 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Graph Matching Improves Retrieval Augmented Generation in Molecular Machine Learning
Feb 25, 2025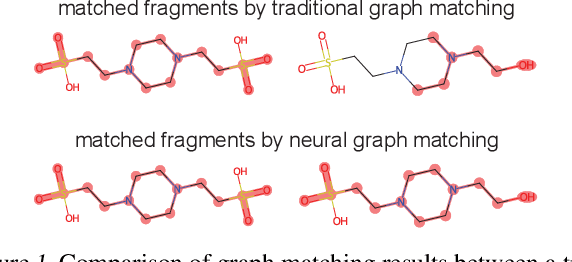
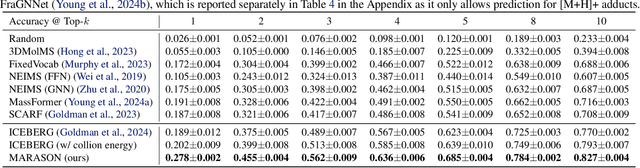
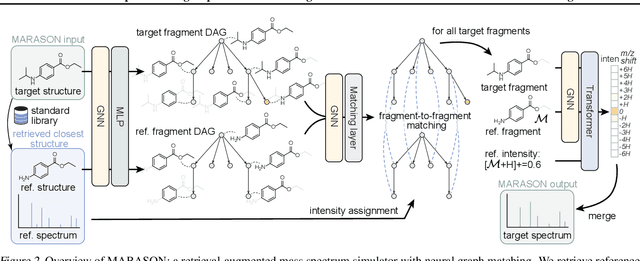
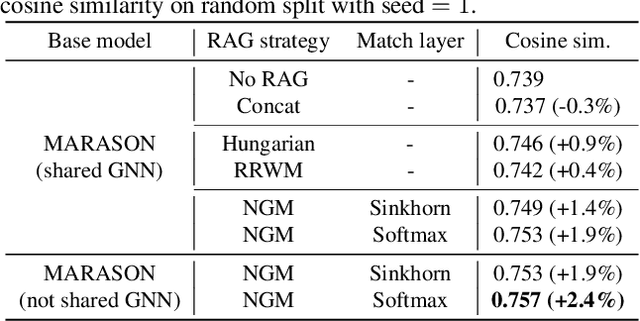
Molecular machine learning has gained popularity with the advancements of geometric deep learning. In parallel, retrieval-augmented generation has become a principled approach commonly used with language models. However, the optimal integration of retrieval augmentation into molecular machine learning remains unclear. Graph neural networks stand to benefit from clever matching to understand the structural alignment of retrieved molecules to a query molecule. Neural graph matching offers a compelling solution by explicitly modeling node and edge affinities between two structural graphs while employing a noise-robust, end-to-end neural network to learn affinity metrics. We apply this approach to mass spectrum simulation and introduce MARASON, a novel model that incorporates neural graph matching to enhance a fragmentation-based neural network. Experimental results highlight the effectiveness of our design, with MARASON achieving 28% top-1 accuracy, a substantial improvement over the non-retrieval state-of-the-art accuracy of 19%. Moreover, MARASON outperforms both naive retrieval-augmented generation methods and traditional graph matching approaches.
DiffMS: Diffusion Generation of Molecules Conditioned on Mass Spectra
Feb 13, 2025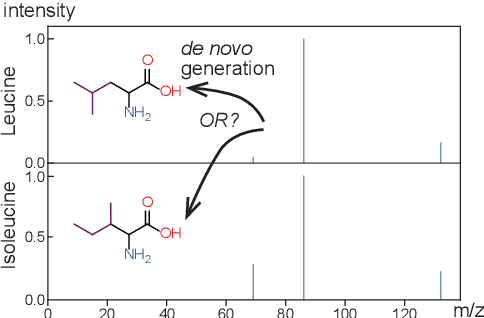
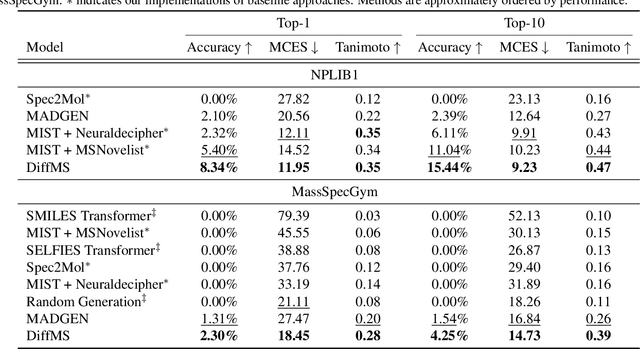
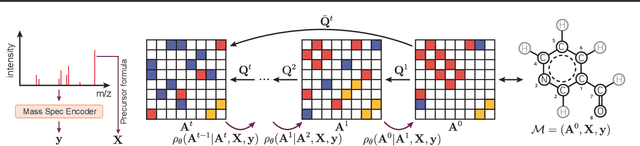
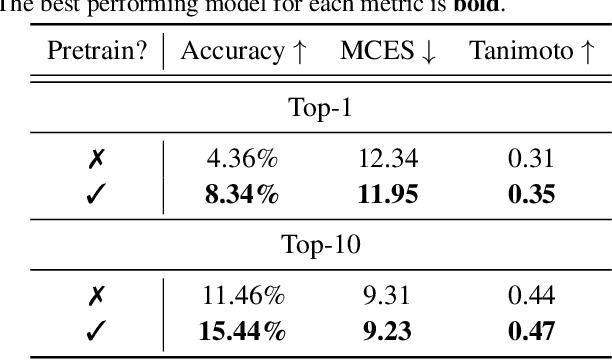
Mass spectrometry plays a fundamental role in elucidating the structures of unknown molecules and subsequent scientific discoveries. One formulation of the structure elucidation task is the conditional $\textit{de novo}$ generation of molecular structure given a mass spectrum. Toward a more accurate and efficient scientific discovery pipeline for small molecules, we present DiffMS, a formula-restricted encoder-decoder generative network that achieves state-of-the-art performance on this task. The encoder utilizes a transformer architecture and models mass spectra domain knowledge such as peak formulae and neutral losses, and the decoder is a discrete graph diffusion model restricted by the heavy-atom composition of a known chemical formula. To develop a robust decoder that bridges latent embeddings and molecular structures, we pretrain the diffusion decoder with fingerprint-structure pairs, which are available in virtually infinite quantities, compared to structure-spectrum pairs that number in the tens of thousands. Extensive experiments on established benchmarks show that DiffMS outperforms existing models on $\textit{de novo}$ molecule generation. We provide several ablations to demonstrate the effectiveness of our diffusion and pretraining approaches and show consistent performance scaling with increasing pretraining dataset size. DiffMS code is publicly available at https://github.com/coleygroup/DiffMS.
On the Expressive Power of Subgraph Graph Neural Networks for Graphs with Bounded Cycles
Feb 06, 2025



Graph neural networks (GNNs) have been widely used in graph-related contexts. It is known that the separation power of GNNs is equivalent to that of the Weisfeiler-Lehman (WL) test; hence, GNNs are imperfect at identifying all non-isomorphic graphs, which severely limits their expressive power. This work investigates $k$-hop subgraph GNNs that aggregate information from neighbors with distances up to $k$ and incorporate the subgraph structure. We prove that under appropriate assumptions, the $k$-hop subgraph GNNs can approximate any permutation-invariant/equivariant continuous function over graphs without cycles of length greater than $2k+1$ within any error tolerance. We also provide an extension to $k$-hop GNNs without incorporating the subgraph structure. Our numerical experiments on established benchmarks and novel architectures validate our theory on the relationship between the information aggregation distance and the cycle size.
Fast T2T: Optimization Consistency Speeds Up Diffusion-Based Training-to-Testing Solving for Combinatorial Optimization
Feb 05, 2025



Diffusion models have recently advanced Combinatorial Optimization (CO) as a powerful backbone for neural solvers. However, their iterative sampling process requiring denoising across multiple noise levels incurs substantial overhead. We propose to learn direct mappings from different noise levels to the optimal solution for a given instance, facilitating high-quality generation with minimal shots. This is achieved through an optimization consistency training protocol, which, for a given instance, minimizes the difference among samples originating from varying generative trajectories and time steps relative to the optimal solution. The proposed model enables fast single-step solution generation while retaining the option of multi-step sampling to trade for sampling quality, which offers a more effective and efficient alternative backbone for neural solvers. In addition, within the training-to-testing (T2T) framework, to bridge the gap between training on historical instances and solving new instances, we introduce a novel consistency-based gradient search scheme during the test stage, enabling more effective exploration of the solution space learned during training. It is achieved by updating the latent solution probabilities under objective gradient guidance during the alternation of noise injection and denoising steps. We refer to this model as Fast T2T. Extensive experiments on two popular tasks, the Traveling Salesman Problem (TSP) and Maximal Independent Set (MIS), demonstrate the superiority of Fast T2T regarding both solution quality and efficiency, even outperforming LKH given limited time budgets. Notably, Fast T2T with merely one-step generation and one-step gradient search can mostly outperform the SOTA diffusion-based counterparts that require hundreds of steps, while achieving tens of times speedup.
Batched Bayesian optimization with correlated candidate uncertainties
Oct 08, 2024



Batched Bayesian optimization (BO) can accelerate molecular design by efficiently identifying top-performing compounds from a large chemical library. Existing acquisition strategies for batch design in BO aim to balance exploration and exploitation. This often involves optimizing non-additive batch acquisition functions, necessitating approximation via myopic construction and/or diversity heuristics. In this work, we propose an acquisition strategy for discrete optimization that is motivated by pure exploitation, qPO (multipoint Probability of Optimality). qPO maximizes the probability that the batch includes the true optimum, which is expressible as the sum over individual acquisition scores and thereby circumvents the combinatorial challenge of optimizing a batch acquisition function. We differentiate the proposed strategy from parallel Thompson sampling and discuss how it implicitly captures diversity. Finally, we apply our method to the model-guided exploration of large chemical libraries and provide empirical evidence that it performs better than or on par with state-of-the-art methods in batched Bayesian optimization.
LinSATNet: The Positive Linear Satisfiability Neural Networks
Jul 18, 2024
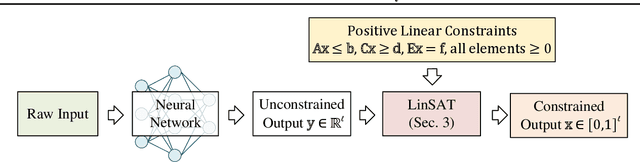
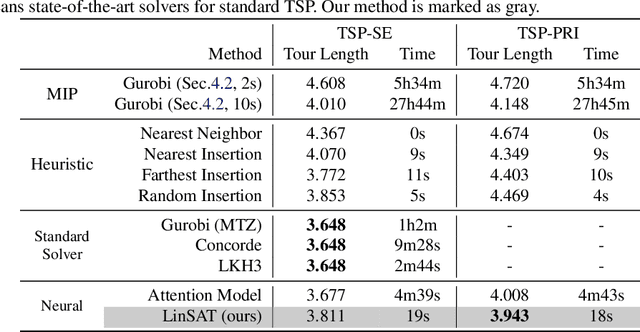
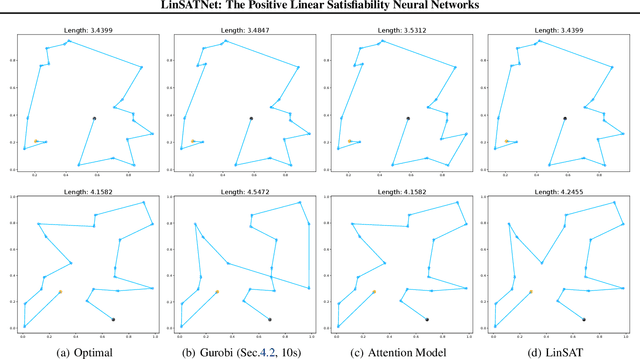
Encoding constraints into neural networks is attractive. This paper studies how to introduce the popular positive linear satisfiability to neural networks. We propose the first differentiable satisfiability layer based on an extension of the classic Sinkhorn algorithm for jointly encoding multiple sets of marginal distributions. We further theoretically characterize the convergence property of the Sinkhorn algorithm for multiple marginals. In contrast to the sequential decision e.g.\ reinforcement learning-based solvers, we showcase our technique in solving constrained (specifically satisfiability) problems by one-shot neural networks, including i) a neural routing solver learned without supervision of optimal solutions; ii) a partial graph matching network handling graphs with unmatchable outliers on both sides; iii) a predictive network for financial portfolios with continuous constraints. To our knowledge, there exists no one-shot neural solver for these scenarios when they are formulated as satisfiability problems. Source code is available at https://github.com/Thinklab-SJTU/LinSATNet
Double-Ended Synthesis Planning with Goal-Constrained Bidirectional Search
Jul 08, 2024



Computer-aided synthesis planning (CASP) algorithms have demonstrated expert-level abilities in planning retrosynthetic routes to molecules of low to moderate complexity. However, current search methods assume the sufficiency of reaching arbitrary building blocks, failing to address the common real-world constraint where using specific molecules is desired. To this end, we present a formulation of synthesis planning with starting material constraints. Under this formulation, we propose Double-Ended Synthesis Planning (DESP), a novel CASP algorithm under a bidirectional graph search scheme that interleaves expansions from the target and from the goal starting materials to ensure constraint satisfiability. The search algorithm is guided by a goal-conditioned cost network learned offline from a partially observed hypergraph of valid chemical reactions. We demonstrate the utility of DESP in improving solve rates and reducing the number of search expansions by biasing synthesis planning towards expert goals on multiple new benchmarks. DESP can make use of existing one-step retrosynthesis models, and we anticipate its performance to scale as these one-step model capabilities improve.
Rethinking and Benchmarking Predict-then-Optimize Paradigm for Combinatorial Optimization Problems
Nov 19, 2023



Numerous web applications rely on solving combinatorial optimization problems, such as energy cost-aware scheduling, budget allocation on web advertising, and graph matching on social networks. However, many optimization problems involve unknown coefficients, and improper predictions of these factors may lead to inferior decisions which may cause energy wastage, inefficient resource allocation, inappropriate matching in social networks, etc. Such a research topic is referred to as "Predict-Then-Optimize (PTO)" which considers the performance of prediction and decision-making in a unified system. A noteworthy recent development is the end-to-end methods by directly optimizing the ultimate decision quality which claims to yield better results in contrast to the traditional two-stage approach. However, the evaluation benchmarks in this field are fragmented and the effectiveness of various models in different scenarios remains unclear, hindering the comprehensive assessment and fast deployment of these methods. To address these issues, we provide a comprehensive categorization of current approaches and integrate existing experimental scenarios to establish a unified benchmark, elucidating the circumstances under which end-to-end training yields improvements, as well as the contexts in which it performs ineffectively. We also introduce a new dataset for the industrial combinatorial advertising problem for inclusive finance to open-source. We hope the rethinking and benchmarking of PTO could facilitate more convenient evaluation and deployment, and inspire further improvements both in the academy and industry within this field.
GMTR: Graph Matching Transformers
Nov 14, 2023
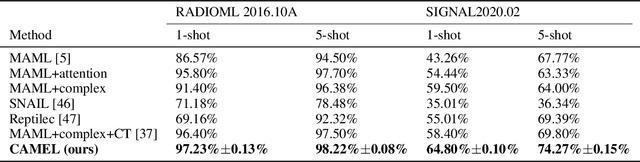

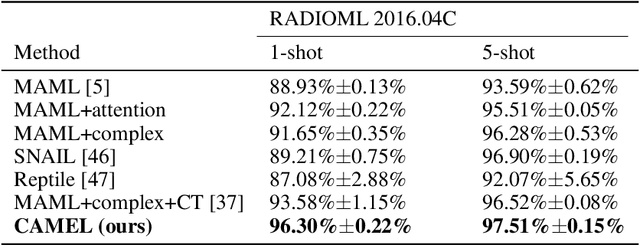
Vision transformers (ViTs) have recently been used for visual matching beyond object detection and segmentation. However, the original grid dividing strategy of ViTs neglects the spatial information of the keypoints, limiting the sensitivity to local information. Therefore, we propose \textbf{QueryTrans} (Query Transformer), which adopts a cross-attention module and keypoints-based center crop strategy for better spatial information extraction. We further integrate the graph attention module and devise a transformer-based graph matching approach \textbf{GMTR} (Graph Matching TRansformers) whereby the combinatorial nature of GM is addressed by a graph transformer neural GM solver. On standard GM benchmarks, GMTR shows competitive performance against the SOTA frameworks. Specifically, on Pascal VOC, GMTR achieves $\mathbf{83.6\%}$ accuracy, $\mathbf{0.9\%}$ higher than the SOTA framework. On Spair-71k, GMTR shows great potential and outperforms most of the previous works. Meanwhile, on Pascal VOC, QueryTrans improves the accuracy of NGMv2 from $80.1\%$ to $\mathbf{83.3\%}$, and BBGM from $79.0\%$ to $\mathbf{84.5\%}$. On Spair-71k, QueryTrans improves NGMv2 from $80.6\%$ to $\mathbf{82.5\%}$, and BBGM from $82.1\%$ to $\mathbf{83.9\%}$. Source code will be made publicly available.
Rethinking Cross-Domain Sequential Recommendation under Open-World Assumptions
Nov 08, 2023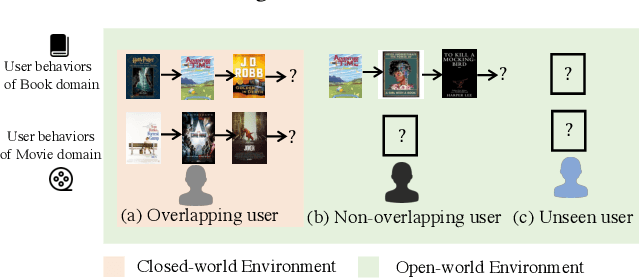
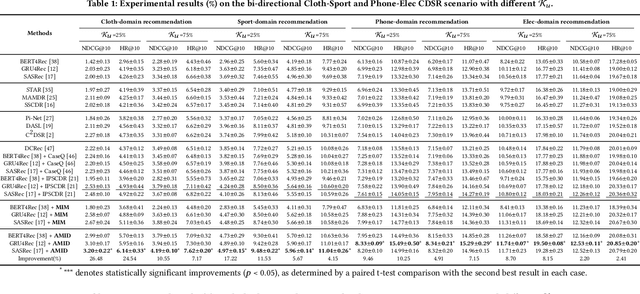
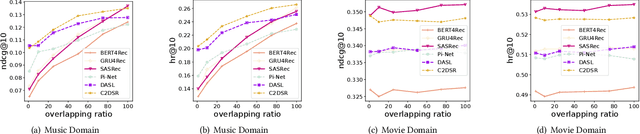
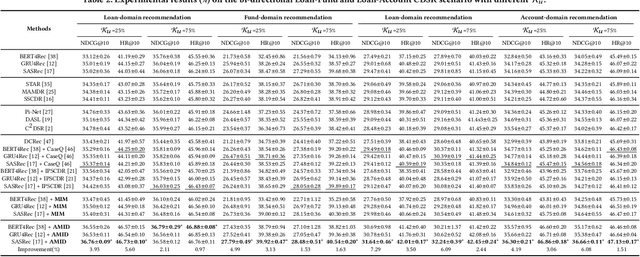
Cross-Domain Sequential Recommendation (CDSR) methods aim to tackle the data sparsity and cold-start problems present in Single-Domain Sequential Recommendation (SDSR). Existing CDSR works design their elaborate structures relying on overlapping users to propagate the cross-domain information. However, current CDSR methods make closed-world assumptions, assuming fully overlapping users across multiple domains and that the data distribution remains unchanged from the training environment to the test environment. As a result, these methods typically result in lower performance on online real-world platforms due to the data distribution shifts. To address these challenges under open-world assumptions, we design an \textbf{A}daptive \textbf{M}ulti-\textbf{I}nterest \textbf{D}ebiasing framework for cross-domain sequential recommendation (\textbf{AMID}), which consists of a multi-interest information module (\textbf{MIM}) and a doubly robust estimator (\textbf{DRE}). Our framework is adaptive for open-world environments and can improve the model of most off-the-shelf single-domain sequential backbone models for CDSR. Our MIM establishes interest groups that consider both overlapping and non-overlapping users, allowing us to effectively explore user intent and explicit interest. To alleviate biases across multiple domains, we developed the DRE for the CDSR methods. We also provide a theoretical analysis that demonstrates the superiority of our proposed estimator in terms of bias and tail bound, compared to the IPS estimator used in previous work.