 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketched Gaussian Mechanism for Private Federated Learning
Sep 09, 2025Communication cost and privacy are two major considerations in federated learning (FL). For communication cost, gradient compression by sketching the clients' transmitted model updates is often used for reducing per-round communication. For privacy, the Gaussian mechanism (GM), which consists of clipping updates and adding Gaussian noise, is commonly used to guarantee client-level differential privacy. Existing literature on private FL analyzes privacy of sketching and GM in an isolated manner, illustrating that sketching provides privacy determined by the sketching dimension and that GM has to supply any additional desired privacy. In this paper, we introduce the Sketched Gaussian Mechanism (SGM), which directly combines sketching and the Gaussian mechanism for privacy. Using R\'enyi-DP tools, we present a joint analysis of SGM's overall privacy guarantee, which is significantly more flexible and sharper compared to isolated analysis of sketching and GM privacy. In particular, we prove that the privacy level of SGM for a fixed noise magnitude is proportional to $1/\sqrt{b}$, where $b$ is the sketching dimension, indicating that (for moderate $b$) SGM can provide much stronger privacy guarantees than the original GM under the same noise budget. We demonstrate the application of SGM to FL with either gradient descent or adaptive server optimizers, and establish theoretical results on optimization convergence, which exhibits only a logarithmic dependence on the number of parameters $d$. Experimental results confirm that at the same privacy level, SGM based FL is at least competitive with non-sketching private FL variants and outperforms them in some settings. Moreover, using adaptive optimization at the server improves empirical performance while maintaining the privacy guarantees.
Optimal Control Operator Perspective and a Neural Adaptive Spectral Method
Dec 17, 2024



Optimal control problems (OCPs) involve finding a control function for a dynamical system such that a cost functional is optimized. It is central to physical systems in both academia and industry. In this paper, we propose a novel instance-solution control operator perspective, which solves OCPs in a one-shot manner without direct dependence on the explicit expression of dynamics or iterative optimization processes. The control operator is implemented by a new neural operator architecture named Neural Adaptive Spectral Method (NASM), a generalization of classical spectral methods. We theoretically validate the perspective and architecture by presenting the approximation error bounds of NASM for the control operator. Experiments on synthetic environments and a real-world dataset verify the effectiveness and efficiency of our approach, including substantial speedup in running time, and high-quality in- and out-of-distribution generalization.
Sketched Adaptive Federated Deep Learning: A Sharp Convergence Analysis
Nov 12, 2024
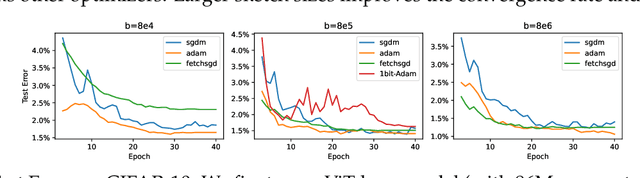
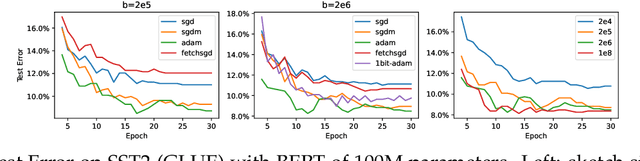
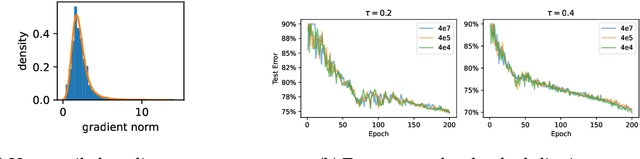
Combining gradient compression methods (e.g., CountSketch, quantization) and adaptive optimizers (e.g., Adam, AMSGrad) is a desirable goal in federated learning (FL), with potential benefits on both fewer communication rounds and less per-round communication. In spite of the preliminary empirical success of sketched adaptive methods, existing convergence analyses show the communication cost to have a linear dependence on the ambient dimension, i.e., number of parameters, which is prohibitively high for modern deep learning models. In this work, we introduce specific sketched adaptive federated learning (SAFL) algorithms and, as our main contribution, provide theoretical convergence analyses in different FL settings with guarantees on communication cost depending only logarithmically (instead of linearly) on the ambient dimension. Unlike existing analyses, we show that the entry-wise sketching noise existent in the preconditioners and the first moments of SAFL can be implicitly addressed by leveraging the recently-popularized anisotropic curvatures in deep learning losses, e.g., fast decaying loss Hessian eigen-values. In the i.i.d. client setting of FL, we show that SAFL achieves asymptotic $O(1/\sqrt{T})$ convergence, and converges faster in the initial epochs. In the non-i.i.d. client setting, where non-adaptive methods lack convergence guarantees, we show that SACFL (SAFL with clipping) algorithms can provably converge in spite of the additional heavy-tailed noise. Our theoretical claims are supported by empirical studies on vision and language tasks, and in both fine-tuning and training-from-scratch regimes. Surprisingly, as a by-product of our analysis, the proposed SAFL methods are competitive with the state-of-the-art communication-efficient federated learning algorithms based on error feedback.
LArctan-SKAN: Simple and Efficient Single-Parameterized Kolmogorov-Arnold Networks using Learnable Trigonometric Function
Oct 25, 2024



This paper proposes a novel approach for designing Single-Parameterized Kolmogorov-Arnold Networks (SKAN) by utilizing a Single-Parameterized Function (SFunc) constructed from trigonometric functions. Three new SKAN variants are developed: LSin-SKAN, LCos-SKAN, and LArctan-SKAN. Experimental validation on the MNIST dataset demonstrates that LArctan-SKAN excels in both accuracy and computational efficiency. Specifically, LArctan-SKAN significantly improves test set accuracy over existing models, outperforming all pure KAN variants compared, including FourierKAN, LSS-SKAN, and Spl-KAN. It also surpasses mixed MLP-based models such as MLP+rKAN and MLP+fKAN in accuracy. Furthermore, LArctan-SKAN exhibits remarkable computational efficiency, with a training speed increase of 535.01% and 49.55% compared to MLP+rKAN and MLP+fKAN, respectively. These results confirm the effectiveness and potential of SKANs constructed with trigonometric functions. The experiment code is available at https://github.com/chikkkit/LArctan-SKAN .
LSS-SKAN: Efficient Kolmogorov-Arnold Networks based on Single-Parameterized Function
Oct 19, 2024



The recently proposed Kolmogorov-Arnold Networks (KAN) networks have attracted increasing attention due to their advantage of high visualizability compared to MLP. In this paper, based on a series of small-scale experiments, we proposed the Efficient KAN Expansion Principle (EKE Principle): allocating parameters to expand network scale, rather than employing more complex basis functions, leads to more efficient performance improvements in KANs. Based on this principle, we proposed a superior KAN termed SKAN, where the basis function utilizes only a single learnable parameter. We then evaluated various single-parameterized functions for constructing SKANs, with LShifted Softplus-based SKANs (LSS-SKANs) demonstrating superior accuracy. Subsequently, extensive experiments were performed, comparing LSS-SKAN with other KAN variants on the MNIST dataset. In the final accuracy tests, LSS-SKAN exhibited superior performance on the MNIST dataset compared to all tested pure KAN variants. Regarding execution speed, LSS-SKAN outperformed all compared popular KAN variants. Our experimental codes are available at https://github.com/chikkkit/LSS-SKAN and SKAN's Python library (for quick construction of SKAN in python) codes are available at https://github.com/chikkkit/SKAN .
Optimization and Generalization Guarantees for Weight Normalization
Sep 13, 2024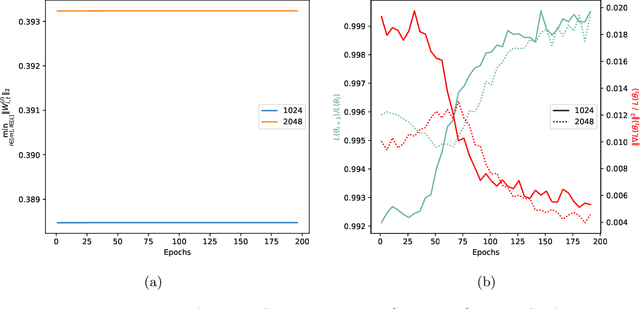
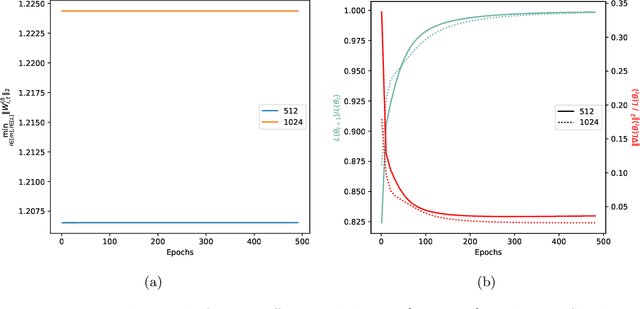
Weight normalization (WeightNorm) is widely used in practice for the training of deep neural networks and modern deep learning libraries have built-in implementations of it. In this paper, we provide the first theoretical characterizations of both optimization and generalization of deep WeightNorm models with smooth activation functions. For optimization, from the form of the Hessian of the loss, we note that a small Hessian of the predictor leads to a tractable analysis. Thus, we bound the spectral norm of the Hessian of WeightNorm networks and show its dependence on the network width and weight normalization terms--the latter being unique to networks without WeightNorm. Then, we use this bound to establish training convergence guarantees under suitable assumptions for gradient decent. For generalization, we use WeightNorm to get a uniform convergence based generalization bound, which is independent from the width and depends sublinearly on the depth. Finally, we present experimental results which illustrate how the normalization terms and other quantities of theoretical interest relate to the training of WeightNorm networks.
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Aug 22, 2024



We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model. Code and models are released at https://github.com/showlab/Show-o.
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Jul 02, 2024



Text-to-video (T2V) generation has recently garnered significant attention thanks to the large multi-modality model Sora. However, T2V generation still faces two important challenges: 1) Lacking a precise open sourced high-quality dataset. The previous popular video datasets, e.g. WebVid-10M and Panda-70M, are either with low quality or too large for most research institutions. Therefore, it is challenging but crucial to collect a precise high-quality text-video pairs for T2V generation. 2) Ignoring to fully utilize textual information. Recent T2V methods have focused on vision transformers, using a simple cross attention module for video generation, which falls short of thoroughly extracting semantic information from text prompt. To address these issues, we introduce OpenVid-1M, a precise high-quality dataset with expressive captions. This open-scenario dataset contains over 1 million text-video pairs, facilitating research on T2V generation. Furthermore, we curate 433K 1080p videos from OpenVid-1M to create OpenVidHD-0.4M, advancing high-definition video generation. Additionally, we propose a novel Multi-modal Video Diffusion Transformer (MVDiT) capable of mining both structure information from visual tokens and semantic information from text tokens. Extensive experiments and ablation studies verify the superiority of OpenVid-1M over previous datasets and the effectiveness of our MVDiT.
Learning Neural Hamiltonian Dynamics: A Methodological Overview
Feb 28, 2022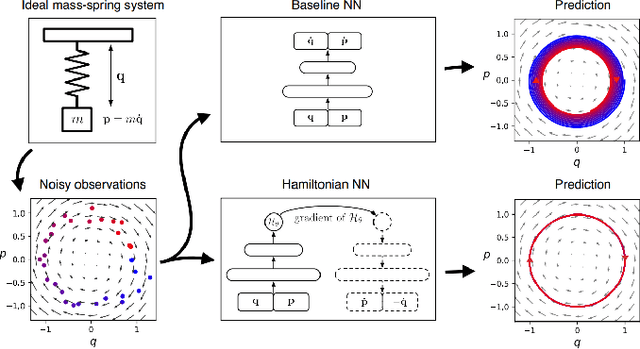

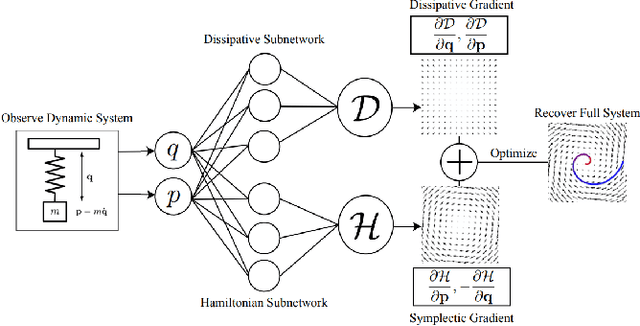
The past few years have witnessed an increased interest in learning Hamiltonian dynamics in deep learning frameworks. As an inductive bias based on physical laws, Hamiltonian dynamics endow neural networks with accurate long-term prediction, interpretability, and data-efficient learning. However, Hamiltonian dynamics also bring energy conservation or dissipation assumptions on the input data and additional computational overhead. In this paper, we systematically survey recently proposed Hamiltonian neural network models, with a special emphasis on methodologies. In general, we discuss the major contributions of these models, and compare them in four overlapping directions: 1) generalized Hamiltonian system; 2) symplectic integration, 3) generalized input form, and 4) extended problem settings. We also provide an outlook of the fundamental challenges and emerging opportunities in this area.
Optimizing AD Pruning of Sponsored Search with Reinforcement Learning
Aug 05, 2020

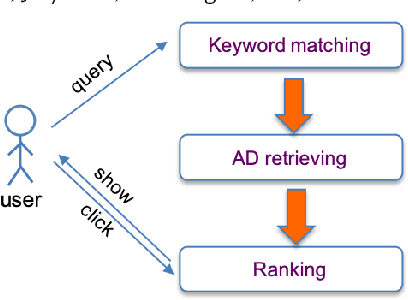
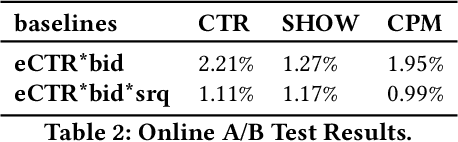
Industrial sponsored search system (SSS) can be logically divided into three modules: keywords matching, ad retrieving, and ranking. During ad retrieving, the ad candidates grow exponentially. A query with high commercial value might retrieve a great deal of ad candidates such that the ranking module could not afford. Due to limited latency and computing resources, the candidates have to be pruned earlier. Suppose we set a pruning line to cut SSS into two parts: upstream and downstream. The problem we are going to address is: how to pick out the best $K$ items from $N$ candidates provided by the upstream to maximize the total system's revenue. Since the industrial downstream is very complicated and updated quickly, a crucial restriction in this problem is that the selection scheme should get adapted to the downstream. In this paper, we propose a novel model-free reinforcement learning approach to fixing this problem. Our approach considers downstream as a black-box environment, and the agent sequentially selects items and finally feeds into the downstream, where revenue would be estimated and used as a reward to improve the selection policy. To the best of our knowledge, this is first time to consider the system optimization from a downstream adaption view. It is also the first time to use reinforcement learning techniques to tackle this problem. The idea has been successfully realized in Baidu's sponsored search system, and online long time A/B test shows remarkable improvements on revenue.