 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketched Adaptive Federated Deep Learning: A Sharp Convergence Analysis
Paper and Code
Nov 12, 2024
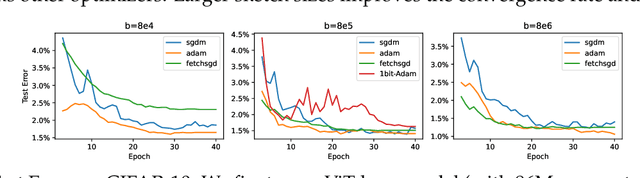
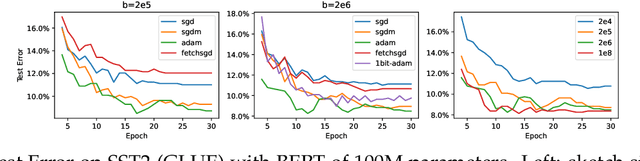
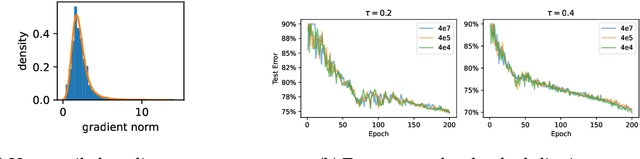
Combining gradient compression methods (e.g., CountSketch, quantization) and adaptive optimizers (e.g., Adam, AMSGrad) is a desirable goal in federated learning (FL), with potential benefits on both fewer communication rounds and less per-round communication. In spite of the preliminary empirical success of sketched adaptive methods, existing convergence analyses show the communication cost to have a linear dependence on the ambient dimension, i.e., number of parameters, which is prohibitively high for modern deep learning models. In this work, we introduce specific sketched adaptive federated learning (SAFL) algorithms and, as our main contribution, provide theoretical convergence analyses in different FL settings with guarantees on communication cost depending only logarithmically (instead of linearly) on the ambient dimension. Unlike existing analyses, we show that the entry-wise sketching noise existent in the preconditioners and the first moments of SAFL can be implicitly addressed by leveraging the recently-popularized anisotropic curvatures in deep learning losses, e.g., fast decaying loss Hessian eigen-values. In the i.i.d. client setting of FL, we show that SAFL achieves asymptotic $O(1/\sqrt{T})$ convergence, and converges faster in the initial epochs. In the non-i.i.d. client setting, where non-adaptive methods lack convergence guarantees, we show that SACFL (SAFL with clipping) algorithms can provably converge in spite of the additional heavy-tailed noise. Our theoretical claims are supported by empirical studies on vision and language tasks, and in both fine-tuning and training-from-scratch regimes. Surprisingly, as a by-product of our analysis, the proposed SAFL methods are competitive with the state-of-the-art communication-efficient federated learning algorithms based on error feedback.