 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisiFold: Long-Term Traffic Forecasting via Temporal Folding Graph and Node Visibility
Mar 12, 2026Traffic forecasting is a cornerstone of intelligent transportation systems. While existing research has made significant progress in short-term prediction, long-term forecasting remains a largely uncharted and challenging frontier. Extending the prediction horizon intensifies two critical issues: escalating computational resource consumption and increasingly complex spatial-temporal dependencies. Current approaches, which rely on spatial-temporal graphs and process temporal and spatial dimensions separately, suffer from snapshot-stacking inflation and cross-step fragmentation. To overcome these limitations, we propose \textit{VisiFold}. Our framework introduces a novel temporal folding graph that consolidates a sequence of temporal snapshots into a single graph. Furthermore, we present a node visibility mechanism that incorporates node-level masking and subgraph sampling to overcome the computational bottleneck imposed by large node counts. Extensive experiments show that VisiFold not only drastically reduces resource consumption but also outperforms existing baselines in long-term forecasting tasks. Remarkably, even with a high mask ratio of 80\%, VisiFold maintains its performance advantage. By effectively breaking the resource constraints in both temporal and spatial dimensions, our work paves the way for more realistic long-term traffic forecasting. The code is available at~ https://github.com/PlanckChang/VisiFold.
EMAformer: Enhancing Transformer through Embedding Armor for Time Series Forecasting
Nov 11, 2025Multivariate time series forecasting is crucial across a wide range of domains. While presenting notable progress for the Transformer architecture, iTransformer still lags behind the latest MLP-based models. We attribute this performance gap to unstable inter-channel relationships. To bridge this gap, we propose EMAformer, a simple yet effective model that enhances the Transformer with an auxiliary embedding suite, akin to armor that reinforces its ability. By introducing three key inductive biases, i.e., \textit{global stability}, \textit{phase sensitivity}, and \textit{cross-axis specificity}, EMAformer unlocks the further potential of the Transformer architecture, achieving state-of-the-art performance on 12 real-world benchmarks and reducing forecasting errors by an average of 2.73\% in MSE and 5.15\% in MAE. This significantly advances the practical applicability of Transformer-based approaches for multivariate time series forecasting. The code is available on https://github.com/PlanckChang/EMAformer.
CoT-RAG: Integrating Chain of Thought and Retrieval-Augmented Generation to Enhance Reasoning in Large Language Models
Apr 18, 2025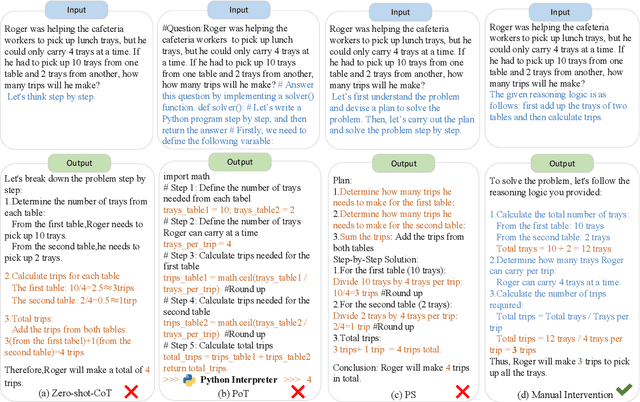

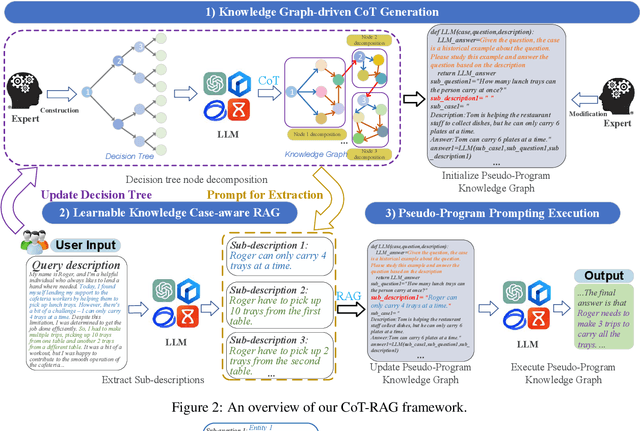

While chain-of-thought (CoT) reasoning improves the performance of large language models (LLMs) in complex tasks, it still has two main challenges: the low reliability of relying solely on LLMs to generate reasoning chains and the interference of natural language reasoning chains on the inference logic of LLMs. To address these issues, we propose CoT-RAG, a novel reasoning framework with three key designs: (i) Knowledge Graph-driven CoT Generation, featuring knowledge graphs to modulate reasoning chain generation of LLMs, thereby enhancing reasoning credibility; (ii) Learnable Knowledge Case-aware RAG, which incorporates retrieval-augmented generation (RAG) into knowledge graphs to retrieve relevant sub-cases and sub-descriptions, providing LLMs with learnable information; (iii) Pseudo-Program Prompting Execution, which encourages LLMs to execute reasoning tasks in pseudo-programs with greater logical rigor. We conduct a comprehensive evaluation on nine public datasets, covering three reasoning problems. Compared with the-state-of-the-art methods, CoT-RAG exhibits a significant accuracy improvement, ranging from 4.0% to 23.0%. Furthermore, testing on four domain-specific datasets, CoT-RAG shows remarkable accuracy and efficient execution, highlighting its strong practical applicability and scalability.
Deep Learning-Enabled ISAC-OTFS Pre-equalization Design for Aerial-Terrestrial Networks
Dec 06, 2024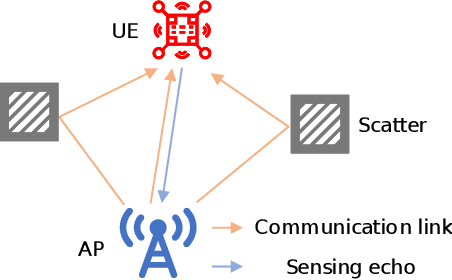
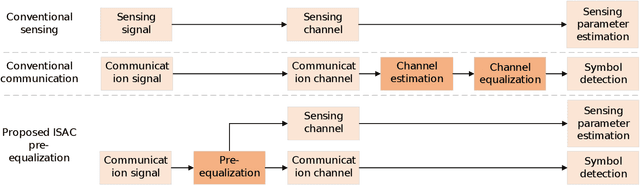
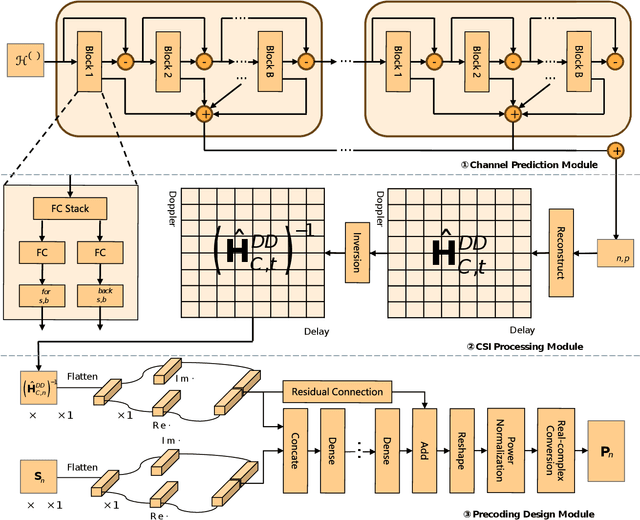
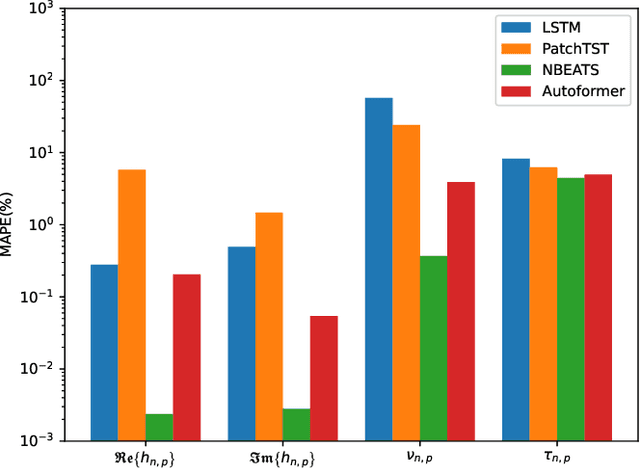
Orthogonal time frequency space (OTFS) modulation has been viewed as a promising technique for integrated sensing and communication (ISAC) systems and aerial-terrestrial networks, due to its delay-Doppler domain transmission property and strong Doppler-resistance capability. However, it also suffers from high processing complexity at the receiver. In this work, we propose a novel pre-equalization based ISAC-OTFS transmission framework, where the terrestrial base station (BS) executes pre-equalization based on its estimated channel state information (CSI). In particular, the mean square error of OTFS symbol demodulation and Cramer-Rao lower bound of sensing parameter estimation are derived, and their weighted sum is utilized as the metric for optimizing the pre-equalization matrix. To address the formulated problem while taking the time-varying CSI into consideration, a deep learning enabled channel prediction-based pre-equalization framework is proposed, where a parameter-level channel prediction module is utilized to decouple OTFS channel parameters, and a low-dimensional prediction network is leveraged to correct outdated CSI. A CSI processing module is then used to initialize the input of the pre-equalization module. Finally, a residual-structured deep neural network is cascaded to execute pre-equalization. Simulation results show that under the proposed framework, the demodulation complexity at the receiver as well as the pilot overhead for channel estimation, are significantly reduced, while the symbol detection performance approaches those of conventional minimum mean square error equalization and perfect CSI.
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Aug 22, 2024



We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model. Code and models are released at https://github.com/showlab/Show-o.
CFinBench: A Comprehensive Chinese Financial Benchmark for Large Language Models
Jul 02, 2024



Large language models (LLMs) have achieved remarkable performance on various NLP tasks, yet their potential in more challenging and domain-specific task, such as finance, has not been fully explored. In this paper, we present CFinBench: a meticulously crafted, the most comprehensive evaluation benchmark to date, for assessing the financial knowledge of LLMs under Chinese context. In practice, to better align with the career trajectory of Chinese financial practitioners, we build a systematic evaluation from 4 first-level categories: (1) Financial Subject: whether LLMs can memorize the necessary basic knowledge of financial subjects, such as economics, statistics and auditing. (2) Financial Qualification: whether LLMs can obtain the needed financial qualified certifications, such as certified public accountant, securities qualification and banking qualification. (3) Financial Practice: whether LLMs can fulfill the practical financial jobs, such as tax consultant, junior accountant and securities analyst. (4) Financial Law: whether LLMs can meet the requirement of financial laws and regulations, such as tax law, insurance law and economic law. CFinBench comprises 99,100 questions spanning 43 second-level categories with 3 question types: single-choice, multiple-choice and judgment. We conduct extensive experiments of 50 representative LLMs with various model size on CFinBench. The results show that GPT4 and some Chinese-oriented models lead the benchmark, with the highest average accuracy being 60.16%, highlighting the challenge presented by CFinBench. The dataset and evaluation code are available at https://cfinbench.github.io/.
Touch100k: A Large-Scale Touch-Language-Vision Dataset for Touch-Centric Multimodal Representation
Jun 06, 2024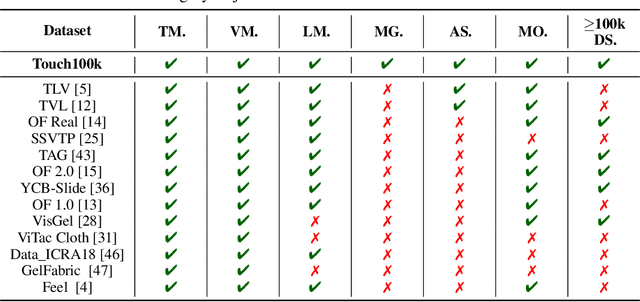
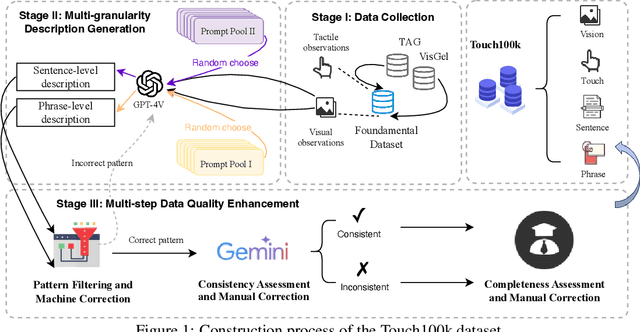
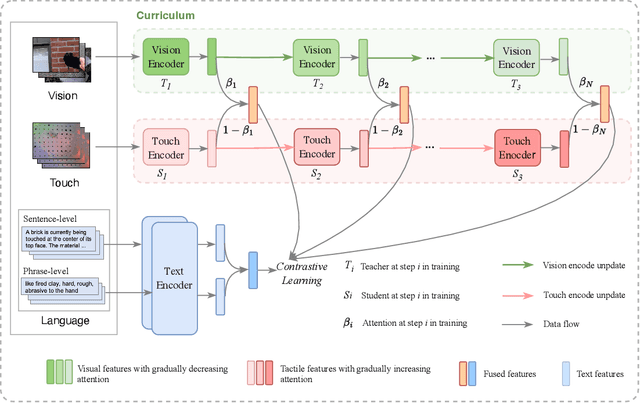
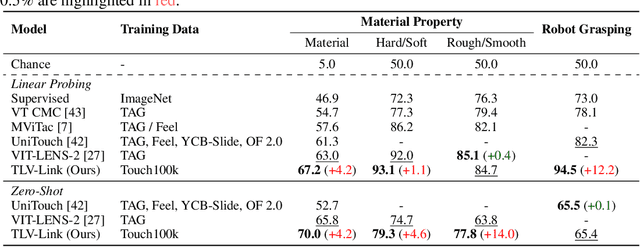
Touch holds a pivotal position in enhancing the perceptual and interactive capabilities of both humans and robots. Despite its significance, current tactile research mainly focuses on visual and tactile modalities, overlooking the language domain. Inspired by this, we construct Touch100k, a paired touch-language-vision dataset at the scale of 100k, featuring tactile sensation descriptions in multiple granularities (i.e., sentence-level natural expressions with rich semantics, including contextual and dynamic relationships, and phrase-level descriptions capturing the key features of tactile sensations). Based on the dataset, we propose a pre-training method, Touch-Language-Vision Representation Learning through Curriculum Linking (TLV-Link, for short), inspired by the concept of curriculum learning. TLV-Link aims to learn a tactile representation for the GelSight sensor and capture the relationship between tactile, language, and visual modalities. We evaluate our representation's performance across two task categories (namely, material property identification and robot grasping prediction), focusing on tactile representation and zero-shot touch understanding. The experimental evaluation showcases the effectiveness of our representation. By enabling TLV-Link to achieve substantial improvements and establish a new state-of-the-art in touch-centric multimodal representation learning, Touch100k demonstrates its value as a valuable resource for research. Project page: https://cocacola-lab.github.io/Touch100k/.
Outage Performance of Multi-tier UAV Communication with Random Beam Misalignment
Jul 24, 2023



By exploiting the degree of freedom on the altitude, unmanned aerial vehicle (UAV) communication can provide ubiquitous communication for future wireless networks. In the case of concurrent transmission of multiple UAVs, the directional beamforming formed by multiple antennas is an effective way to reduce co-channel interference. However, factors such as airflow disturbance or estimation error for UAV communications can cause the occurrence of beam misalignment. In this paper, we investigate the system performance of a multi-tier UAV communication network with the consideration of unstable beam alignment. In particular, we propose a tractable random model to capture the impacts of beam misalignment in the 3D space. Based on this, by utilizing stochastic geometry, an analytical framework for obtaining the outage probability in the downlink of a multi-tier UAV communication network for the closest distance association scheme and the maximum average power association scheme is established. The accuracy of the analysis is verified by Monte-Carlo simulations. The results indicate that in the presence of random beam misalignment, the optimal number of UAV antennas needs to be adjusted to be relatively larger when the density of UAVs increases or the altitude of UAVs becomes higher.
3D Part Assembly Generation with Instance Encoded Transformer
Jul 05, 2022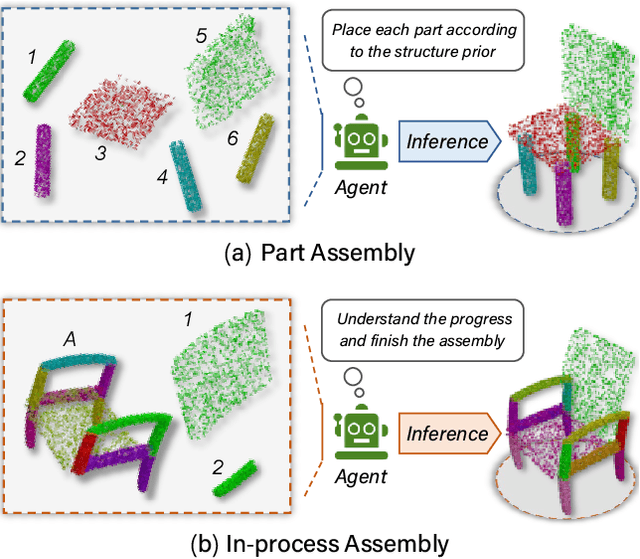
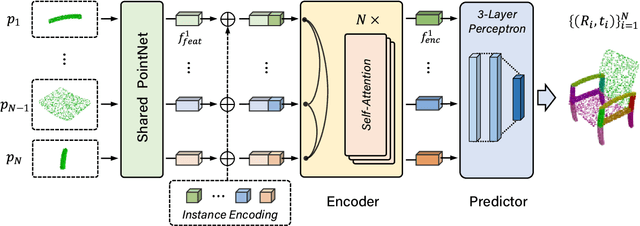
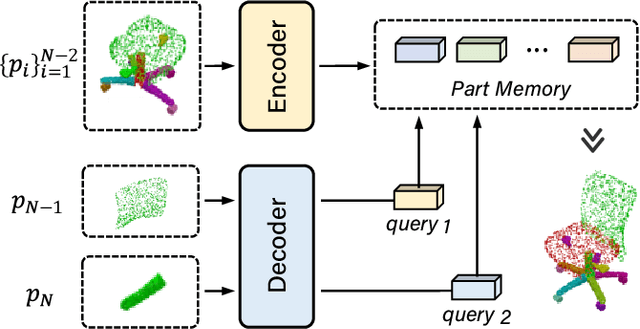
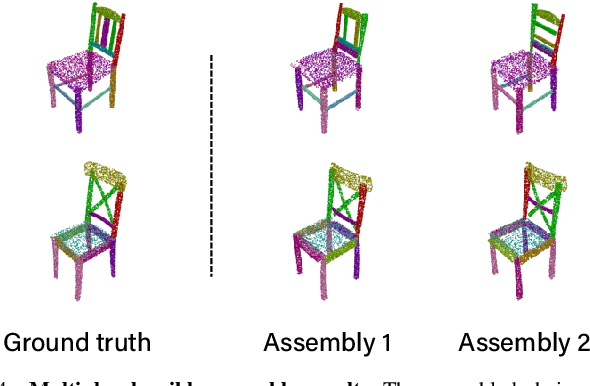
It is desirable to enable robots capable of automatic assembly. Structural understanding of object parts plays a crucial role in this task yet remains relatively unexplored. In this paper, we focus on the setting of furniture assembly from a complete set of part geometries, which is essentially a 6-DoF part pose estimation problem. We propose a multi-layer transformer-based framework that involves geometric and relational reasoning between parts to update the part poses iteratively. We carefully design a unique instance encoding to solve the ambiguity between geometrically-similar parts so that all parts can be distinguished. In addition to assembling from scratch, we extend our framework to a new task called in-process part assembly. Analogous to furniture maintenance, it requires robots to continue with unfinished products and assemble the remaining parts into appropriate positions. Our method achieves far more than 10% improvements over the current state-of-the-art in multiple metrics on the public PartNet dataset. Extensive experiments and quantitative comparisons demonstrate the effectiveness of the proposed framework.
* 8 pages, 7 figures