 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacticGen: Grounding Adaptable and Scalable Generation of Football Tactics
Apr 20, 2026Success in association football relies on both individual skill and coordinated tactics. While recent advancements in spatio-temporal data and deep learning have enabled predictive analyses like trajectory forecasting, the development of tactical design remains limited. Bridging this gap is essential, as prediction reveals what is likely to occur, whereas tactic generation determines what should occur to achieve strategic objectives. In this work, we present TacticGen, a generative model for adaptable and scalable tactic generation. TacticGen formulates tactics as sequences of multi-agent movements and interactions conditioned on the game context. It employs a multi-agent diffusion transformer with agent-wise self-attention and context-aware cross-attention to capture cooperative and competitive dynamics among players and the ball. Trained with over 3.3 million events and 100 million tracking frames from top-tier leagues, TacticGen achieves state-of-the-art precision in predicting player trajectories. Building on it, TacticGen enables adaptable tactic generation tailored to diverse inference-time objectives through classifier guidance mechanism, specified via rules, natural language, or neural models. Its modeling performance is also inherently scalable. A case study with football experts confirms that TacticGen generates realistic, strategically valuable tactics, demonstrating its practical utility for tactical planning in professional football. The project page is available at: https://shengxu.net/TacticGen/.
MSSR: Memory-Aware Adaptive Replay for Continual LLM Fine-Tuning
Mar 10, 2026Continual fine-tuning of large language models (LLMs) is becoming increasingly crucial as these models are deployed in dynamic environments where tasks and data distributions evolve over time. While strong adaptability enables rapid acquisition of new knowledge, it also exposes LLMs to catastrophic forgetting, where previously learned skills degrade during sequential training. Existing replay-based strategies, such as fixed interleaved replay, accuracy-supervised, and loss-driven scheduling, remain limited: some depend on heuristic rules and provide only partial mitigation of forgetting, while others improve performance but incur substantial computational overhead. Motivated by retention dynamics under sequential fine-tuning, we propose Memory-Inspired Sampler and Scheduler Replay (MSSR), an experience replay framework that estimates sample-level memory strength and schedules rehearsal at adaptive intervals to mitigate catastrophic forgetting while maintaining fast adaptation. Extensive experiments across three backbone models and 11 sequential tasks show that MSSR consistently outperforms state-of-the-art replay baselines, with particularly strong gains on reasoning-intensive and multiple-choice benchmarks.
Calibrating Tabular Anomaly Detection via Optimal Transport
Feb 06, 2026Tabular anomaly detection (TAD) remains challenging due to the heterogeneity of tabular data: features lack natural relationships, vary widely in distribution and scale, and exhibit diverse types. Consequently, each TAD method makes implicit assumptions about anomaly patterns that work well on some datasets but fail on others, and no method consistently outperforms across diverse scenarios. We present CTAD (Calibrating Tabular Anomaly Detection), a model-agnostic post-processing framework that enhances any existing TAD detector through sample-specific calibration. Our approach characterizes normal data via two complementary distributions, i.e., an empirical distribution from random sampling and a structural distribution from K-means centroids, and measures how adding a test sample disrupts their compatibility using Optimal Transport (OT) distance. Normal samples maintain low disruption while anomalies cause high disruption, providing a calibration signal to amplify detection. We prove that OT distance has a lower bound proportional to the test sample's distance from centroids, and establish that anomalies systematically receive higher calibration scores than normals in expectation, explaining why the method generalizes across datasets. Extensive experiments on 34 diverse tabular datasets with 7 representative detectors spanning all major TAD categories (density estimation, classification, reconstruction, and isolation-based methods) demonstrate that CTAD consistently improves performance with statistical significance. Remarkably, CTAD enhances even state-of-the-art deep learning methods and shows robust performance across diverse hyperparameter settings, requiring no additional tuning for practical deployment.
Training-Free Self-Correction for Multimodal Masked Diffusion Models
Feb 02, 2026Masked diffusion models have emerged as a powerful framework for text and multimodal generation. However, their sampling procedure updates multiple tokens simultaneously and treats generated tokens as immutable, which may lead to error accumulation when early mistakes cannot be revised. In this work, we revisit existing self-correction methods and identify limitations stemming from additional training requirements or reliance on misaligned likelihood estimates. We propose a training-free self-correction framework that exploits the inductive biases of pre-trained masked diffusion models. Without modifying model parameters or introducing auxiliary evaluators, our method significantly improves generation quality on text-to-image generation and multimodal understanding tasks with reduced sampling steps. Moreover, the proposed framework generalizes across different masked diffusion architectures, highlighting its robustness and practical applicability. Code can be found in https://github.com/huge123/FreeCorrection.
Alignment of Diffusion Model and Flow Matching for Text-to-Image Generation
Jan 31, 2026Diffusion models and flow matching have demonstrated remarkable success in text-to-image generation. While many existing alignment methods primarily focus on fine-tuning pre-trained generative models to maximize a given reward function, these approaches require extensive computational resources and may not generalize well across different objectives. In this work, we propose a novel alignment framework by leveraging the underlying nature of the alignment problem -- sampling from reward-weighted distributions -- and show that it applies to both diffusion models (via score guidance) and flow matching models (via velocity guidance). The score function (velocity field) required for the reward-weighted distribution can be decomposed into the pre-trained score (velocity field) plus a conditional expectation of the reward. For the alignment on the diffusion model, we identify a fundamental challenge: the adversarial nature of the guidance term can introduce undesirable artifacts in the generated images. Therefore, we propose a finetuning-free framework that trains a guidance network to estimate the conditional expectation of the reward. We achieve comparable performance to finetuning-based models with one-step generation with at least a 60% reduction in computational cost. For the alignment on flow matching, we propose a training-free framework that improves the generation quality without additional computational cost.
Corrected Samplers for Discrete Flow Models
Jan 30, 2026Discrete flow models (DFMs) have been proposed to learn the data distribution on a finite state space, offering a flexible framework as an alternative to discrete diffusion models. A line of recent work has studied samplers for discrete diffusion models, such as tau-leaping and Euler solver. However, these samplers require a large number of iterations to control discretization error, since the transition rates are frozen in time and evaluated at the initial state within each time interval. Moreover, theoretical results for these samplers often require boundedness conditions of the transition rate or they focus on a specific type of source distributions. To address those limitations, we establish non-asymptotic discretization error bounds for those samplers without any restriction on transition rates and source distributions, under the framework of discrete flow models. Furthermore, by analyzing a one-step lower bound of the Euler sampler, we propose two corrected samplers: \textit{time-corrected sampler} and \textit{location-corrected sampler}, which can reduce the discretization error of tau-leaping and Euler solver with almost no additional computational cost. We rigorously show that the location-corrected sampler has a lower iteration complexity than existing parallel samplers. We validate the effectiveness of the proposed method by demonstrating improved generation quality and reduced inference time on both simulation and text-to-image generation tasks. Code can be found in https://github.com/WanZhengyan/Corrected-Samplers-for-Discrete-Flow-Models.
Safeguarding LLM Fine-tuning via Push-Pull Distributional Alignment
Jan 12, 2026The inherent safety alignment of Large Language Models (LLMs) is prone to erosion during fine-tuning, even when using seemingly innocuous datasets. While existing defenses attempt to mitigate this via data selection, they typically rely on heuristic, instance-level assessments that neglect the global geometry of the data distribution and fail to explicitly repel harmful patterns. To address this, we introduce Safety Optimal Transport (SOT), a novel framework that reframes safe fine-tuning from an instance-level filtering challenge to a distribution-level alignment task grounded in Optimal Transport (OT). At its core is a dual-reference ``push-pull'' weight-learning mechanism: SOT optimizes sample importance by actively pulling the downstream distribution towards a trusted safe anchor while simultaneously pushing it away from a general harmful reference. This establishes a robust geometric safety boundary that effectively purifies the training data. Extensive experiments across diverse model families and domains demonstrate that SOT significantly enhances model safety while maintaining competitive downstream performance, achieving a superior safety-utility trade-off compared to baselines.
Milestones over Outcome: Unlocking Geometric Reasoning with Sub-Goal Verifiable Reward
Jan 08, 2026Multimodal Large Language Models (MLLMs) struggle with complex geometric reasoning, largely because "black box" outcome-based supervision fails to distinguish between lucky guesses and rigorous deduction. To address this, we introduce a paradigm shift towards subgoal-level evaluation and learning. We first construct GeoGoal, a benchmark synthesized via a rigorous formal verification data engine, which converts abstract proofs into verifiable numeric subgoals. This structure reveals a critical divergence between reasoning quality and outcome accuracy. Leveraging this, we propose the Sub-Goal Verifiable Reward (SGVR) framework, which replaces sparse signals with dense rewards based on the Skeleton Rate. Experiments demonstrate that SGVR not only enhances geometric performance (+9.7%) but also exhibits strong generalization, transferring gains to general math (+8.0%) and other general reasoning tasks (+2.8%), demonstrating broad applicability across diverse domains.
Policy-Conditioned Policies for Multi-Agent Task Solving
Dec 24, 2025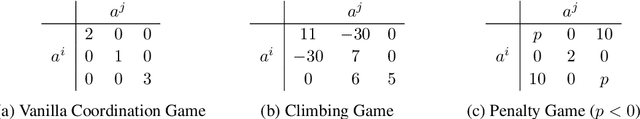

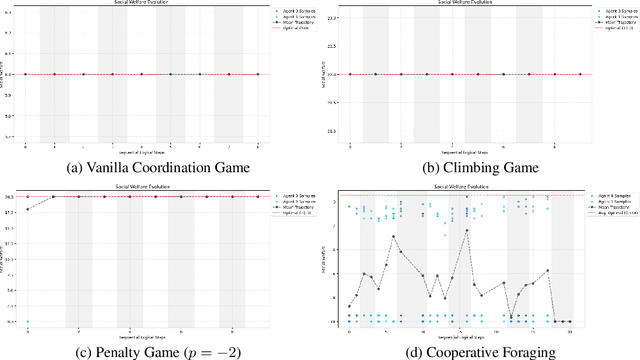
In multi-agent tasks, the central challenge lies in the dynamic adaptation of strategies. However, directly conditioning on opponents' strategies is intractable in the prevalent deep reinforcement learning paradigm due to a fundamental ``representational bottleneck'': neural policies are opaque, high-dimensional parameter vectors that are incomprehensible to other agents. In this work, we propose a paradigm shift that bridges this gap by representing policies as human-interpretable source code and utilizing Large Language Models (LLMs) as approximate interpreters. This programmatic representation allows us to operationalize the game-theoretic concept of \textit{Program Equilibrium}. We reformulate the learning problem by utilizing LLMs to perform optimization directly in the space of programmatic policies. The LLM functions as a point-wise best-response operator that iteratively synthesizes and refines the ego agent's policy code to respond to the opponent's strategy. We formalize this process as \textit{Programmatic Iterated Best Response (PIBR)}, an algorithm where the policy code is optimized by textual gradients, using structured feedback derived from game utility and runtime unit tests. We demonstrate that this approach effectively solves several standard coordination matrix games and a cooperative Level-Based Foraging environment.
Error Analysis of Discrete Flow with Generator Matching
Sep 26, 2025Discrete flow models offer a powerful framework for learning distributions over discrete state spaces and have demonstrated superior performance compared to the discrete diffusion model. However, their convergence properties and error analysis remain largely unexplored. In this work, we develop a unified framework grounded in stochastic calculus theory to systematically investigate the theoretical properties of discrete flow. Specifically, we derive the KL divergence of two path measures regarding two continuous-time Markov chains (CTMCs) with different transition rates by developing a novel Girsanov-type theorem, and provide a comprehensive analysis that encompasses the error arising from transition rate estimation and early stopping, where the first type of error has rarely been analyzed by existing works. Unlike discrete diffusion models, discrete flow incurs no truncation error caused by truncating the time horizon in the noising process. Building on generator matching and uniformization, we establish non-asymptotic error bounds for distribution estimation. Our results provide the first error analysis for discrete flow models.