 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketched Gaussian Mechanism for Private Federated Learning
Sep 09, 2025Communication cost and privacy are two major considerations in federated learning (FL). For communication cost, gradient compression by sketching the clients' transmitted model updates is often used for reducing per-round communication. For privacy, the Gaussian mechanism (GM), which consists of clipping updates and adding Gaussian noise, is commonly used to guarantee client-level differential privacy. Existing literature on private FL analyzes privacy of sketching and GM in an isolated manner, illustrating that sketching provides privacy determined by the sketching dimension and that GM has to supply any additional desired privacy. In this paper, we introduce the Sketched Gaussian Mechanism (SGM), which directly combines sketching and the Gaussian mechanism for privacy. Using R\'enyi-DP tools, we present a joint analysis of SGM's overall privacy guarantee, which is significantly more flexible and sharper compared to isolated analysis of sketching and GM privacy. In particular, we prove that the privacy level of SGM for a fixed noise magnitude is proportional to $1/\sqrt{b}$, where $b$ is the sketching dimension, indicating that (for moderate $b$) SGM can provide much stronger privacy guarantees than the original GM under the same noise budget. We demonstrate the application of SGM to FL with either gradient descent or adaptive server optimizers, and establish theoretical results on optimization convergence, which exhibits only a logarithmic dependence on the number of parameters $d$. Experimental results confirm that at the same privacy level, SGM based FL is at least competitive with non-sketching private FL variants and outperforms them in some settings. Moreover, using adaptive optimization at the server improves empirical performance while maintaining the privacy guarantees.
Sketched Adaptive Federated Deep Learning: A Sharp Convergence Analysis
Nov 12, 2024
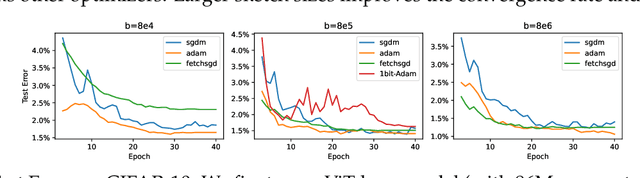
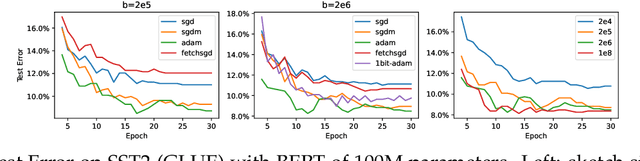
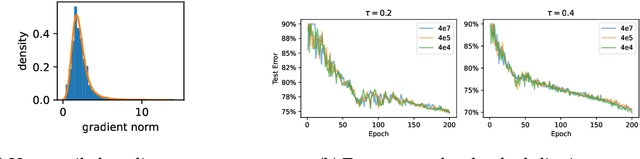
Combining gradient compression methods (e.g., CountSketch, quantization) and adaptive optimizers (e.g., Adam, AMSGrad) is a desirable goal in federated learning (FL), with potential benefits on both fewer communication rounds and less per-round communication. In spite of the preliminary empirical success of sketched adaptive methods, existing convergence analyses show the communication cost to have a linear dependence on the ambient dimension, i.e., number of parameters, which is prohibitively high for modern deep learning models. In this work, we introduce specific sketched adaptive federated learning (SAFL) algorithms and, as our main contribution, provide theoretical convergence analyses in different FL settings with guarantees on communication cost depending only logarithmically (instead of linearly) on the ambient dimension. Unlike existing analyses, we show that the entry-wise sketching noise existent in the preconditioners and the first moments of SAFL can be implicitly addressed by leveraging the recently-popularized anisotropic curvatures in deep learning losses, e.g., fast decaying loss Hessian eigen-values. In the i.i.d. client setting of FL, we show that SAFL achieves asymptotic $O(1/\sqrt{T})$ convergence, and converges faster in the initial epochs. In the non-i.i.d. client setting, where non-adaptive methods lack convergence guarantees, we show that SACFL (SAFL with clipping) algorithms can provably converge in spite of the additional heavy-tailed noise. Our theoretical claims are supported by empirical studies on vision and language tasks, and in both fine-tuning and training-from-scratch regimes. Surprisingly, as a by-product of our analysis, the proposed SAFL methods are competitive with the state-of-the-art communication-efficient federated learning algorithms based on error feedback.
Loss Gradient Gaussian Width based Generalization and Optimization Guarantees
Jun 11, 2024Generalization and optimization guarantees on the population loss in machine learning often rely on uniform convergence based analysis, typically based on the Rademacher complexity of the predictors. The rich representation power of modern models has led to concerns about this approach. In this paper, we present generalization and optimization guarantees in terms of the complexity of the gradients, as measured by the Loss Gradient Gaussian Width (LGGW). First, we introduce generalization guarantees directly in terms of the LGGW under a flexible gradient domination condition, which we demonstrate to hold empirically for deep models. Second, we show that sample reuse in finite sum (stochastic) optimization does not make the empirical gradient deviate from the population gradient as long as the LGGW is small. Third, focusing on deep networks, we present results showing how to bound their LGGW under mild assumptions. In particular, we show that their LGGW can be bounded (a) by the $L_2$-norm of the loss Hessian eigenvalues, which has been empirically shown to be $\tilde{O}(1)$ for commonly used deep models; and (b) in terms of the Gaussian width of the featurizer, i.e., the output of the last-but-one layer. To our knowledge, our generalization and optimization guarantees in terms of LGGW are the first results of its kind, avoid the pitfalls of predictor Rademacher complexity based analysis, and hold considerable promise towards quantitatively tight bounds for deep models.
Differentially Private Post-Processing for Fair Regression
May 07, 2024



This paper describes a differentially private post-processing algorithm for learning fair regressors satisfying statistical parity, addressing privacy concerns of machine learning models trained on sensitive data, as well as fairness concerns of their potential to propagate historical biases. Our algorithm can be applied to post-process any given regressor to improve fairness by remapping its outputs. It consists of three steps: first, the output distributions are estimated privately via histogram density estimation and the Laplace mechanism, then their Wasserstein barycenter is computed, and the optimal transports to the barycenter are used for post-processing to satisfy fairness. We analyze the sample complexity of our algorithm and provide fairness guarantee, revealing a trade-off between the statistical bias and variance induced from the choice of the number of bins in the histogram, in which using less bins always favors fairness at the expense of error.