 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMixer: A Unified Architecture for Scaling Laws in Recommendation Systems
Apr 02, 2026In recent years, the scaling laws of recommendation models have attracted increasing attention, which govern the relationship between performance and parameters/FLOPs of recommenders. Currently, there are three mainstream architectures for achieving scaling in recommendation models, namely attention-based, TokenMixer-based, and factorization-machine-based methods, which exhibit fundamental differences in both design philosophy and architectural structure. In this paper, we propose a unified scaling architecture for recommendation systems, namely \textbf{UniMixer}, to improve scaling efficiency and establish a unified theoretical framework that unifies the mainstream scaling blocks. By transforming the rule-based TokenMixer to an equivalent parameterized structure, we construct a generalized parameterized feature mixing module that allows the token mixing patterns to be optimized and learned during model training. Meanwhile, the generalized parameterized token mixing removes the constraint in TokenMixer that requires the number of heads to be equal to the number of tokens. Furthermore, we establish a unified scaling module design framework for recommender systems, which bridges the connections among attention-based, TokenMixer-based, and factorization-machine-based methods. To further boost scaling ROI, a lightweight UniMixing module is designed, \textbf{UniMixing-Lite}, which further compresses the model parameters and computational cost while significantly improve the model performance. The scaling curves are shown in the following figure. Extensive offline and online experiments are conducted to verify the superior scaling abilities of \textbf{UniMixer}.
PushGen: Push Notifications Generation with LLM
Dec 16, 2025
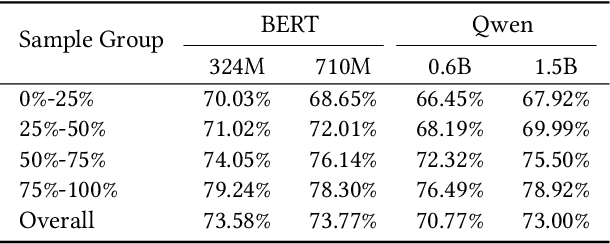
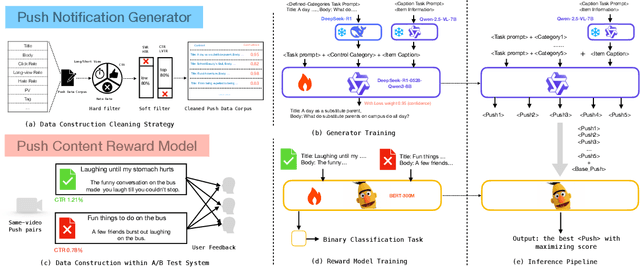

We present PushGen, an automated framework for generating high-quality push notifications comparable to human-crafted content. With the rise of generative models, there is growing interest in leveraging LLMs for push content generation. Although LLMs make content generation straightforward and cost-effective, maintaining stylistic control and reliable quality assessment remains challenging, as both directly impact user engagement. To address these issues, PushGen combines two key components: (1) a controllable category prompt technique to guide LLM outputs toward desired styles, and (2) a reward model that ranks and selects generated candidates. Extensive offline and online experiments demonstrate its effectiveness, which has been deployed in large-scale industrial applications, serving hundreds of millions of users daily.
Selection and Exploitation of High-Quality Knowledge from Large Language Models for Recommendation
Aug 10, 2025In recent years, there has been growing interest in leveraging the impressive generalization capabilities and reasoning ability of large language models (LLMs) to improve the performance of recommenders. With this operation, recommenders can access and learn the additional world knowledge and reasoning information via LLMs. However, in general, for different users and items, the world knowledge derived from LLMs suffers from issues of hallucination, content redundant, and information homogenization. Directly feeding the generated response embeddings into the recommendation model can lead to unavoidable performance deterioration. To address these challenges, we propose a Knowledge Selection \& Exploitation Recommendation (KSER) framework, which effectively select and extracts the high-quality knowledge from LLMs. The framework consists of two key components: a knowledge filtering module and a embedding spaces alignment module. In the knowledge filtering module, a Embedding Selection Filter Network (ESFNet) is designed to assign adaptive weights to different knowledge chunks in different knowledge fields. In the space alignment module, an attention-based architecture is proposed to align the semantic embeddings from LLMs with the feature space used to train the recommendation models. In addition, two training strategies--\textbf{all-parameters training} and \textbf{extractor-only training}--are proposed to flexibly adapt to different downstream tasks and application scenarios, where the extractor-only training strategy offers a novel perspective on knowledge-augmented recommendation. Experimental results validate the necessity and effectiveness of both the knowledge filtering and alignment modules, and further demonstrate the efficiency and effectiveness of the extractor-only training strategy.
Information Maximization via Variational Autoencoders for Cross-Domain Recommendation
May 31, 2024



Cross-Domain Sequential Recommendation (CDSR) methods aim to address the data sparsity and cold-start problems present in Single-Domain Sequential Recommendation (SDSR). Existing CDSR methods typically rely on overlapping users, designing complex cross-domain modules to capture users' latent interests that can propagate across different domains. However, their propagated informative information is limited to the overlapping users and the users who have rich historical behavior records. As a result, these methods often underperform in real-world scenarios, where most users are non-overlapping (cold-start) and long-tailed. In this research, we introduce a new CDSR framework named Information Maximization Variational Autoencoder (\textbf{\texttt{IM-VAE}}). Here, we suggest using a Pseudo-Sequence Generator to enhance the user's interaction history input for downstream fine-grained CDSR models to alleviate the cold-start issues. We also propose a Generative Recommendation Framework combined with three regularizers inspired by the mutual information maximization (MIM) theory \cite{mcgill1954multivariate} to capture the semantic differences between a user's interests shared across domains and those specific to certain domains, as well as address the informational gap between a user's actual interaction sequences and the pseudo-sequences generated. To the best of our knowledge, this paper is the first CDSR work that considers the information disentanglement and denoising of pseudo-sequences in the open-world recommendation scenario. Empirical experiments illustrate that \texttt{IM-VAE} outperforms the state-of-the-art approaches on two real-world cross-domain datasets on all sorts of users, including cold-start and tailed users, demonstrating the effectiveness of \texttt{IM-VAE} in open-world recommendation.
SLMRec: Empowering Small Language Models for Sequential Recommendation
May 28, 2024



The sequential Recommendation (SR) task involves predicting the next item a user is likely to interact with, given their past interactions. The SR models examine the sequence of a user's actions to discern more complex behavioral patterns and temporal dynamics. Recent research demonstrates the great impact of LLMs on sequential recommendation systems, either viewing sequential recommendation as language modeling or serving as the backbone for user representation. Although these methods deliver outstanding performance, there is scant evidence of the necessity of a large language model and how large the language model is needed, especially in the sequential recommendation scene. Meanwhile, due to the huge size of LLMs, it is inefficient and impractical to apply a LLM-based model in real-world platforms that often need to process billions of traffic logs daily. In this paper, we explore the influence of LLMs' depth by conducting extensive experiments on large-scale industry datasets. Surprisingly, we discover that most intermediate layers of LLMs are redundant. Motivated by this insight, we empower small language models for SR, namely SLMRec, which adopt a simple yet effective knowledge distillation method. Moreover, SLMRec is orthogonal to other post-training efficiency techniques, such as quantization and pruning, so that they can be leveraged in combination. Comprehensive experimental results illustrate that the proposed SLMRec model attains the best performance using only 13% of the parameters found in LLM-based recommendation models, while simultaneously achieving up to 6.6x and 8.0x speedups in training and inference time costs, respectively.
Fine-Grained Dynamic Framework for Bias-Variance Joint Optimization on Data Missing Not at Random
May 24, 2024



In most practical applications such as recommendation systems, display advertising, and so forth, the collected data often contains missing values and those missing values are generally missing-not-at-random, which deteriorates the prediction performance of models. Some existing estimators and regularizers attempt to achieve unbiased estimation to improve the predictive performance. However, variances and generalization bound of these methods are generally unbounded when the propensity scores tend to zero, compromising their stability and robustness. In this paper, we first theoretically reveal that limitations of regularization techniques. Besides, we further illustrate that, for more general estimators, unbiasedness will inevitably lead to unbounded variance. These general laws inspire us that the estimator designs is not merely about eliminating bias, reducing variance, or simply achieve a bias-variance trade-off. Instead, it involves a quantitative joint optimization of bias and variance. Then, we develop a systematic fine-grained dynamic learning framework to jointly optimize bias and variance, which adaptively selects an appropriate estimator for each user-item pair according to the predefined objective function. With this operation, the generalization bounds and variances of models are reduced and bounded with theoretical guarantees. Extensive experiments are conducted to verify the theoretical results and the effectiveness of the proposed dynamic learning framework.
Integrating Large Language Models with Graphical Session-Based Recommendation
Feb 26, 2024

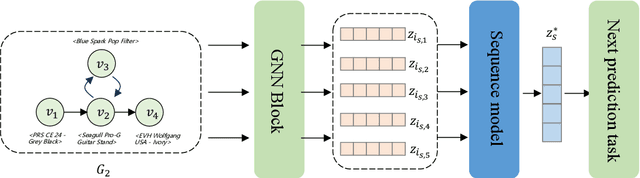
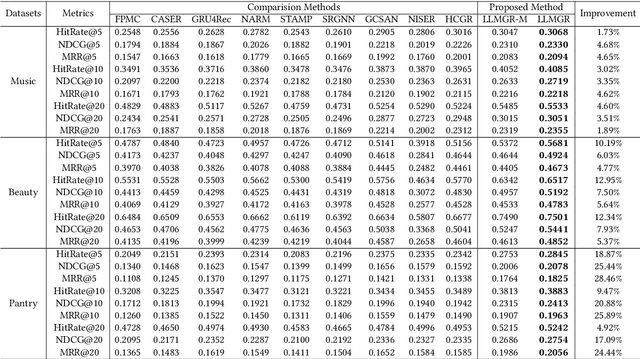
With the rapid development of Large Language Models (LLMs), various explorations have arisen to utilize LLMs capability of context understanding on recommender systems. While pioneering strategies have primarily transformed traditional recommendation tasks into challenges of natural language generation, there has been a relative scarcity of exploration in the domain of session-based recommendation (SBR) due to its specificity. SBR has been primarily dominated by Graph Neural Networks, which have achieved many successful outcomes due to their ability to capture both the implicit and explicit relationships between adjacent behaviors. The structural nature of graphs contrasts with the essence of natural language, posing a significant adaptation gap for LLMs. In this paper, we introduce large language models with graphical Session-Based recommendation, named LLMGR, an effective framework that bridges the aforementioned gap by harmoniously integrating LLMs with Graph Neural Networks (GNNs) for SBR tasks. This integration seeks to leverage the complementary strengths of LLMs in natural language understanding and GNNs in relational data processing, leading to a more powerful session-based recommender system that can understand and recommend items within a session. Moreover, to endow the LLM with the capability to empower SBR tasks, we design a series of prompts for both auxiliary and major instruction tuning tasks. These prompts are crafted to assist the LLM in understanding graph-structured data and align textual information with nodes, effectively translating nuanced user interactions into a format that can be understood and utilized by LLM architectures. Extensive experiments on three real-world datasets demonstrate that LLMGR outperforms several competitive baselines, indicating its effectiveness in enhancing SBR tasks and its potential as a research direction for future exploration.
Towards Open-world Cross-Domain Sequential Recommendation: A Model-Agnostic Contrastive Denoising Approach
Nov 23, 2023



Cross-domain sequential recommendation (CDSR) aims to address the data sparsity problems that exist in traditional sequential recommendation (SR) systems. The existing approaches aim to design a specific cross-domain unit that can transfer and propagate information across multiple domains by relying on overlapping users with abundant behaviors. However, in real-world recommender systems, CDSR scenarios usually consist of a majority of long-tailed users with sparse behaviors and cold-start users who only exist in one domain. This leads to a drop in the performance of existing CDSR methods in the real-world industry platform. Therefore, improving the consistency and effectiveness of models in open-world CDSR scenarios is crucial for constructing CDSR models (\textit{1st} CH). Recently, some SR approaches have utilized auxiliary behaviors to complement the information for long-tailed users. However, these multi-behavior SR methods cannot deliver promising performance in CDSR, as they overlook the semantic gap between target and auxiliary behaviors, as well as user interest deviation across domains (\textit{2nd} CH).
Rethinking Cross-Domain Sequential Recommendation under Open-World Assumptions
Nov 08, 2023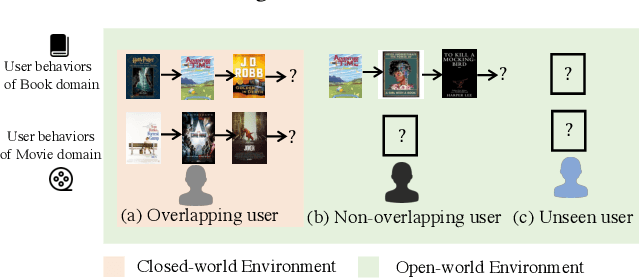
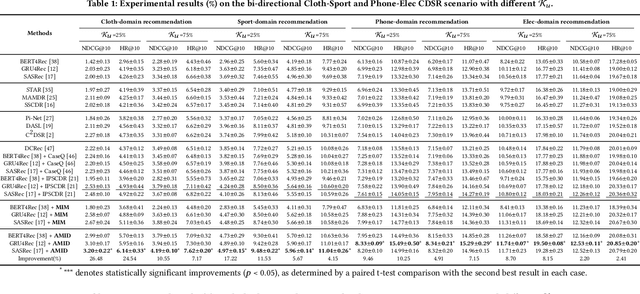
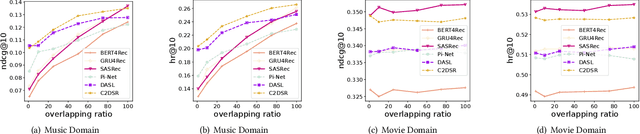
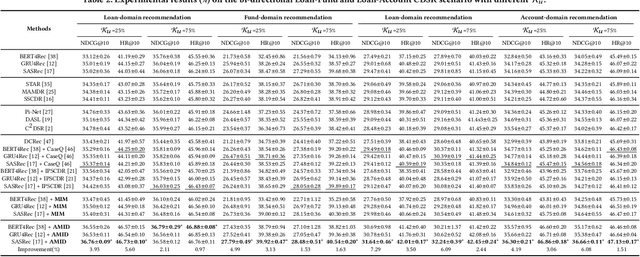
Cross-Domain Sequential Recommendation (CDSR) methods aim to tackle the data sparsity and cold-start problems present in Single-Domain Sequential Recommendation (SDSR). Existing CDSR works design their elaborate structures relying on overlapping users to propagate the cross-domain information. However, current CDSR methods make closed-world assumptions, assuming fully overlapping users across multiple domains and that the data distribution remains unchanged from the training environment to the test environment. As a result, these methods typically result in lower performance on online real-world platforms due to the data distribution shifts. To address these challenges under open-world assumptions, we design an \textbf{A}daptive \textbf{M}ulti-\textbf{I}nterest \textbf{D}ebiasing framework for cross-domain sequential recommendation (\textbf{AMID}), which consists of a multi-interest information module (\textbf{MIM}) and a doubly robust estimator (\textbf{DRE}). Our framework is adaptive for open-world environments and can improve the model of most off-the-shelf single-domain sequential backbone models for CDSR. Our MIM establishes interest groups that consider both overlapping and non-overlapping users, allowing us to effectively explore user intent and explicit interest. To alleviate biases across multiple domains, we developed the DRE for the CDSR methods. We also provide a theoretical analysis that demonstrates the superiority of our proposed estimator in terms of bias and tail bound, compared to the IPS estimator used in previous work.
Neural Node Matching for Multi-Target Cross Domain Recommendation
Feb 12, 2023



Multi-Target Cross Domain Recommendation(CDR) has attracted a surge of interest recently, which intends to improve the recommendation performance in multiple domains (or systems) simultaneously. Most existing multi-target CDR frameworks primarily rely on the existence of the majority of overlapped users across domains. However, general practical CDR scenarios cannot meet the strictly overlapping requirements and only share a small margin of common users across domains}. Additionally, the majority of users have quite a few historical behaviors in such small-overlapping CDR scenarios}. To tackle the aforementioned issues, we propose a simple-yet-effective neural node matching based framework for more general CDR settings, i.e., only (few) partially overlapped users exist across domains and most overlapped as well as non-overlapped users do have sparse interactions. The present framework} mainly contains two modules: (i) intra-to-inter node matching module, and (ii) intra node complementing module. Concretely, the first module conducts intra-knowledge fusion within each domain and subsequent inter-knowledge fusion across domains by fully connected user-user homogeneous graph information aggregating.
* 13pages