training. Our experimental results show that KG-RAG4SM outperforms the LLM-based state-of-the-art (SOTA) methods (e.g., Jellyfish-8B) by 35.89% and 30.50% in terms of precision and F1 score on the MIMIC dataset, respectively; KG-RAG4SM with GPT-4o-mini outperforms the pre-trained language model (PLM)-based SOTA methods (e.g., SMAT) by 69.20% and 21.97% in terms of precision and F1 score on the Synthea dataset, respectively. The results also demonstrate that our approach is more efficient in end-to-end schema matching, and scales to retrieve from large KGs. Our case studies on the dataset from the real-world schema matching scenario exhibit that the hallucination problem of LLMs for schema matching is well mitigated by our solution.
Logical Consistency of Large Language Models in Fact-checking
Dec 20, 2024In recent years, large language models (LLMs) have demonstrated significant success in performing varied natural language tasks such as language translation, question-answering, summarizing, fact-checking, etc. Despite LLMs' impressive ability to generate human-like texts, LLMs are infamous for their inconsistent responses -- a meaning-preserving change in the input query results in an inconsistent response and attributes to vulnerabilities of LLMs such as hallucination, jailbreaking, etc. Consequently, existing research focuses on simple paraphrasing-based consistency assessment of LLMs, and ignores complex queries that necessitates an even better understanding of logical reasoning by an LLM. Our work therefore addresses the logical inconsistency of LLMs under complex logical queries with primitive logical operators, e.g., negation, conjunction, and disjunction. As a test bed, we consider retrieval-augmented LLMs on a fact-checking task involving propositional logic queries from real-world knowledge graphs (KGs). Our contributions are three-fold. Benchmark: We introduce three logical fact-checking datasets over KGs for community development towards logically consistent LLMs. Assessment: We propose consistency measures of LLMs on propositional logic queries as input and demonstrate that existing LLMs lack logical consistency, specially on complex queries. Improvement: We employ supervised fine-tuning to improve the logical consistency of LLMs on the complex fact-checking task with KG contexts.
Enhancing Glucose Level Prediction of ICU Patients through Irregular Time-Series Analysis and Integrated Representation
Nov 03, 2024



Accurately predicting blood glucose (BG) levels of ICU patients is critical, as both hypoglycemia (BG < 70 mg/dL) and hyperglycemia (BG > 180 mg/dL) are associated with increased morbidity and mortality. We develop the Multi-source Irregular Time-Series Transformer (MITST), a novel machine learning-based model to forecast the next BG level, classifying it into hypoglycemia, hyperglycemia, or euglycemia (70-180 mg/dL). The irregularity and complexity of Electronic Health Record (EHR) data, spanning multiple heterogeneous clinical sources like lab results, medications, and vital signs, pose significant challenges for prediction tasks. MITST addresses these using hierarchical Transformer architectures, which include a feature-level, a timestamp-level, and a source-level Transformer. This design captures fine-grained temporal dynamics and allows learning-based data integration instead of traditional predefined aggregation. In a large-scale evaluation using the eICU database (200,859 ICU stays across 208 hospitals), MITST achieves an average improvement of 1.7% (p < 0.001) in AUROC and 1.8% (p < 0.001) in AUPRC over a state-of-the-art baseline. For hypoglycemia, MITST achieves an AUROC of 0.915 and an AUPRC of 0.247, both significantly higher than the baseline's AUROC of 0.862 and AUPRC of 0.208 (p < 0.001). The flexible architecture of MITST allows seamless integration of new data sources without retraining the entire model, enhancing its adaptability in clinical decision support. Although this study focuses on predicting BG levels, MITST can easily be extended to other critical event prediction tasks in ICU settings, offering a robust solution for analyzing complex, multi-source, irregular time-series data.